
NVelocity错误 Unable to find resource
Unable to find resource ''XXXXX
说明: 执行当前 Web 请求期间,出现未处理的异常。请检查堆栈跟踪信息,以了解有关该错误以及代码中导致错误的出处的详细信息。异常详细信息: NVelocity.Exception.ResourceNotFoundException: Unable to find resource 'XXXXt.htm'
源错误:
行 62: VelocityContext velocityContext = new VelocityContext(modelTable); |
源文件: f:\XXXX\GerateHTML.aspx.cs 行: 64
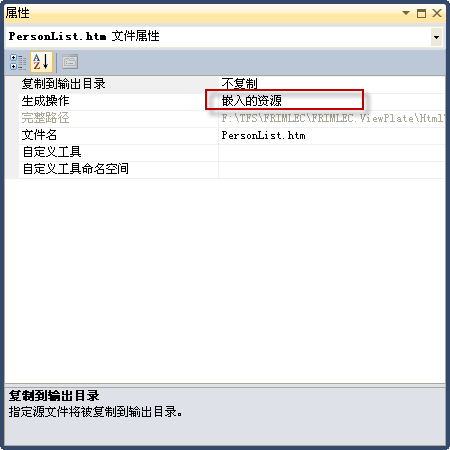
解决办法:把文件的生成操作改为“嵌入的资源”
本文转自灵动生活博客园博客,原文链接:http://www.cnblogs.com/ywqu/archive/2011/06/28/2092436.html,如需转载请自行联系原作者


