【原创】(十)Linux内存管理 - zoned page frame allocator - 5(1)https://developer.aliyun.com/article/1543821
3.2 总体流程分析
与页面压缩类似,有两种方式来触发页面回收:
- 内存节点中的内存空闲页面低于
low watermark时,kswapd内核线程被唤醒,进行异步回收; - 在内存分配的时候,遇到内存不足,空闲页面低于
min watermark时,直接进行回收;
两种方式的调用流程如下图所示:
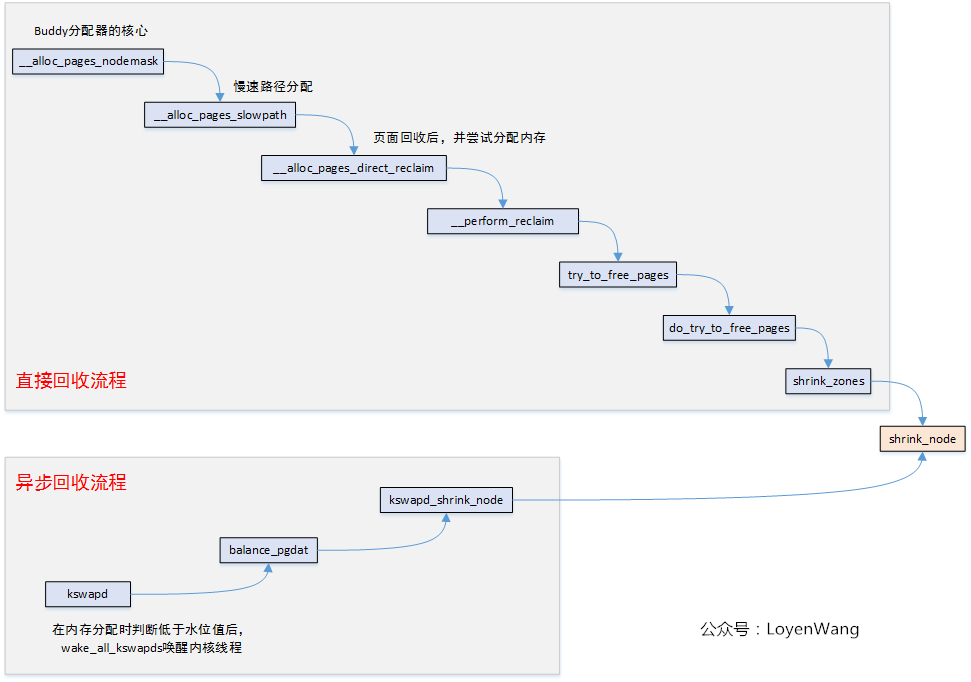
3.3 直接回收
__alloc_pages_slowpath
该函数调用_perform_reclaim来对页面进行回收处理后,再重新申请分配页面,如果第一次申请失败,将pcp缓存清空后再retry。__perform_reclaim
该函数中做了以下工作:
- 如果设置了
cpuset_memory_pressure_enabled,则先更新当前任务的cpuset频率表fmeter; - 将当前任务的标志置上
PF_MEMALLOC,防止递归调用页面回收例程; - 调用
try_to_free_pages来进行回收处理; - 恢复当前任务的标志;
try_to_free_pagestry_to_free_pages函数中,主要完成了以下工作:
- 初始化
struct scan_control sc结构; - 调用
throttle_direct_reclaim函数进行判断,该函数会对用户任务的直接回收请求进行限制; - 调用
do_try_to_free_pages进行回收处理;
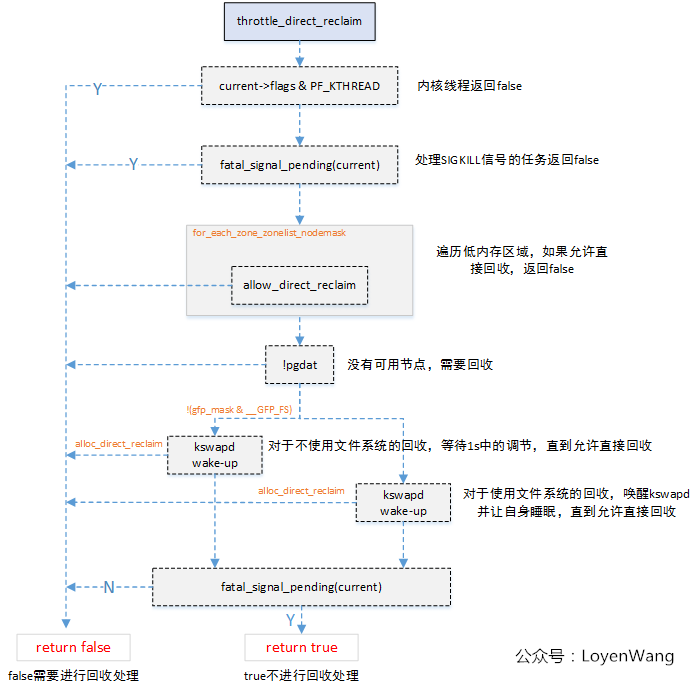
再来看看throttle_direct_reclaim函数中调用的alloc_direct_reclaim:
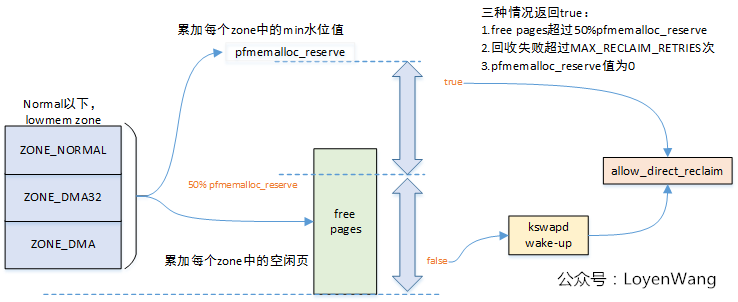
只有throttle_direct_reclaim函数返回值为false,页面的回收才会进一步往下执行。
do_try_to_free_pages
- 通过
delayacct_freepages_start/delayacct_freepages_end量化页面回收的时间开销; - 随着回收优先级的调整,通过
vmpressure_prio来更新memory pressure值; - 循环调用
shrink_zones来回收页面,回收页面足够了或者可以进行内存压缩时,就会跳出循环不再进行回收处理;
3.4 异步回收
kswapd内核线程,当空闲页面低于watermark时会被唤醒,进行页面回收处理,balance_pgdat是回收的主函数,如下图:
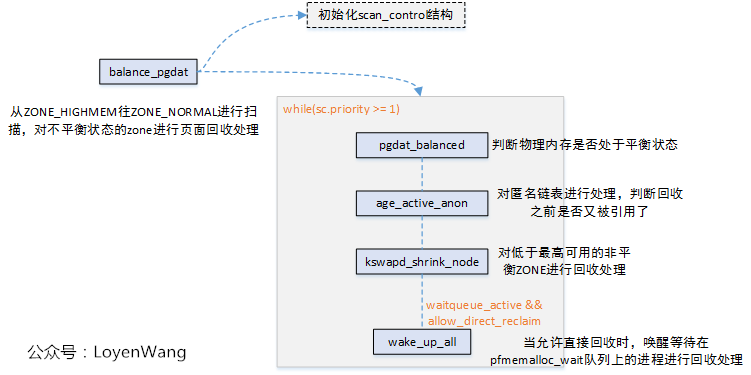
异步回收线程和同步直接回收存进程在交互的地方:
- 在低水位情况下进程在直接回收时会唤醒
kswapd线程; - 异步回收时,
kswapd线程也会通过wake_up_all(&pgdat->pfmemalloc_wait)来唤醒等待在该队列上进行同步回收的进程;
kswapd内核线程会在内存节点达到平衡状态时,退出LRU链表的扫描。
3.5 shrink_node
前边铺垫了很多,真正的主角要上场了,不管是同步还是异步的回收,最终都落实在shrink_node函数上。
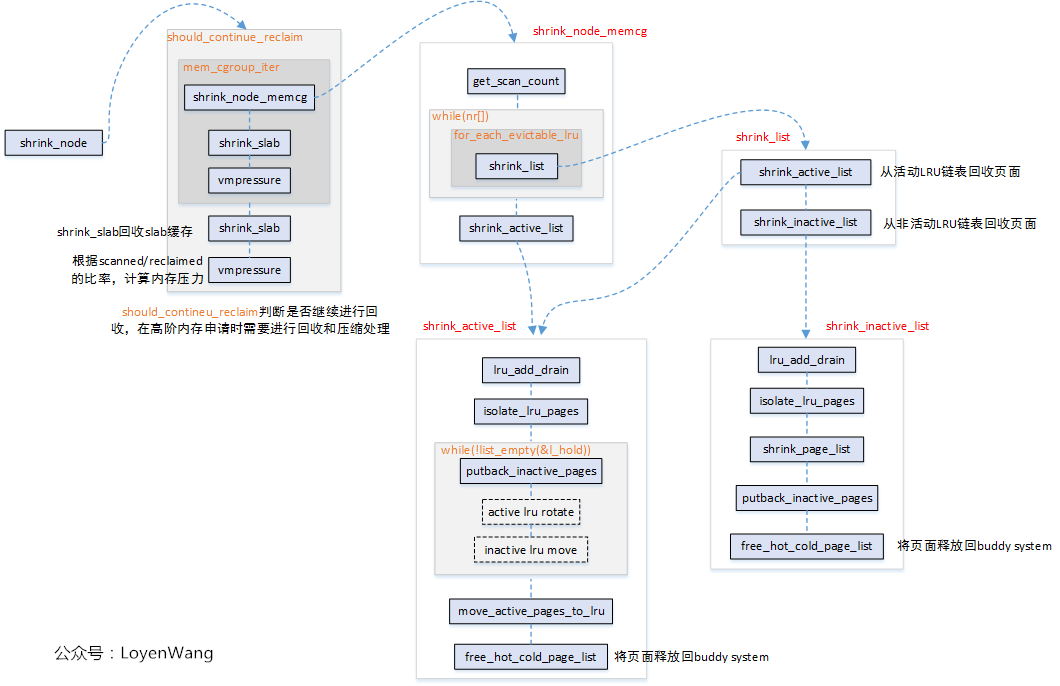
shrink_node的调用关系如上图所示,下边将针对关键函数进行分析。
get_scan_count
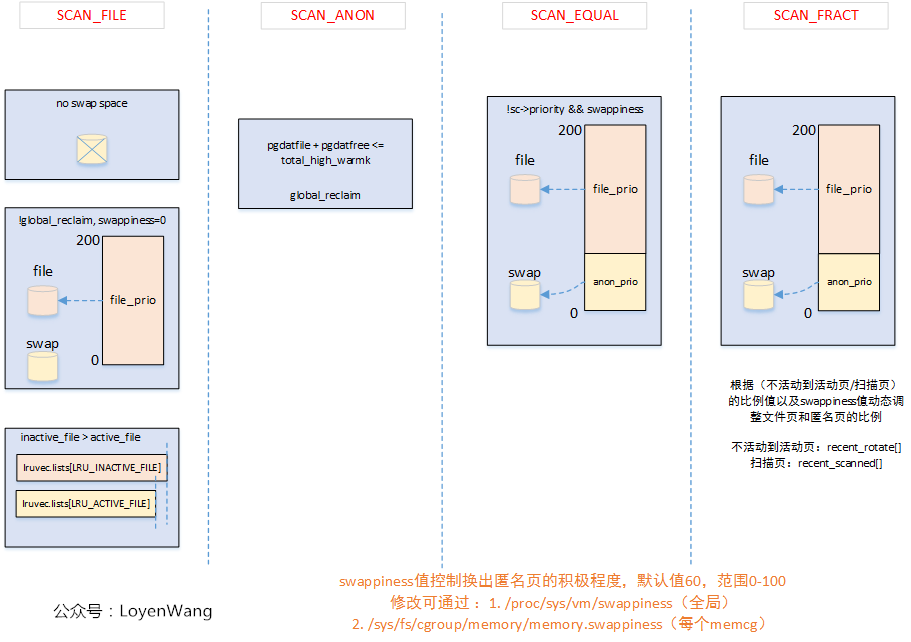
这个函数用于获取针对文件页和匿名页的扫描页面数。这个函数决定内存回收每次扫描多少页,匿名页和文件页分别是多少,比例如何分配等。
在函数的执行过程中,根据四种扫描平衡的方法标签来最终选择计算方式,四种扫描平衡标签如下:
enum scan_balance { SCAN_EQUAL, // 计算出的扫描值按原样使用 SCAN_FRACT, // 将分数应用于计算的扫描值 SCAN_ANON, // 对于文件页LRU,将扫描次数更改为0 SCAN_FILE, // 对于匿名页LRU,将扫描次数更改为0 };
来一张图:
shrink_node_memcgshrink_node_memcg函数中,调用了get_scan_count函数之后,获取到了扫描页面的信息后,就开始进入主题对LRU链表进行扫描处理了。它会对匿名页和文件页做平衡处理,选择更合适的页面来进行回收。当回收的页面超过了目标页面数后,将停止对文件页和匿名页两者间LRU页面数少的那一方的扫描,并调整对页面数多的另一方的扫描速度。最后,如果不活跃页面少于活跃页面,则需要将活跃页面迁移到不活跃页面链表中。
来一张图:
shrink_list
在shrink_list函数中主要是从lruvec的链表中进行页面回收:
- 仅当活动页面数多于非活动页面数时才调用
shrink_active_list对活动链表处理; - 调用
shrink_inactive_list对非活动链表进行处理;
shrink_active_list
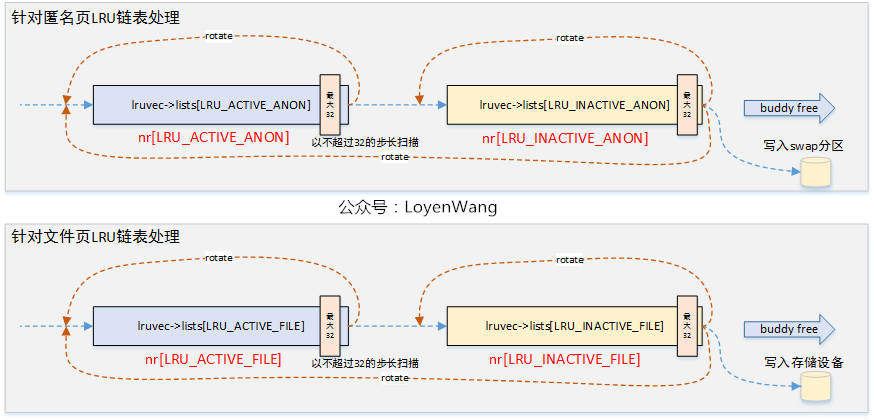
从函数的调用关系图中可以看出,shrink_active_list/shrink_inactive_list函数都调用了isolate_lru_pages函数,有必要先了解一下这个函数。isolate_lru_pages函数,完成的工作就是从指定的lruvec中链表扫描目标数量的页面进行分离处理,并将分离的页面以链表形式返回。而在这个过程中,有些特殊页面不能进行分离处理时,会被rotate到LRU链表的头部。
shrink_active_list的整体效果图如下:
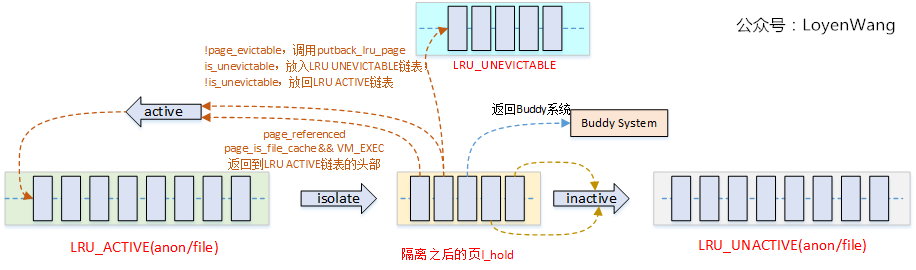
先对LRU ACTIVE链表做isolate操作,这部分操作会分离出来一部分页面,然后再对这些分离页面做进一步的判断,根据最近是否被referenced以及其它标志位做处理,基本上有四种去向:
1)rotate回原来的ACTIVE链表中;
2)处理成功移动到对应的UNACTIVE链表中;
3)不再使用返回Buddy系统;
4)如果出现了不可回收的情况(概率比较低),则放回LRU_UNEVICTABLE链表。
shrink_inactive_list
内存回收的最后一步就是处理LRU_UNACTIVE链表了,该写回存储设备的写回存储设备,该写到Swap分区的写到Swap分区,最终就是释放处理。
在提供最终效果图之前,先来分析一下shrink_page_list函数,它是shrink_inactive_list的核心。
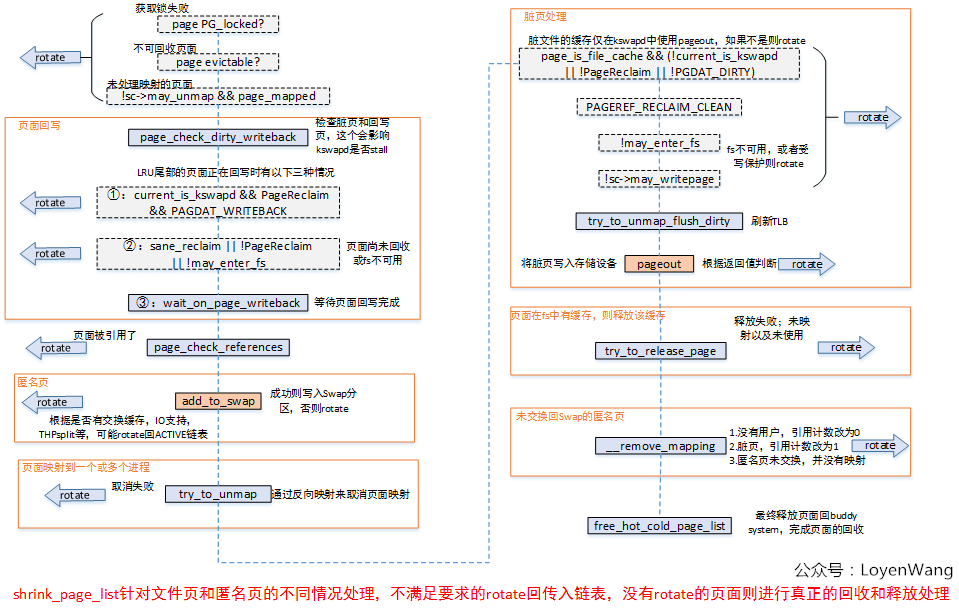
从上图中可以看出,shrink_page_list函数执行完毕后,页面要不就是rotate回原来的LRU链表中了,要不就是进行回收并最终返回了Buddy System了。
所以,最终的shrink_inactive_list的效果如下图:

页面回收的模块还是挺复杂的,还有很多内容没有深入细扣,比如页面反向映射,memcg内存控制组等。
前前后后看了半个月时间的代码,就此收工。
下一个专题要开始看看SLUB内存分配器了,待续。
