
数据压缩技术,是减少数据冗余和所需存储空间的一种技术方法。有研究称,数据压缩的概念最早可以追溯到发明摩斯密码的19世纪,古老的摩斯密码使用了基本的压缩方法,可以有效改善系统的整体效率,从而帮助电报员在更短的时间里传输更多信息。现代的压缩技术则比摩斯密码要复杂很多,今天我们就来看一下,浪潮存储高端联邦的核心成员——全固态存储HF5000-F,使用了哪些创新的压缩技术。
“老司机”带你上高速,实现2到5倍数据压缩比率
压缩算法,对于当前互联网从本地到云端、一切数据流存储的高效运行都至关重要。浪潮在2016年推出的HF全固态存储采用创新技术,在算法上具备较大优势,通过在控制器中置入压缩、去重、消0等高级功能,压缩实际写入3D NAND的数据量,可用容量提升5倍+,整体性能提升2-3倍。
浪潮固态存储HF5000-F在压缩功能方面,称得上是一名“老司机”,可以提供更高的压缩比,为数据存储节省更多空间。它的在线数据压缩功能,可在数据写入SSD之前用压缩算法对数据内容进行压缩,在不影响存储性能的同时,达到2到5倍的数据压缩比率,压缩后的数据才写入SSD。
有效的在线数据压缩,可以降低SSD闪存介质进行重复数据删除时的Hash存储消耗,从而提高SSD使用率。数据压缩技术在除虚拟化桌面VDI之外的更多应用环境中,都比重复数据删除具备更高的效率与优势。
浪潮HF5000-F的高速压缩秘籍:变长数据块布局
下面就来看一下,这名“老司机”——浪潮HF5000-F在线数据压缩功能的工作原理介绍。
首先,看写入操作。浪潮HF5000-F采用有后备电源的镜像NVRAM做写缓存掉电安全保护,写入数据同时进入普通内存和NVRAM,并在两个控制器的NVRAM之间做镜像复制,镜像完成后,向主机回复写入操作完成,然后存储系统对在内存中的写入数据进行压缩处理。
与在线重复数据删除一样,浪潮HF5000-F在线数据压缩的技术基础是“变长数据块布局”,在线数据压缩的过程是:
首先,将多个数据块分别加以压缩:
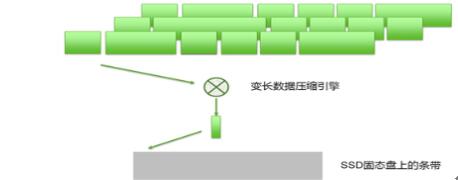
压缩后的数据块长度不尽相同,逻辑上合并为“数据组”,即数据条带:
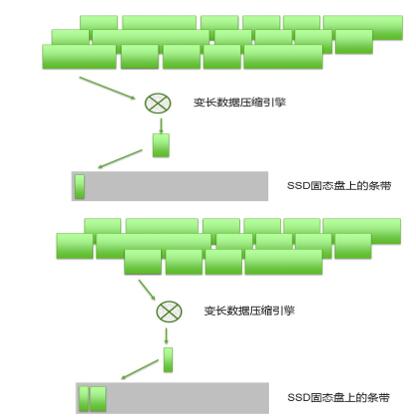
然后将“数据组”即数据条带,顺序写入最终存储介质,如SSD盘或磁盘:
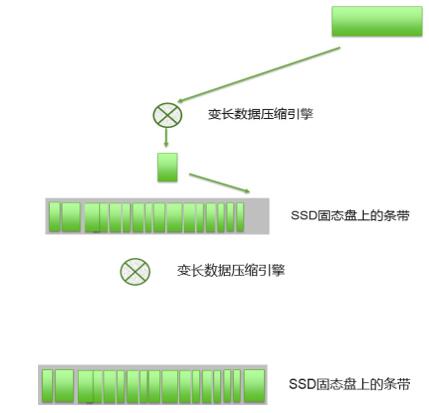
在这一过程中,如果某一数据块M需要更新,则只需将更新的M’压缩,合并进入新的“数据组”,然后如往常一样,顺序写入存储介质。这就为“数据压缩、更新、再压缩”的过程节省了大量的计算和后台资源,不需要对M及同组所有数据块解压缩、再对M’和同组数据块进行再次压缩,也无需额外将闪存或磁盘介质上的M以及同组所有数据块读至系统内存、写入至存储介质。
举例来说,浪潮HF5000-F的“变长数据块布局”,就像一辆高速前行的列车,如果车厢中的某位“乘客”M需要更新,只需针对M提供单独的服务,而不会打扰到其他乘客。
高效压缩,性能无损
浪潮HF5000-F在线压缩对性能的影响仅在1%~3%,可以忽略不计。HF5000-F系列采用的LZ4压缩算法以快速及资源开销小为目标,并不追求极致的压缩比,因此对控制器的CPU、内存等资源占用很少。对于HF5000-F系列选用的Intel Xeo CPU而言,使用LZ4算法对CPU只有3%左右的资源占用。性能影响的不同,主要受数据压缩的效果影响,如果压缩效果好,则完全可以忽略对系统的整体影响;即使压缩效果不够理想,对性能也仅有3%左右的微小影响。

浪潮固态存储HF5000
走在业界前列,适用各类场景
浪潮固态存储在算法上的创新与优势走在业界前列,HF5000-F的数据压缩功能适合于各种应用环境,它的在线数据压缩不会带来性能损耗,所以这项功能在默认情况下都是处于打开状态的;如果在数据本身就是压缩格式的场景下,HF5000-F也可以按照数据卷关闭压缩功能。
在创新技术的支撑下,HF5000-F适用于多媒体音频、视频、图像等各类常见压缩格式的数据,可以为金融、互联网、制造、医疗、政府等各类追求高I/O和低延时的场景,提供高效、稳健的数据服务。
原文发布时间为:2017年2月21日
本文来自云栖社区合作伙伴至顶网,了解相关信息可以关注至顶网。


