
App Discovery with Google Play, Part 1: Understanding Topics
Tuesday, November 08, 2016
Every month, more than a billion users come to Google Play to download apps for their mobile devices. While some are looking for specific apps, like Snapchat, others come with only a broad notion of what they are interested in, like “ horror games” or “ selfie apps”. These broad searches by topic represent nearly half of the queries in Play Store, so it’s critical to find the most relevant apps.
Searches by topic require more than simply indexing apps by query terms; they require an understanding of the topics associated with an app. Machine learning approaches have been applied to similar problems, but success heavily depends on the number of training examples to learn about a topic. While for some popular topics such as “ social networking” we had many labeled apps to learn from, the majority of topics had only a handful of examples. Our challenge was to learn from a very limited number of training examples and scale to millions of apps across thousands of topics, forcing us to adapt our machine learning techniques.
Our initial attempt was to build a deep neural network (DNN) trained to predict topics for an app based on words and phrases from the app title and description. For example, if the app description mentioned “ frightening”, “ very scary”, and “ fear” then associate the “ horror game” topic with it. However, given the learning capacity of DNNs, it completely “memorized” the topics for the apps in our small training data and failed to generalize to new apps it hadn’t seen before.
To generalize effectively, we needed a much larger dataset to train on, so we turned to how people learn as inspiration. In contrast to DNNs, human beings need much less training data. For example, you would likely need to see very few “ horror game” app descriptions before learning how to generalize and associate new apps to that genre. Just by knowing the language describing the apps, people can correctly infer topics from even a few examples.
To emulate this, we tried a very rough approximation of this language-centric learning. We trained a neural network to learn how language was used to describe apps. We built a Skip-gram model, where the neural network attempts to predict the words around a given word, for example “ share” given “ photo”. The neural network encodes its knowledge as vectors of floating point numbers, referred to as embeddings. These embeddings were used to train another model called a classifier, capable of distinguishing which topics applied to an app. We now needed much less training data to learn about app topics, due to the large amount of learning already done with Skip-gram.
While this architecture generalized well for popular topics like “ social networking”, we ran into a new problem for more niche topics like “ selfie”. The single classifier built to predict all the topics together focused most of its learning on the popular topics, ignoring the errors it made on the less common ones. To solve this problem we built a separate classifier for each topic and tuned them in isolation.
This architecture produced reasonable results, but would still sometimes overgeneralize. For instance, it might associate Facebook with “ dating” or Plants vs Zombies with “ educational games”. To produce more precise classifiers, we needed higher volume and quality of training data. We treated the system described above as a coarse classifier that pruned down every possible {app, topic} pair, numbering in billions, to a more manageable list of {app, topic} pairs of interest. We built a pipeline to have human raters evaluate the classifier output and fed consensus results back as training data. This process allowed us to bootstrap from our existing system, giving us a path to steadily improve classifier performance.

To evaluate {app, topic} pairs by human raters, we asked them questions of the form, “ To what extent is topic X related to app Y?” Multiple raters received the same question and independently selected answers on a rating scale to indicate if the topic was “important” for the app, “somewhat related”, or completely “off-topic”. Our initial evaluations showed a high level of disagreement amongst the raters. Diving deeper, we identified several causes of disagreement: vague guidelines for answer selection, insufficient rater training, evaluating broad topics like “ computer files” and “ game physics” that applied to most apps or games. Tackling these issues led to significant gains in rater agreement. Asking raters to choose an explicit reason for their answer from a curated list further improved reliability. Despite the improvements, we sometimes still have to “agree to disagree” and currently discard answers where raters fail to reach consensus.
These app topic classifiers enable search and discovery features in the Google Play Apps store. The current system helps provide relevant results to our users, but we are constantly exploring new ways to improve the system, through additional signals, architectural improvements and new algorithms. In Part 2 of this series, we will discuss how to personalize the app discovery experience for users.
Acknowledgments
This work was done within the Google Play team in close collaboration with Liadan O'Callaghan, Yuhua Zhu, Mark Taylor and Michael Watson.
App Discovery with Google Play, Part 2: Personalized Recommendations with Related Apps
Wednesday, December 14, 2016
In Part 1 of this series on app discovery, we discussed using machine learning to gain a deeper understanding of the topics associated with an app, in order to provide a better search and discovery experience on the Google Play Apps Store. In this post, we discuss a deep learning framework to provide personalized recommendations to users based on their previous app downloads and the context in which they are used.
Providing useful and relevant app recommendations to visitors of the Google Play Apps Store is a key goal of our apps discovery team. An understanding of the topics associated with an app, however, is only one part of creating a system that best serves the user. In order to create a better overall experience, one must also take into account the tastes of the user and provide personalized recommendations. If one didn’t, the “You might also like” recommendation would look the same for everyone!
Discovering these nuances requires both an understanding what an app does, and also the context of the app with respect to the user. For example, to an avid sci-fi gamer, similar game recommendations may be of interest, but if a user installs a fitness app, recommending a health recipe app may be more relevant than five more fitness apps. As users may be more interested in downloading an app or game that complements one they already have installed, we provide recommendations based on app relatedness with each other (“You might also like”), in addition to providing recommendations based on the topic associated with an app (“Similar apps”).
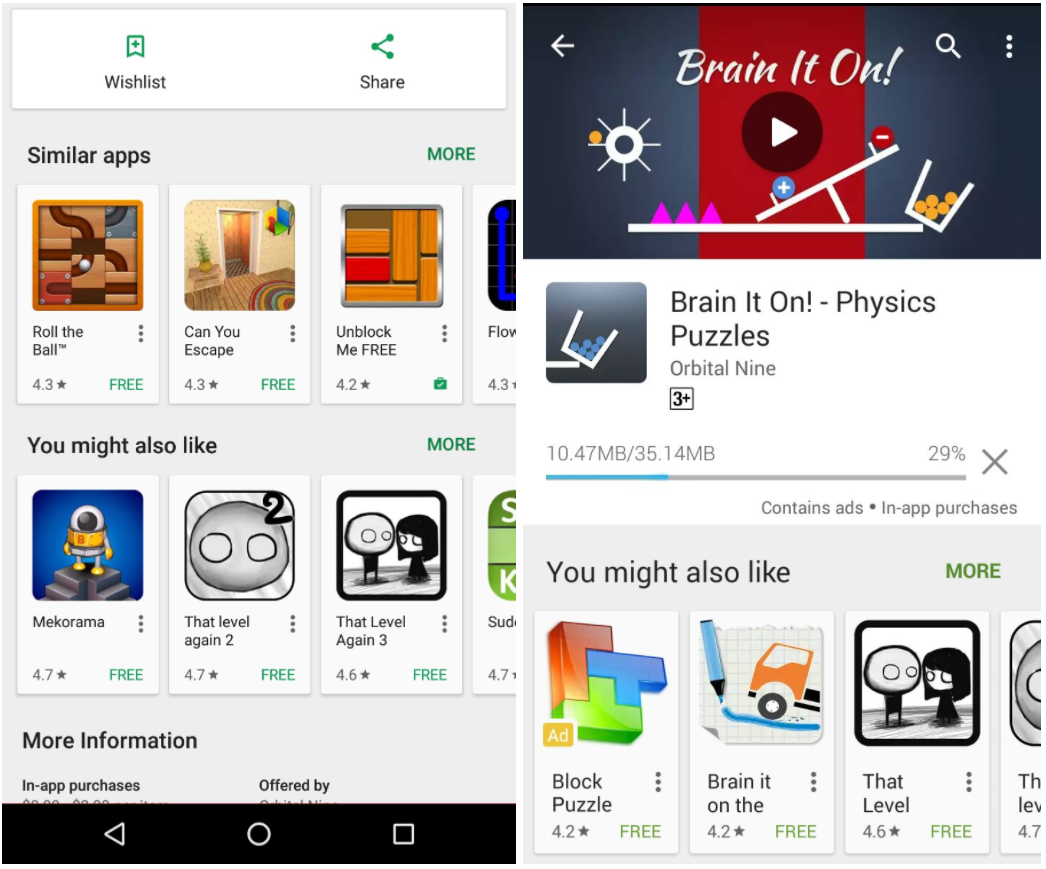 |
| Suggestions of similar apps and apps that you also might like shown both before making an install decision (left) and while the current install is in progress (right). |
One particularly strong contextual signal is app relatedness, based on previous installs and search query clicks. As an example, a user who has searched for and plays a lot of graphics-heavy games likely has a preference for apps which are also graphically intense rather than apps with simpler graphics. So, when this user installs a car racing game, the “You might also like” suggestions includes apps which relate to the “seed” app (because they are graphically intense racing games) ranked higher than racing apps with simpler graphics. This allows for a finer level of personalization where the characteristics of the apps are matched with the preferences of the user.
To incorporate this app relatedness in our recommendations, we take a two pronged approach: (a) offline candidate generation i.e. the generation of the potential related apps that other users have downloaded, in addition to the app in question, and (b) online personalized re-ranking, where we re-rank these candidates using a personalized ML model.
Offline Candidate Generation
The problem of finding related apps can be formulated as a nearest neighbor search problem. Given an app X, we want to find the k nearest apps. In the case of “you might also like”, a naive approach would be one based on counting, where if many people installed apps X and Y, then the app Y would be used as candidate for seed app X. However, this approach is intractable as it is difficult to learn and generalize effectively in the huge problem space. Given that there are over a million apps on Google Play, the total number of possible app pairs is over ~10 12.
To solve this, we trained a deep neural network to predict the next app installed by the user given their previous installs. Output embeddings at the final layer of this deep neural network generally represents the types of apps a given user has installed. We then apply the nearest neighbor algorithm to find related apps for a given seed app in the trained embedding space. Thus, we perform dimensionality reduction by representing apps using embeddings to help prune the space of potential candidates.
Online Personalized Re-ranking
The candidates generated in the previous step represent relatedness along multiple dimensions. The objective is to assign scores to the candidates so they can be re-ranked in a personalized way, in order to provide an experience that is crafted to the user’s overall interests and yet maintain relevance for the user installing a given app. In order to do this, we take the characteristics of the app candidates as input to a separate deep neural network, which is then trained with real-time with user specific context features (region, language, app store search queries, etc.) to predict the likelihood of a related app being specifically relevant to the user.
 |
| Architecture for personalized related apps |
One of the takeaways from this work is that re-ranking content, like related apps, is one of the critical ways of app discovery in the store, and can bring great value to the user without impacting perceived relevance. Compared to the control (where no re-ranking was done), we saw a 20% increase in the app install rate from the “You might also like” suggestions. This had no user perceivable change in latency.
In Part 3 of this series, we will discuss how we employ machine learning to keep bad actors who try to manipulate the signals we use for search and personalization at bay.
Acknowledgements
This work was done within the Google Play team in collaboration with Halit Erdogan, Mark Taylor, Michael Watson, Huazhong Ning, Stan Bileschi, John Kraemer, and Chuan Yu Foo.
App Discovery with Google Play, Part 3: Machine Learning to Fight Spam and Abuse at Scale
Monday, January 30, 2017
In Part 1 and Part 2 of this series on app discovery, we discussed using machine learning to gain a deeper understanding of the topics associated with an app, and a deep learning framework to provide personalized recommendations. In this post, we discuss a machine learning approach to fight spam and abuse on apps section of the Google Play Store, making it a safe and trusted app platform for more than a billion Android users.
With apps becoming an increasingly important part of people’s professional and personal lives, we realize that it is critical to make sure that 1) the apps found on Google Play are safe, and 2) the information presented to you about the apps is both authentic and unbiased. With more than 1 million apps in our catalog, and a significant number of new apps introduced everyday, we needed to develop scalable methods to identify bad actors accurately and swiftly. To tackle this problem, we take a two-pronged approach, both employing various machine learning techniques to help fight against spam and abuse at scale.
Identifying and blocking ‘bad’ apps from entering Google Play platform
As mentioned in Google Play Developer Policy, we don’t allow listing of malicious, offensive, or illegal apps. Despite such policy, there are always a small number of bad actors who attempt to publish apps that prey on users. Finding the apps that violate our policy among the vast app catalog is not a trivial problem, especially when there are tens of thousands of apps being submitted each day. This is why we embraced machine learning techniques in assessing policy violations and potential risks an app may pose to its potential users.
We use various techniques such as text analysis with word embedding with large probabilistic networks, image understanding with Google Brain, and static and dynamic analysis of the APK binary. These individual techniques are aimed to detect specific violations (e.g., restricted content, privacy and security, intellectual property, user deception), in a more systematic and reliable way compared to manual reviews. Apps that are flagged by our algorithms either gets sent back to the developers for addressing the detected issues, or are ‘quarantined’ until we can verify its safety and/or clears it of potential violations. Because of this app review process combining analyses by human experts and algorithms, developers can take necessary actions (e.g., iterate or publish) within a few hours of app submission.
 |
| Visualization of word embedding of samples of offensive content policy violating apps (red dots) and policy compliant apps (green dots), visualized with t-SNE (t-Distributed Stochastic Neighbor Embedding). |
Preventing manipulation of app ratings and rankings
While an app may itself be legitimate, some bad actors may attempt to create fake engagements in order to manipulate an app’s ratings and rankings. In order to provide our users with an accurate reflection of the app’s perceived quality, we work to nullify these attempts. However, as we place countermeasures against these efforts, the actors behind the manipulation attempts change and adapt their behaviors to bypass our countermeasures thereby presenting us with an adversarial problem.
As such, instead of using a conventional supervised learning approach (as we did in the ‘ Part 1’ or ‘ Part 2’ of this series, which are more ‘stationary’ problems), we needed to develop a repeatable process that allowed us the same (if not more) agility that bad actors have. We achieved this by using a hybrid strategy that utilizes unsupervised learning techniques to generate training data which in turn feeds into a model built on traditional supervised learning techniques.
Utilizing data on interactions, transactions, and behaviors occurring on the Google Play platform, we apply anomaly detection techniques to identify apps that are targeted by fake engagements. For example, a suspected app may have all its engagement originating from a single data center, whereas an app with organic engagement will have its engagement originating from a healthy distribution of sources.
We then use these apps to isolate actors who collude or orchestrate to manipulate ratings and rankings, who in turn are used as training data to build a model that identifies similar actors. This model, built using supervised learning techniques, is then used to expand coverage and nullify fake engagements across Google Play Apps platform.
 |
| A visualization of how a model trained on known bad actors (red) expands coverage to detect similar bad actors (orange) while ignoring organic users (blue). |
We strive to make Google Play the best platform for both developers and users, by enabling fast publication while not compromising user safety. The machine learning capabilities mentioned above helped us achieve both, and we’ll continue to innovate on these techniques to ensure we keep our users safe from spam and abuse.
Acknowledgements
This work was done in close collaboration with Yang Zhang, Zhikun Wang, Gengxin Miao, Liam MacDermed, Dev Manuel, Daniel Peddity, Yi Li, Kazushi Nagayama, Sid Chahar, and Xinyu Cheng.
