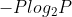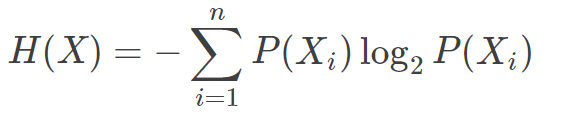先看信息量:
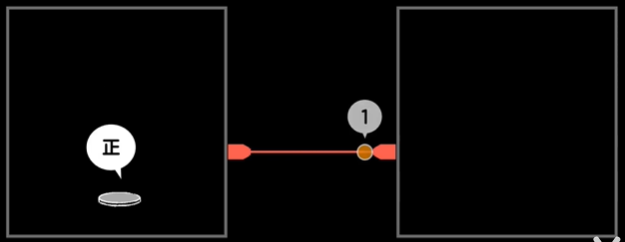
游戏1:抛掷硬币,猜它是正还是反,在抛之前,有两种可能,一反一正,但是当揭晓答案后,答案就确定了。
游戏2:四张不同花色的扑克牌,随机抽取一张,猜是什么花色的牌,翻开之前,可能是红桃,黑桃,方片,梅花。有四种同样的可能,看完之后,答案就确定了。
但是当我们在两个独立的房间中,只能靠一根发送电信号0或者1的电线进行交流时。
若需要把抛掷硬币的结果告诉你,需要发送1个电位信号。可用1表示正面,0表示反面。
而扑克牌游戏就需要发两个信号,00表示红桃,01表示黑桃,10表示方片,11表示梅花。

可以发现,信息的价值在于消除不确定性。
在抛硬币的现象中,它帮我们消除了两种情况中出现哪一个面的不确定性。
而传递抽取扑克牌信息的现象中,帮我们消除了4种情况下出现哪一种花色的不确定性。
再来看幸运大转盘,该转盘被分为8个区域,

若要将转盘的结果发送出去,那么需要几个信号呢?很简单3个,编码为001,000等的8种情况。
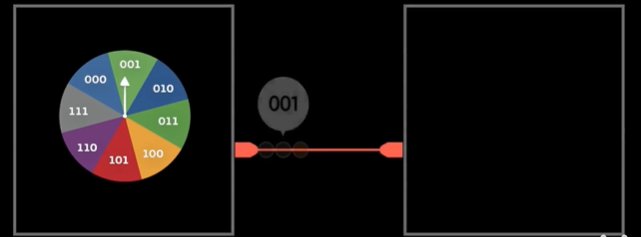
我们发现,把一个游戏系统中出现的等概率事件的数量取以2为底的对数,刚好是传递这个事件结果所需要的信号数量。

而这个数量就是信息量,这也就是香农发表的信息开山之作-一种通信的数学原理,对信息量度量进行了描述。后改为通信的数学原理。
一个信息需要1个信号表示,那么信息量就是1,两个信号,信息量就是2,依次类推。
也就是比特

刻画了一个事实:一个系统的等可能事件越多,那么传输其中一个事件的信息量也就越大。同时也意味着哪个事件发生的不确定性越大。可以看作对一个信号源不确定性的刻画。

把度量不确定性的信息量称之为信息熵。
但是大部分情况下出现的现象是事件发生的可能性不一样的系统。
如一枚硬币的制造工艺不一样,那么正反两边出现的概率肯定不是绝对的1/2.
若正面朝上是0.8,反面是0.2
那么当时反面时候,我们可以想象为在5个球中摸出某一个特殊(如中奖)球的概率,正面是从1.25中摸出一个中奖球的概率
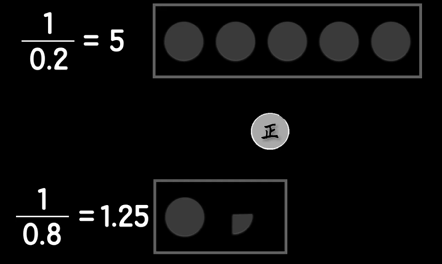
这样就把一个非等概率事件拆分成了两个等概率事件。
而面对等概率的事件,就可以计算其信息量。

而后两者相加,就是这个不均匀硬币的信息量。

两个想象出来的等概率事件出现的概率也是不一样的,我们相乘以后再相加起来。

若替换成符号。也就是这样

当有更多事件的时候,我们可以用一个丘壑符号来表示。

这里用负号是因为1/pi是小数,取以2为底的对数后,就会是负的,多以要添加负号。

信息熵实际上就是我们给每个概率数值想象出来的等概率摸球系统信息量的平均值或者说是信息量的期望。

做手脚的硬币也就只需要0.72个比特传输出去。
若是等概率时候计算,就是徒增计算量

此时信息量就是信息熵,信息量可以说是信息熵的一个特例。
信息量
信息量用来消除随机不确定性的东西,也就是说衡量信息量的大小就是看该消息消除不确定性的程度。
信息熵用来表示所有信息量的期望。
信息量一般是在等概率的情况下去理解信息量,而信息熵可以理解为不等概率的情况下去看信息量。