

错把相关性当成因果性 correlation vs. causation
经典的冰淇凌销量和游泳溺水人数成正比的数据,这并不能说明冰淇凌销量的增加会导致更多的人溺水,而只能说明二者相关,比如因为天热所以二者数量都增加了。这个例子比较明显,说起来可能会有人觉得怎么会有人犯这样的错误,然而在实际生活、学习、工作中,时不时的就会有人犯这样的错误。
举个栗子
数据显示,当科比出手10-19次时,湖人的胜率是71.5%;当科比出手20-29次时,湖人的胜率骤降到60.8%;而当科比出手30次或者更多时,湖人的胜率只有41.7%。
根据这组数据,为了赢球,科比应该少出手?并不一定如此。有可能科比出手少的时候是因为队友状态好,并不需要他出手太多。也有可能是因为球队早早领先,垃圾时间太多。而出手太多的比赛是因为比赛艰难或者队友状态不好,需要他挺身而出。当然,以上也只是可能之一,具体是什么情况光靠这组数据并不能得出任何结论。

幸存者偏差 survivorship bias
数据分析中看到的样本是“幸存了某些经历”才被观察到的,进而导致结论不正确。
比如比尔盖茨、乔布斯、扎克伯格都没有念完大学,所以大家都应该退学去创业。这一结论的最大问题在于那些退学而又没有成功的例子,很多时候我们是看不到的。另一方面,他们是因为牛逼才退学,而不是退学才牛逼的,看,相关性/因果性真是限魂不散。
再比如 Uber 发现新用户有10块钱优惠券,但是平均评价却只有3星。相反,第二次再用的时候没有优惠券了,评价却高达4星半。这说明,不给优惠券用户评价会更高,果然用户虽然爱用优惠券,但内心还是觉得便宜没好东西的?很明显,幸存者偏差在这个例子里体现在那些打一星二星评价的用户,之后可能就没有第二次了。更明显的,这个例子是我瞎扯的。

样本跟整体存在着本质的不同
以知乎为例,会有种错觉人人年薪百万,985/211起,各种GFSBFM,天朝收入水平直逼湾区码工。然而一方面这是幸存者偏差,知乎大V们的发声更容易被看到(看,幸存者偏差也是阴魂不散)。另一方面,不要小瞧知乎跟天朝网民的差别,以及天朝网民跟天朝老百姓的差别–样本跟整体的差别。
类似的例子有水木的工作版块、步行街的收入和华人网站的贫困线。

过于追逐统计上的显著性 statistical significance
统计101告诉我们,要比较两组数是否不同,最基本的一点可以看它们的区别是不是统计上显著。比如 Linkedin 又要改版了(我为什么要说又呢),有两个版本 A 和 B. 灰度测试发现,跟现有版本比起来,A 的日活比现有版本高20%,但是统计不显著。而 B 的日活跟现有版本虽然只高了3%,但是统计显著。于是 PM 拿出统计101翻到第二页说,来,咱们把统计显著的版本 B 上线吧。苦逼的数据科学家 DS 说,等一下!并不是所有时候都选统计显著的那一个,咱们再看看版本 A 的数据吧(具体分析略过一万字)。
很显然,这个例子也是我瞎扯的。

不做数据可视化,以及更可怕的:做出错误或者带误导性的数据可视化
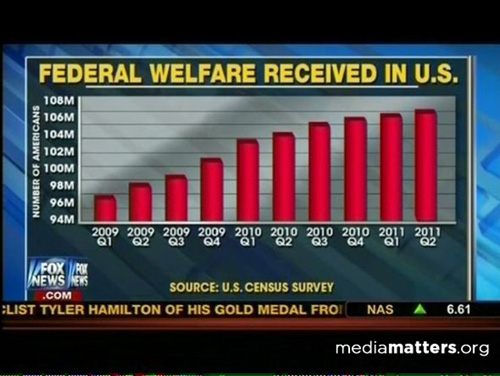
在趋势图中,为了说明增长趋势多明显,把Y调成不从0开始。这样差距会看起来很大,增长很大,但是如果把Y轴从0开始看的话,会显得基本没有差距。
(一下步就是要编排一个 twitter 的例子了23333,因为数据分析表明,有 twitter 公司这样的例子读起来会更有趣)
数据分析提供的结果和建议不具有可行性
twitter通过分析文本数据发现。。。
算了,我编不出来,由此可见,不具有可行性的结果虽然是“理论正确‘的分析结果,然并卵。。。

不做数据分析
别笑,据以前的校内后来的人人现在不知道叫什么的 PM 说,这是真的。(开个玩笑,人人的同仁要是介意的话我删掉)
最后的大招:如何解释 p-value
具体我就不讲了, 讲错了我明天还怎么面对老板和同事啊。




