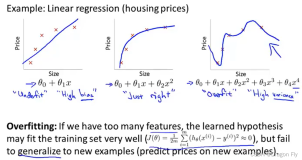
正则化
2017-06-09
1304
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:

目录
相关文章
|
2月前
|
机器学习/深度学习
Python
|
3月前
|
机器学习/深度学习
算法
XGBoost中正则化的9个超参数
本文探讨了XGBoost中多种正则化方法及其重要性,旨在通过防止过拟合来提升模型性能。文章首先强调了XGBoost作为一种高效算法在机器学习任务中的应用价值,并指出正则化对于缓解过拟合问题的关键作用,具体包括降低模型复杂度、改善泛化能力和防止模型过度适应训练数据。随后,文章详细介绍了四种正则化方法:减少估计器数量(如使用`early_stopping_rounds`)、使用更简单的树(如调整`gamma`和`max_depth`)、采样(如设置`subsample`和`colsample`)以及收缩(如调节`learning_rate`, `lambda`和`alpha`)。
52
0
0

|
3月前
|
机器学习/深度学习
|
4月前
|
机器学习/深度学习
|
5月前
|
机器学习/深度学习
算法
|
机器学习/深度学习
自然语言处理
正则化
机器学习中的正则化(regularization)是一种常用的方法,用于防止模型过拟合(overfitting)。过拟合是指模型在训练集上表现很好,但在测试集或新数据上表现较差的情况。正则化通过在模型的目标函数中加入一个惩罚项(penalty term),来对模型的复杂度进行限制,从而避免模型在训练集上过于拟合。
80
0
0
|
机器学习/深度学习
Python

|
机器学习/深度学习
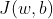
|
机器学习/深度学习
人工智能
算法
|
机器学习/深度学习
算法