File类的概述
- File位于java.io包下,是对于文件和路径(文件夹)的抽象表现方式
- Java把文件中的文件和文件夹,封装成了一个File类,我们可以使用File类的方法创建、获取、删除、判断、遍历文件和文件夹
- File类是一个与系统无关的类,任何一个操作系统都可以使用这个类当中的方法
- file文件,directory文件夹,path路径
File类当中的成员变量
- File类当中共计四个File静态成员变量
static String pathSeparator 与系统相关的路径分隔符字符,为方便起见,表示为字符串。 static char pathSeparatorChar 与系统相关的路径分隔符。 static String separator 与系统相关的默认名称 - 分隔符字符,以方便的方式表示为字符串。 static char separatorChar 与系统相关的默认名称分隔符。
/* * @Description:File文件中的四个静态成员变量 * @Author: DaShu * @Date: 2021/5/31 21:31 */ @Test public void test01(){ //文件分隔符:win是\,Linux是/ System.out.println(File.separator); System.out.println(File.separatorChar); //路径分隔符:win是;Linux是: System.out.println(File.pathSeparator); System.out.println(File.pathSeparatorChar); // \ // \ // ; // ; }
绝对路径和相对路径
绝对路径是一个完整的路径,以盘符开始的路径,相对路径是一个简化的路径,相对指的是相对于当前项目的根目录

File类当中常用方法介绍
package com.pactera.io; import java.io.DataOutput; import java.io.File; import java.io.IOException; /** * @Auther: DaShu * @Date: 2021/6/1 16:13 * @Description: 测试File类的常用方法 * 获取:判断:创删 */ public class FileMethodTest { public static void main(String[] args) throws Exception { getAbsolutPath(); System.out.println("-----------------------getAbsolutPath();------------------------"); getPath(); System.out.println("-----------------------getPath();------------------------"); getName(); System.out.println("-----------------------getName();------------------------"); length(); System.out.println("-----------------------length();------------------------"); exists(); System.out.println("-----------------------exists();------------------------"); isDirectory(); System.out.println("--------------------------isDirectory();----------------------------"); isFile(); System.out.println("-----------------------isFile()--------------------------------------"); createNewFile(); System.out.println("----------------------------createNewFile();----------------------------------------"); mkdirAndmkdirs(); System.out.println("------------------------mkdirAndmkdirs()--------------------------------------------"); delete(); System.out.println("-----------------------delete()-----------------------------"); } /* * @Target:研究File类getAbsolutePath()路径 * @Author: DaShu * @Date: 2021/6/1 16:15 * @Result:获取的是对象当中的路径,不论当时对象里封装的是相对路径还是绝对路径,返回的都是绝对路径 */ public static void getAbsolutPath(){ File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\a.txt"); File absoluteFile = file1.getAbsoluteFile(); System.out.println("absoluteFile="+absoluteFile); //absoluteFile=D:\DevelopPackage\codeshop\Spring5.x\a.txt File file2 = new File("a.txt"); File absoluteFile1 = file2.getAbsoluteFile(); System.out.println("absoluteFile1="+absoluteFile1); //absoluteFile1=D:\DevelopPackage\codeshop\Spring5.x\a.txt,所谓的这个项目的根路径指的是项目所在的文件夹。 } /* * @Target:研究File类getPath(); * @Author: DaShu * @Date: 2021/6/1 16:23 * @Result: 对象当中封装的是绝对的,就是绝对的,相对的就是相对的。 * toString()方法调用的就是getPath()方法 */ public static void getPath(){ File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\a.txt"); String path = file1.getPath(); System.out.println("path="+path); //path=D:\DevelopPackage\codeshop\Spring5.x\a.txt File file2 = new File("a.txt"); String path1 = file2.getPath(); System.out.println("path1="+path1); //path1=a.txt } /* * @Target:研究File类getName(); * @Author: DaShu * @Date: 2021/6/1 16:32 * @Result:无论是什么路径获取的都是最后一段,对象当中的路径可以是绝对的,可以是相对的。 */ public static void getName(){ File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\a.txt"); System.out.println(file1.getName());//a.txt File file2 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x"); System.out.println(file2.getName());//Spring5.x } /* * @Target:研究File类length(); * @Author: DaShu * @Date: 2021/6/1 16:35 * @Result:文件夹是没有大小的,不能获取文件夹的大小,获取的也是文件夹所有文件的大小 * 如果路径当中给出的路径不存在,那么length方法返回的值是0; */ public static void length(){ File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\a.txt"); long length = file1.length(); System.out.println(file1.getAbsolutePath()); System.out.println(file1.exists()); System.out.println("length="+length); File file2 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x"); long length2 = file2.length(); System.out.println("length2="+length2); System.out.println(file2.hashCode() == file1.hashCode()); } /* * @Target:判断File类当中的exists()方法是否存在 * @Author: DaShu * @Date: 2021/6/1 17:04 * @Result: 判断路径是否存在 */ public static void exists(){ File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\a.txt"); System.out.println(file1.exists());//true File file2 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x"); System.out.println(file2.exists());//true File file3 = new File("a.txt"); System.out.println(file3.exists());//true File file4 = new File("b.txt"); System.out.println(file4.exists());//false } /* * @Target:判断File类当中的isDirectory()方法是否存在 * @Author: DaShu * @Date: 2021/6/1 17:04 * @Result: 判断给定路径是否以为文件夹结尾 * 注意:电脑中的文件要么是文件,要么是文件夹,这两个文件夹的路径必须是存在的否则就是默认返回false * */ public static void isDirectory(){ File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\a.txt"); System.out.println(file1.isDirectory());//false File file2 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x"); System.out.println(file2.isDirectory());//true File file3 = new File("a.txt"); System.out.println(file3.isDirectory());//false File file4 = new File("b"); System.out.println(file4.isDirectory());//false } /* * @Target:判断File类当中的isFile()方法是否存在 * @Author: DaShu * @Date: 2021/6/1 17:04 * @Result: 判断给定路径是否以为文件夹结尾 * 注意:电脑中的文件要么是文件,要么是文件夹,这两个文件夹的路径必须是存在的否则就是默认返回false * */ public static void isFile(){ File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\a.txt"); System.out.println(file1.isFile());//false File file2 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x"); System.out.println(file2.isFile());//true File file3 = new File("a.txt"); System.out.println(file3.isFile());//false File file4 = new File("b"); System.out.println(file4.isFile());//false } /* * @Target: File文件当中的createFile()方法 * @Author: DaShu * @Date: 2021/6/1 17:19 * @Result: createNewFile方法声明抛出了异常,我们调用也必须处理异常。 */ public static void createNewFile() throws Exception { File file1 = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\b.txt"); boolean newFile = file1.createNewFile(); System.out.println(newFile);//文件不存在的时候,才会创建文件,返回TRUE,此方法只能创建文件,不能创建文件夹,创建文件的路径必须存在,否则会抛出异常。 //public boolean createNewFile() throws IOException { // SecurityManager security = System.getSecurityManager(); // if (security != null) security.checkWrite(path); // if (isInvalid()) { // throw new IOException("Invalid file path"); // } // return fs.createFileExclusively(path); //} File file2 = new File("c.bat"); boolean newFile1 = file2.createNewFile(); System.out.println(newFile1);// File file4 = new File("新建文件"); boolean newFile2 = file4.createNewFile(); System.out.println(newFile2);//没有文件后缀也能创建文件 } /* * @Target: File文件当中的mk()方法 * @Author: DaShu * @Date: 2021/6/1 17:30 * @Result: */ public static void mkdirAndmkdirs(){ //mkdir创建单击文件夹,另一个创建单机多级都可以。 //文件夹不存在创建文件夹,返回TRUE,存在返回false //构造方法中的文件路径不存在返回false File file = new File("com"); boolean mkdir = file.mkdir(); System.out.println(mkdir); File file01 = new File("com\\pactera\\aaa\\shit"); boolean mkdirs = file01.mkdirs(); System.out.println(mkdirs); File file02 = new File("com\\pactera\\aaa\\shit\\shit.txt"); boolean mkdirss = file02.mkdirs(); System.out.println(mkdirss); } /* * @Target: File文件当中的delete方法 * @Author: DaShu * @Date: 2021/6/1 17:39 * @Result: 删除文件和文件夹 */ public static void delete(){ //删除成功返回TRUE,删除失败返回false,路径错误返回false, File file = new File("com"); boolean mkdir = file.delete(); System.out.println(mkdir); File file01 = new File("com\\pactera\\aaa\\shit"); boolean mkdirs = file01.delete(); System.out.println(mkdirs); File file02 = new File("com\\pactera\\aaa\\shit\\shit.txt"); boolean mkdirss = file02.delete(); System.out.println(mkdirss); } }
File类的遍历方法和迭代

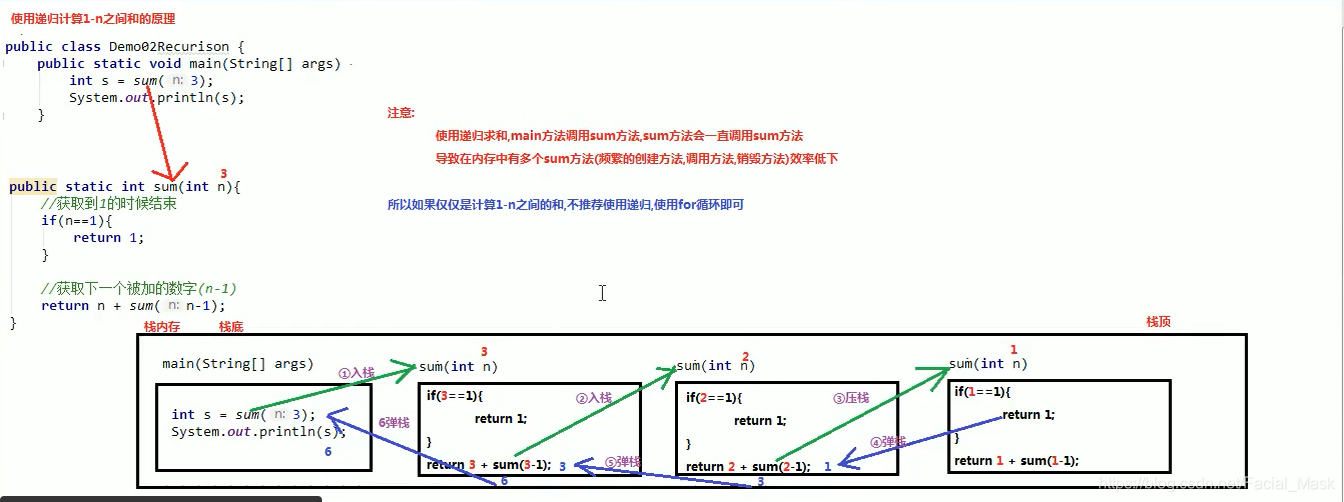
- 文件搜索的原理也是递归
package com.pactera.io; import com.sun.scenario.effect.impl.sw.sse.SSEBlend_SRC_OUTPeer; import java.io.File; /** * @Auther: DaShu * @Date: 2021/6/2 17:31 * @Description: 文件目录的遍历 */ public class FileRoll { public static void main(String[] args) { list_and_listFile(); File file = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\io"); System.out.println("------------------------------"); getAllFiles(file); } /* * @Target: list方法,listFile方法 * @Author: DaShu * @Date: 2021/6/2 17:31 * @Result:这两个方法遍历的的是File构造路径中的目录,如果路径是假的或者是文件 * 就会抛出一个空指针异常,这个遍历的方法可以获取到隐藏的文件和文件夹, */ public static void list_and_listFile(){ File file = new File("D:\\DevelopPackage\\codeshop\\Spring5.x\\io"); String[] list = file.list(); for (String s : list) { System.out.println(s); //io.iml //pom.xml //src //target } File[] files = file.listFiles(); for (File file1 : files) { System.out.println(file1.getAbsoluteFile()); //D:\DevelopPackage\codeshop\Spring5.x\io\io.iml //D:\DevelopPackage\codeshop\Spring5.x\io\pom.xml //D:\DevelopPackage\codeshop\Spring5.x\io\src //D:\DevelopPackage\codeshop\Spring5.x\io\target } for (File file1 : files) { System.out.println(file1.getName()); //io.iml //pom.xml //src //target } } //递归,递归的意思就是方法调用自己, //递归一定要有条件,要让方法能够停下来,防止栈内存溢出。 //递归中虽然有条件限定,但是递归次数也不能太多,否则也会繁盛栈内存溢出。 //构造方法禁止递归 //为什么会发生栈内存溢出呢? public static void getAllFiles(File dir){ File[] files = dir.listFiles(); for (File file : files) { if(file.isFile()){ System.out.println(file.getName()); }else{ System.out.println(file.getName()); getAllFiles(file); } //io.iml //pom.xml //src //main //java //com //pactera //io //FileMethodTest.java //FileRoll.java //resources //test //java //target //classes //com //pactera //io //FileMethodTest.class //FileRoll.class //generated-sources //annotations } } }
文件过滤器优化
文件过滤器是一个接口,刚才我们这个需求可以进行优化,我们可以使用过滤器来实现迭代文件和文件夹的接口,在File类当中由两个listFile()重载的方法,方法的参数就是过滤器,

在file类当中有两个和listFile()重载的方法,方法的参数传递的就是过滤器,是一个接口
- 先说listFiles(FileFilter f)这个方法,作用用于过滤文件,过滤的内容都是File对象, 其中有一个抽象方法,boolean accept(File file) 测试指定抽象路径名是否应该包含在某个路径名列表中。
- 方法的参数是就是file对象,
- 另一个方法,参数也是一个接口,是一个文件名称过滤器,用于过滤文件名称,用于过滤抽象方法,叫做accept,参数有两个,File对象, String name 使用listFile方法比那里目录获取的每一个文件、文件夹的名称。
注意事项:两个过滤器接口没有实现类,需要我们自己写实现类,重写过滤方法,在方法中自己定义过滤的规则。
//只要.java结尾的文件。 public static void getAllFiles01(File dir){ //方法一: FileFilter f1 = new FIleFilterImpl(); f1 = new FileFilter() { @Override public boolean accept(File pathname) { //如果pathname是一个文件夹,返回TRUE,不能遍历数组。 return pathname.getName().toLowerCase().endsWith(".java") || pathname.isDirectory(); } }; File[] files = dir.listFiles(f1); //方法二: files = dir.listFiles(new FilenameFilter() { @Override public boolean accept(File dir, String name) { return new File(dir,name).isDirectory()||name.toLowerCase().endsWith(".java"); } }); //方法三:使用lambda表达式 files = dir.listFiles((fileType,name)->new File(fileType,name).isDirectory()||name.toLowerCase().endsWith(".java")); for (File file : files) { if(file.isFile()){ System.out.println(file.getName()); }else{ System.out.println(file.getName()); getAllFiles(file); } } }
io概述
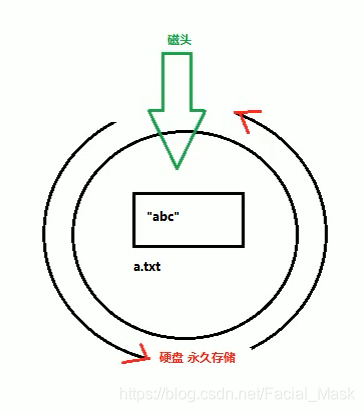
这个是硬盘,硬盘在不停的转,硬盘在不停转的同时与磁头进行接触读取到硬盘上不同的文件。内存当中的数据存储是临时存储,电脑已关机,数据就没了,io,就是读取和输出。流:就是数据,数据共有两种:字节流和字符流,一个字符占两个字节,也就是16个二进制的位。一个字节=8个二进制的位,
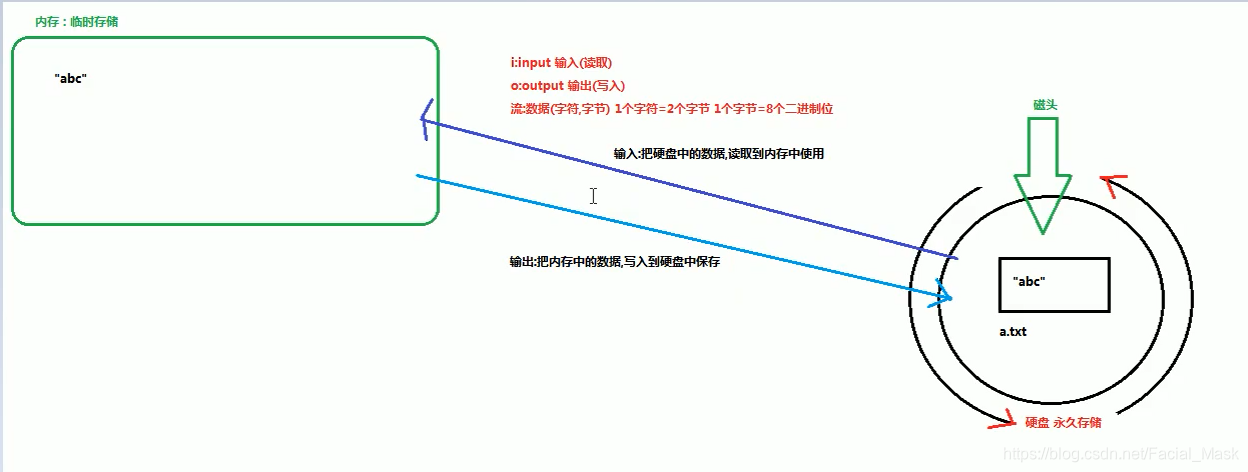
数据分为字节和字符,所以流也分为:
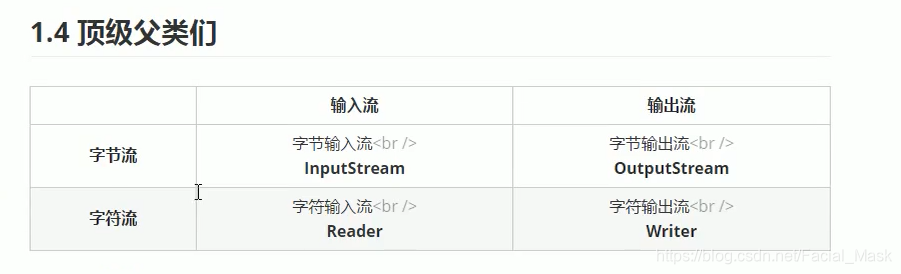
这四个也是io流的最顶层的四个父类。
字节流
一切皆为字节

硬盘上的视频,图片,文本,TXT文件,。。都是以字节的方式存储的,存储的任意的字节都是字节,那么作为流传输的时候也是以二进制字节的方式进行传输的,**所以,这个字节流可以读取任意的文件。**所有的流都在。java.io包下
OutputStream流
字节输出流的最顶层的父类,是一个抽象类,一般超类当中定义的都是公共的所有类都能使用的方法,

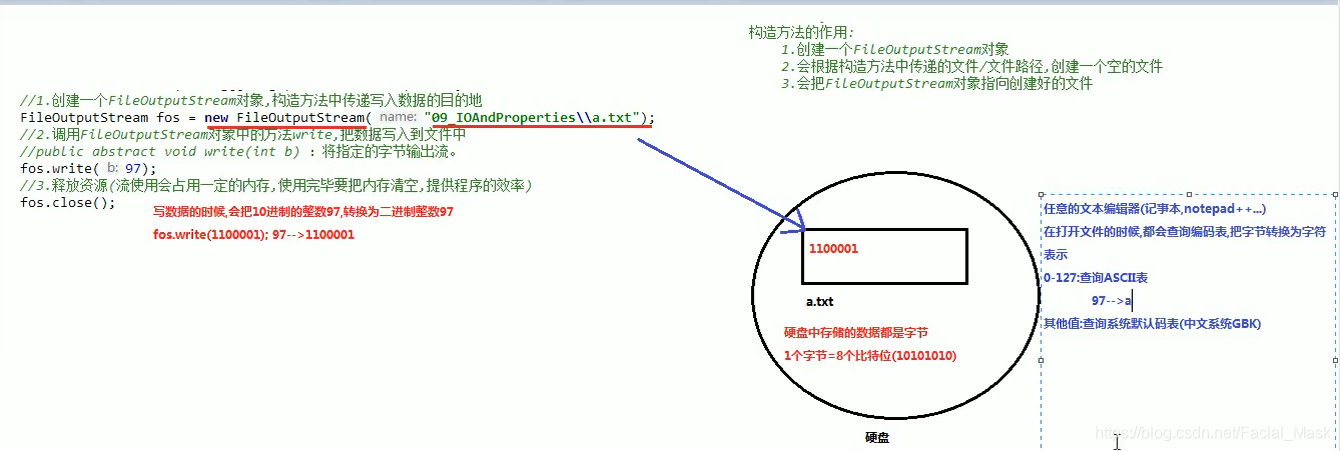
第二个是往文件当中写内容的输出流。这个流也叫:文件字节输出流,作用就是把内存中的数据写入到硬盘的文件中。


流使用的时候会占用一定的jvm内存和操作系统资源,使用完毕之后一定要关闭流,减少资源的占用,提高程序的效率。
文件存储的原理
输出多个字节
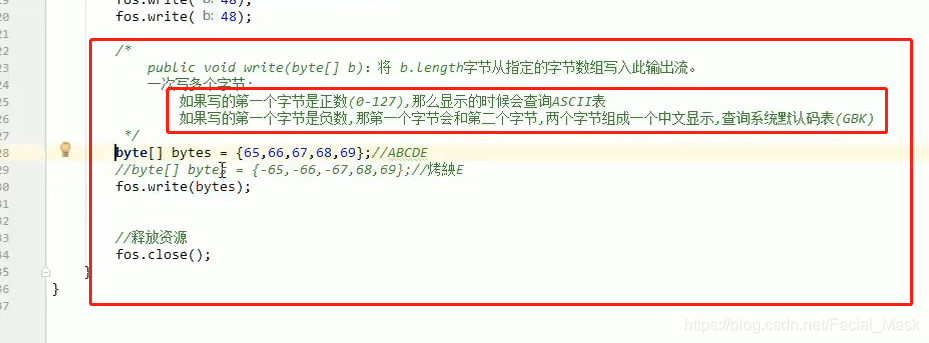
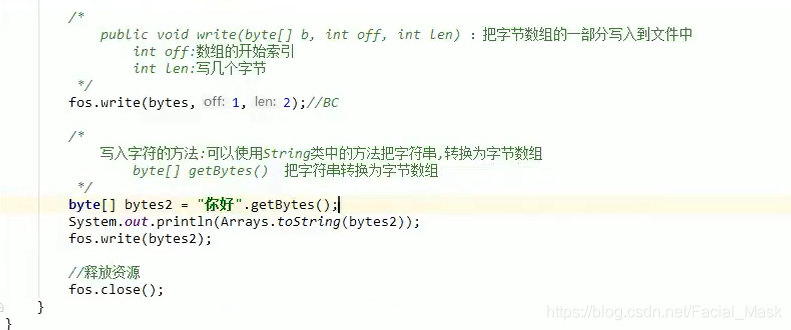
public static void write02() throws IOException { OutputStream fos = new FileOutputStream("io\\src\\main\\java\\com\\pactera\\io\\b.txt"); fos.write(49);//写出去一个字节 fos.write(48);//写出去一个字节 fos.write(-48);//写出去一个字节 byte[] bytes = {-65,-66,67,-68,69}; fos.write(bytes); byte[] bytes1 = {65,66,67,68,69}; fos.write(bytes1,1,2);//10锌綜糆BC byte[] bytes2 = "你好".getBytes(); System.out.println(Arrays.toString(bytes2));//[-28, -67, -96, -27, -91, -67] fos.write(bytes2); fos.close(); }
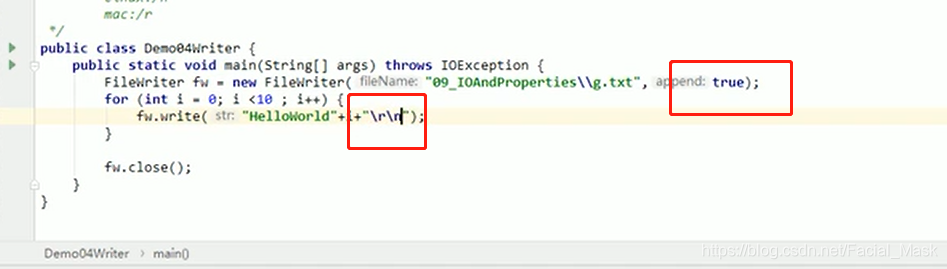
数据追加(非覆盖重写)+换行
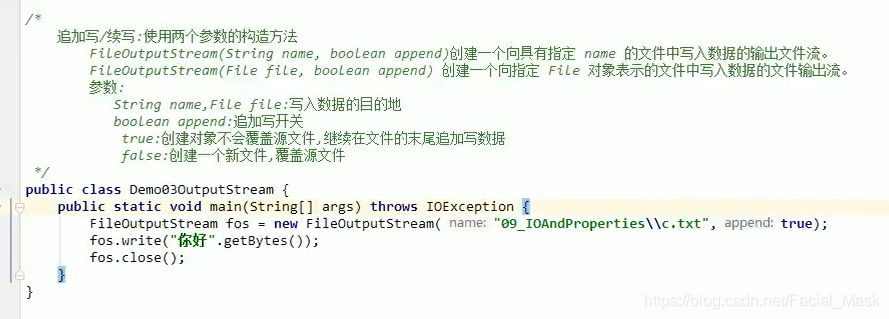
\r\n也是个字符串。
字节输入流InputStream
这是一个抽象类。这是所有的字节输入流的超类。定义类所有的字节输入流的共性的方法。
java.io.FileInputStream extends inputStream这个流叫做文件字节输入流。
可以把硬盘文件中的数据读取到内存中使用,这是他的一个作用,
构造方法
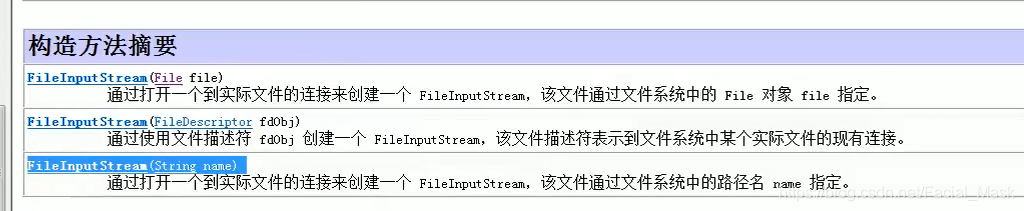
我们用第一个和第三个,他的参数是文件的数据源,Strring文件路径,File是文件对象。

常用方法进行数据读取
读取数据的原理:
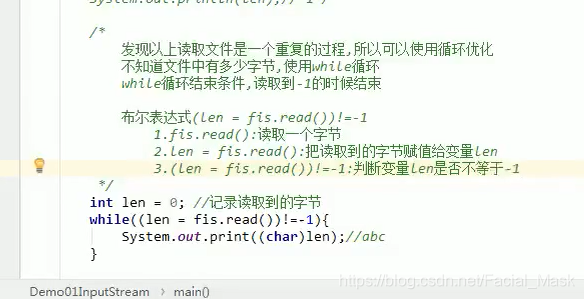
public static void main(String[] args) throws Exception { InputStream fis = new FileInputStream("spring5.x\\a.txt"); //一次读一个,读取文件中的一个字节,并进行返回,读取到文件的末尾,会返回-1 //这个函数是一个特殊的函数,读一次会把他的指针往回挪一位(流对象当中的指针),所以,每次调用read方法得到的结果都不一样。 /* int read = fis.read(); System.out.println(read); read = fis.read(); System.out.println(read); read = fis.read(); System.out.println(read); read = fis.read(); System.out.println(read); read = fis.read(); System.out.println(read);*/ //97 //98 //99 //-1 //-1 //以上读取文件是一个重复的过程,重复的过程我们可以使用循环优化,不知道文件中由多少个字节,使用while循环 int num ; while( (num = fis.read()) != -1){ System.out.println((char)num); } /* 97 98 99*/ fis.close(); }
- 字节输入流读取文件的一个原理
结束标记是看不到的,是window系统的一个结束标记。
创建了FileInputStream之后就就创建了一这样的对象,这个对象指向的硬盘上的对应路径的那个文件,并且指向的是那个文件的第一个字节。使用read方法的时候,并不是直接read方法去读文件,而是read方法被虚拟机调用,虚拟机去找os,os去找对应的操作函数,函数去找文件,是这样的一个过程。数据回来的时候也是文件数据给函数,函数给操作系统,os给jvm,对应的指针向后移动一位,指针到了结束标记之后,就会把结束标记给操作系统,操作系统把结束标记给jvm,jvm把-1给我们。所以,Linux一样。
文件的复制
文件当中都是以字节存储的,我们使用字节流可以读取任意类型的文件,我们的目地就是将文件读进来之后在存进其他的盘当中,我们怎么进行文件的复制呀就是一读一写,读进jvm内存之后在写到磁盘上。

/** * @Auther: DaShu * @Date: 2021/6/7 19:17 * @Description: */ public class Copy { public static void main(String[] args) throws Exception { File file; FileInputStream fis = new FileInputStream("D:\\love.shit"); FileOutputStream fos = new FileOutputStream("d:\\lovefuct.shit"); int len; while((len = fis.read()) != -1){ System.out.println(len); fos.write(len); } //关闭流的话肯定是先关闭输出的,在关闭输入的,如果重复执行这个方法的话,会先把之前复制的文件给删除掉,在进行复制 fos.close(); fis.close(); } }
/** * @Auther: DaShu * @Date: 2021/6/7 19:17 * @Description: */ public class Copy { public static void main(String[] args) throws Exception { long begin = System.currentTimeMillis(); FileInputStream fis = new FileInputStream("D:\\love.shit"); FileOutputStream fos = new FileOutputStream("d:\\mama.shit"); int len; byte[] bytes = new byte[10240000]; // while((len = fis.read(bytes)) != -1){ System.out.println(len); fos.write(bytes,0,len); } len = fis.read(bytes); fos.write(bytes,0,len); int i = 0; FileInputStream fis1 = new FileInputStream("D:\\love.shit"); FileOutputStream fos1 = new FileOutputStream("d:\\mama1.shit"); while((len = fis1.read(bytes))!=-1){ System.out.println(i); i++; fos1.write(bytes,0,len); } fos.close(); fis.close(); fos1.close(); fis1.close(); long end = System.currentTimeMillis(); System.out.println(end - begin + "mm"); } }
字节流读取中文
/** * @Auther: DaShu * @Date: 2021/6/7 19:51 * @Description: 使用字节流读取中文 */ public class ChineseTest { public static void main(String[] args)throws IOException { FileInputStream fileInputStream = new FileInputStream("d:\\aaa.txt"); int len = 0; /* * @Description: * @Author: DaShu * @Date: 2021/6/7 19:55 * Gbk的中文占用两个字节,utf8的中文占用3个字节, */ while((len = fileInputStream.read())!=-1){ System.out.println((char)len); } //228 ä //189 ½ //160 //229 å //165 ¥ //189 ½ fileInputStream.close(); } }
使用字节流读取中文的时候会由于gbk和utf8的编码占用空间的不同,字节流读取的字符是一半或者三分之一,这样的话,使用字符可能出现所谓的乱码的问题,为了解决这个问题,java当中产生了字符流,使用字符流可以读取中文英文等任意类型的东西。
Reader字符输入流最顶层父类
Reader当中定义了公共的使用的方法,他是一个抽象类。
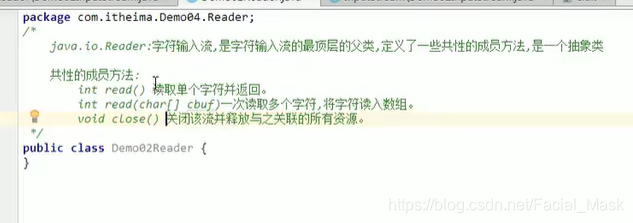

我们使用FileReader读取问价拿的字符输入流。
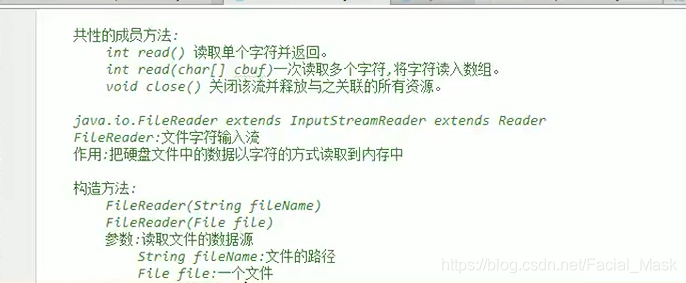
字符输入流的使用步骤:
/** * @Auther: DaShu * @Date: 2021/6/7 20:01 * @Description: */ public class ReaderDemo { public static void main(String[] args) throws Exception { Reader reader = new FileReader("d:\\aaa.txt"); // int len = 0; // while((len = reader.read()) != -1){ // System.out.print((char)len); // //你好avxd##$$%%@@# // } char[] cs = new char[1024]; int len = 0;//len记录的事读取到的有效字符的个数 //new String(char[]) //new String(char[],begin,lenth while ((len = reader.read(cs)) != -1){ System.out.println(new String(cs,0,len));//你好avxd##$$%%@@# } reader.close(); } }
Writer字符输出流最顶层父类
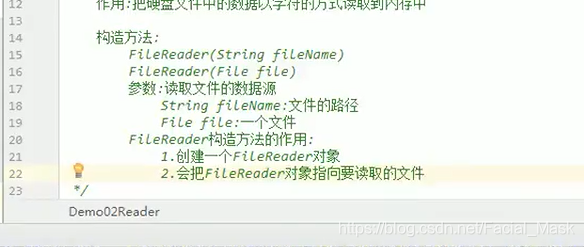
这是一个抽象类,是字节输出流的最顶层的父类,定义了公共的方法,定义了共性的方法,这个流可以直接写一个字符,写一个数组,写数组一部分,直接写字符串,定义了共性成员方法,FileWriter继承了一个OutputStreamWriter,继承了writer,
FileWriter叫做文件字符字符流,将内存中的字符传输来写入到文件当中,

字符输出流的使用的过程,
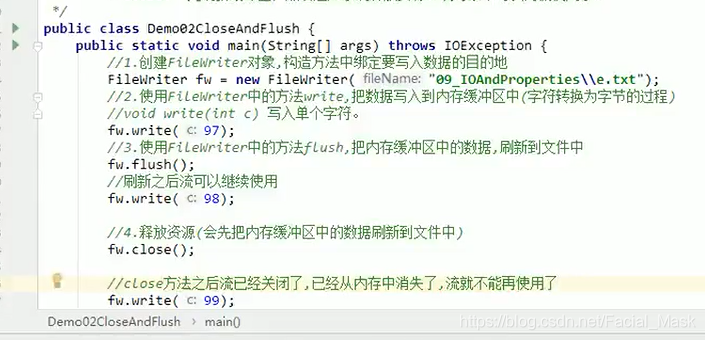
创建Filewriter对象,构造方法中绑定要写入数据的目的地,
使用filewriter中的方法write将数据写入内存当中的缓存区,(这个是将字节转为字符的过程)
使用FIleWriter当中的方法flush将内存缓冲区的数据,刷新到文件中,
释放资源(close)会先把内存缓冲区当中的数据刷新到文件中,所以这个flush这个方法可以不用写,字符流根字节流最大的区别就在于,不是直接将数据写入到文件中而是先把数据写入到内存中。
这个FileWriter的方法并不是直接将数据写入到硬盘上,如果我们执行write方法之后,既不close,又不flush方法,内容还在缓冲区当中,是不会到磁盘上的,所以文件是空的。 他这个写入到字节缓存区是在内存当中,并没有进入磁盘。
/** * @Auther: DaShu * @Date: 2021/6/7 20:28 * @Description: */ public class FileWriterTest { public static void main(String[] args) throws IOException { FileWriter fw = new FileWriter("D:\\d.txt"); //写单个字符 fw.write(97); fw.flush(); //执行close方法之前会先将缓冲区当中的流刷入磁盘当中。 fw.close(); } }
close方法和flush方法的区别
flush:刷新缓冲区,流对象还可以继续使用
flush:刷新缓冲区,然后通知系统释放资源,流对象不可以在使用了。
写数据的其他方法
/** * @Auther: DaShu * @Date: 2021/6/7 20:50 * @Description: */ public class FileWriterTest01 { public static void main(String[] args) throws Exception { FileWriter fw = new FileWriter("d:\\e.txt"); //写字符数组 char[] cs = {'a','b','c','d','e'}; fw.write(cs); //写字符数组的一部分 fw.write(cs,1,3); //写字符串 fw.write("传智播客"); fw.write("黑马程序员",2,3); //abcdebcd传智播客程序员 fw.close(); } }
字符流的续写和换行
这个和字节流一模一样。
续写和追加写,使用两个参数的构造方法就可以了。

流异常的处理
jdk1.7之前可以使用try catch finally来进行异常处理。
变量的作用于只在变量的声明的大扩招当中有效。
/** * @Auther: DaShu * @Date: 2021/6/7 21:07 * @Description: */ public class FileWriteTest02 { public static void main(String[] args) { //提高fw的作用域,这的变量是一个局部变量,变量使用的时候必须有值 //创建对象有可能失败,这样的话,fw没有值,所以需要一个初始化的值,所以编译不过去 FileWriter fw = null; try { fw = new FileWriter("D:\\d.txt"); fw.write(97); }catch (IOException e){ System.out.println(e); }finally { //如果fw创建失败了,fw是null。 if(fw != null){ try { //fw.close声明抛出异常,有可能报错,所以我们处理这个对象要么try , fw.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
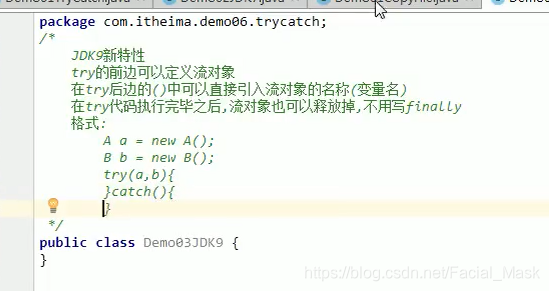
JDK7的新特性
在jdk7以后在try后边可以增加一个(),在括号中定义流对象,这个流对象的作用于是try当中有效,try当中的代码执行完毕就会自动把对象释放,不用写finally
try(定义一个或者多个流对象){
}catch(){
}
class StreamTest { public static void main(String[] args) { try(FileInputStream fis = new FileInputStream("D:\\love.shit"); FileOutputStream fos = new FileOutputStream("d:\\mama.shit");){ long begin = System.currentTimeMillis(); int len; byte[] bytes = new byte[10240000]; len = fis.read(bytes); fos.write(bytes,0,len); long end = System.currentTimeMillis(); System.out.println(end - begin + "mm"); }catch (IOException e){ e.printStackTrace(); } } }
jdk9的流的新特性
在jdk7的新特性上做了一点点修改。
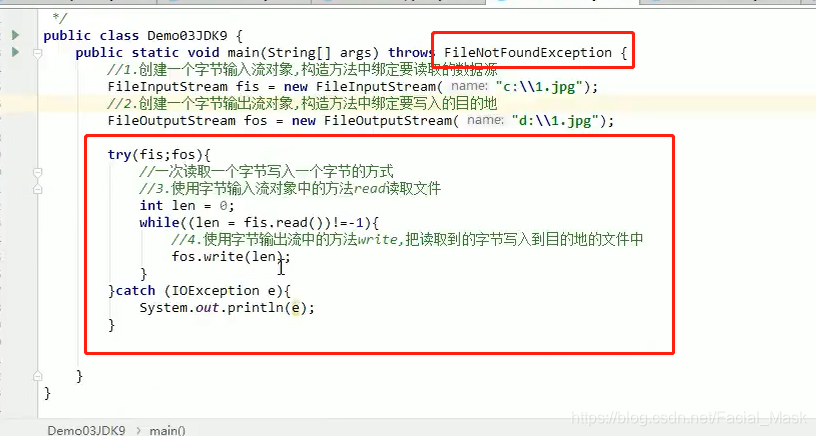
两种方式try完成之后流已经关闭了,
属性集Properties
HashTable是最早期的一个双列集合,在jdk1.0的时候就存在了,但是因为是单线程被淘汰了,他的子类Properties依旧活跃,因为她是唯一一个和IO相结合的集合,Propertyes类表示的是一个持久的属性集,属性列表当中的键和值都是一个字符串,
java.util.Properties集合 extends hashtable implements Map
Properties是一个唯一一个和io流相结合的结合,可以使用store方法吧集合当中的临时数据写入到磁盘当中,可以使用properties集合当中的load方法把硬盘当中保存的文件(键值对),读取到集合中进行使用。这个属性列表当中的键和值都是一个字符串他是一个双列结构,并且他们的键和值都是一个字符串,所以不用使用泛型了,默认都是字符串
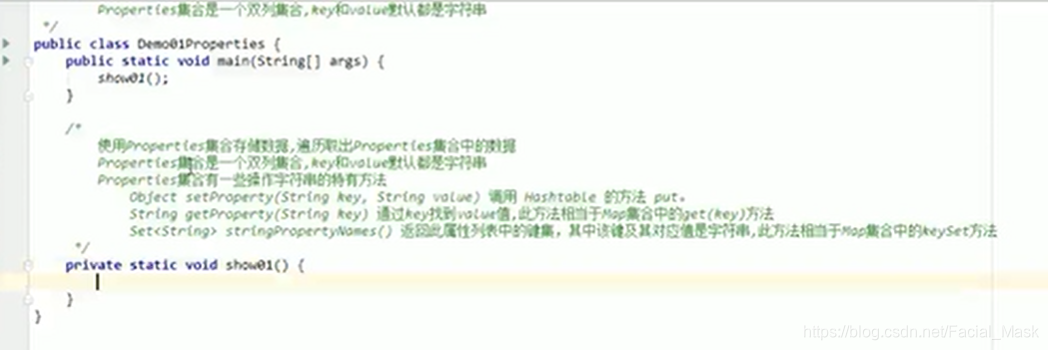
- Properties集合当中操作字符串的方法
/** * @Auther: DaShu * @Date: 2021/6/7 21:39 * @Description: */ public class PropertiesTest { public static void main(String[] args) { show(); } public static void show(){ Properties properties = new Properties(); properties.setProperty("赵丽颖","168"); properties.put("古力娜扎","shist"); properties.setProperty("迪丽热巴","165"); Set<String> strings = properties.stringPropertyNames(); for (String string : strings) { String property = properties.getProperty(string); System.out.println(property); //168 //shist //165 } } }
- properties当中的store方法

public static void show02() throws IOException { Properties properties = new Properties(); properties.setProperty("赵丽颖","168"); properties.put("古力娜扎","shist"); properties.setProperty("迪丽热巴","165"); FileWriter fw = new FileWriter("d:\\prop.txt"); // properties.store(fw,"save data"); //匿名对象不用关,因为匿名对象使用完之后自己就关了 //字符流可以写中文,字节流不可以写中文。 properties.store(new FileOutputStream("d:\\prop11.txt"),"save data"); fw.close(); //#save data //#Mon Jun 07 21:57:16 CST 2021 这个时间是他自己家的。 //赵丽颖=168 //古力娜扎=shist //迪丽热巴=165 }
- load方法
这个是今天的主要的方法,load方法可以把硬盘中保存的文件读取到内存当中,
public static void show03() throws Exception { Properties prop = new Properties(); prop.load(new FileReader("d:\\prop11.txt")); Set<String> strings = prop.stringPropertyNames(); for (String string : strings) { System.out.println(string + "=" + prop.getProperty(string)); //一般我们使用这个load方法都用字符流。 //迪丽热巴=165 //古力娜扎=shist //赵丽颖=168 } }
缓冲流
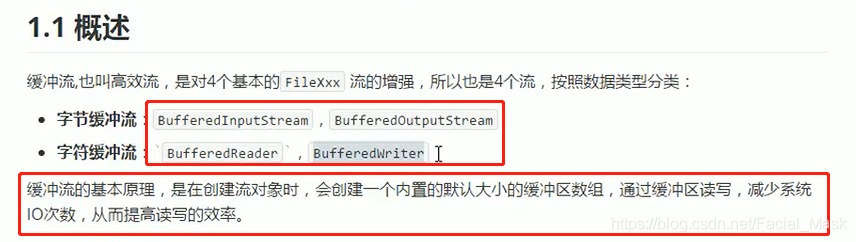
缓冲流的概念
缓冲流能够高效的读写,能够转换编码,能够持久化存储对象的序列化流,这些功能强大的缓冲流都是在基本的流对象基础之上创建来的,就像穿上铠甲的勇士一样,相当于是对基本流对象的增强。
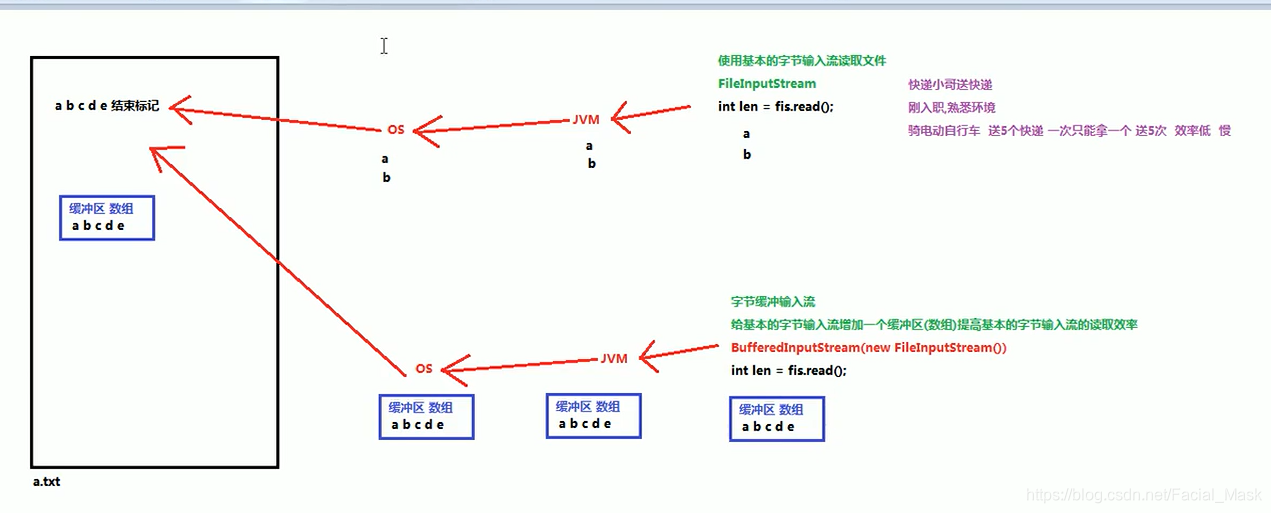
缓冲流的原理
每个文件当中都有一个结束标记,现在使用一个流读取文件,如果使用基本的字节输入流的话,FileInputStream 中的read方法进行读取。读取的过程java程序要找到jvm,jvm要找到操作系统,操作系统要找到相应的函数来进行读取。字节的读取的时候,读取一个字符到什么然后进行一级一级的返回。这样的话就非常的影响效率,二使用字节缓冲输入流的话,就会给基本的字节输入流增加一个缓冲区,也就是一个数组,提高基本的字节输入流的效率,这是字节缓冲输入流,字节缓冲输出流也是这个流程,比如说bufferedInputStream它里边需要传入一个基本的字节输入流,FileInputStream,有了这个高效的字节缓冲输入流之后,有一个缓冲区数组,通过这个数组可以一次性把所有的数组读取进来,在把这个数组整体进行返回。
注意:不管是字节的还是字符的都是增加了一个这样的数组,提高了读取的效率。
BufferedOutputStream
继承了OutputStream所以,这是个字节流。字节缓冲输出流。集成共性的父类的构造方法
构造方法
一共有两个。

/** * @Auther: DaShu * @Date: 2021/6/8 19:00 * @Description: 研究bufferdOutputStream */ public class BufferdOutputStreamTest { public static void main(String[] args) throws IOException{ File file = new File("d:\\bufferedOutputStream.txt"); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(file)); bos.write("我把数据写入到内存缓冲区".getBytes()); bos.flush();//flush方法才会把数据刷入到文件当中。 bos.close(); } }
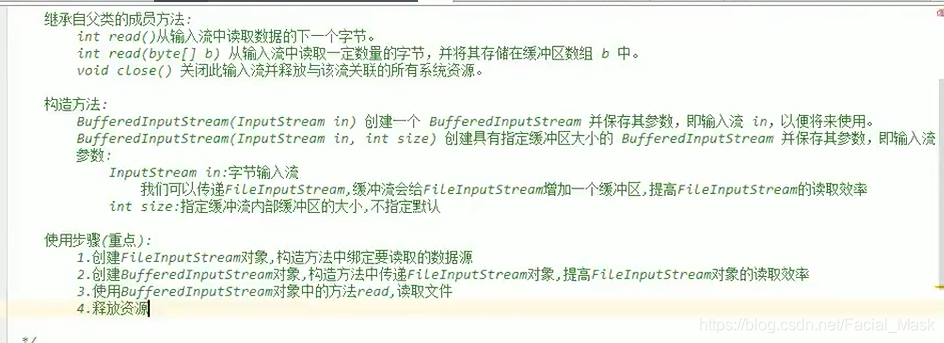
BufferedInputStream
继承了inputStream也是一个字节流,叫字节缓冲输入流,他的集成父类的成员方法。字节输入流有这三个方法。
构造方法
两个:默认缓冲区大小,指定缓冲区大小。需要一个FileInputStream对象。size是指定缓冲区大小。
class BufferedInputStreamTest{ public static void main(String[] args) throws IOException { File file = new File("d:\\BufferedOutputStream.txt"); FileInputStream fis = new FileInputStream(file); BufferedInputStream bis = new BufferedInputStream(fis); // int len; // while((len = bis.read()) != -1){ // System.out.println(len); // } //这个效率最快。 byte[] bytes = new byte[1024]; int len = 0; while((len = bis.read(bytes)) != -1){ System.out.println(new String(bytes,0,len)); } bis.close();//资源释放关闭缓冲流就可以了,关闭缓冲流就可以关闭对应的普通流 } }
效率测试
class BufferedVSUniverse{ public static void main(String[] args) throws IOException { try(BufferedInputStream bis = new BufferedInputStream(new FileInputStream(new File("d:\\test.txt"))); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File("d:\\test01.txt"))); FileInputStream fis = new FileInputStream(new File("d:\\test.txt")); FileOutputStream fos = new FileOutputStream(new File("d:\\test2.txt")); ){ long start01 = System.currentTimeMillis(); byte[] bytes = new byte[204800]; int len ; while((len = bis.read(bytes)) != -1){ bos.write(bytes,0,len); } bos.flush(); long end01 = System.currentTimeMillis(); System.out.println("buffered流的用时为:"+ (end01-start01)+"mm"); bos.close(); long start02 = System.currentTimeMillis(); while((len = fis.read(bytes)) != -1){ fos.write(bytes,0,len); } fos.flush(); long end02 = System.currentTimeMillis(); System.out.println("非buffered流的用时为:"+ (end02-start02)+"mm"); }catch (Exception e){ System.out.println(e); } } }
结论:
一个700多kb的文件,使用普通的输入输出流,单个字节读取需要6000多mm,使用数组需要10mm提升了600多倍,buffered这样的流的话进行读取,一个一个字节进行读取的话需要32mm,而使用数组的话大约需要5mm。
bufferedWriter
bufferedWriter extends writer 叫做字符缓冲输出流,集成自父类的成员方法。

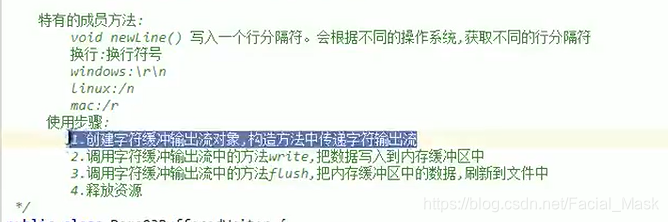


println当中调用的换行符号就是newline(),他的作用就是写一个换行符号
在这里插入代码片
bufferedReader
字符缓冲输入流,extends Reader 继承了成员方法。
文本内容进行排序。
转换流
字符编码和字符流。
计算机当中只能识别10101,计算机当中存储的也是二进制数据,计算机当中的文件和视频多事二进制存储的,但是将图片记性打开的时候并不是1010,而是图或者视频,任何一个软件都有转换功能,经1010转换成字符,图片,
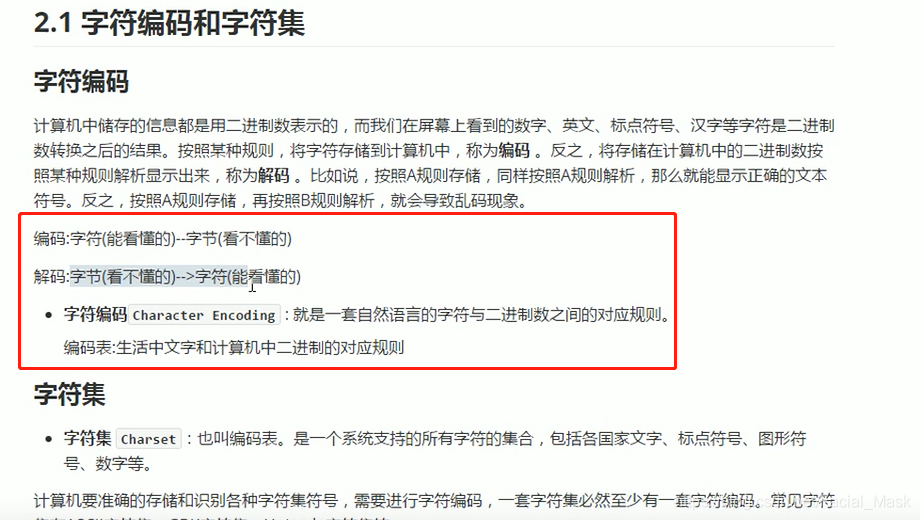
我们使用A编码进行编码,使用A编码进行解析就可以显示正确的文本,我们使用A规则存储使用B规则进行解析就会出现乱码的情况。
任何一个编码表都兼容了asill表,这是一个最基本的编码表。
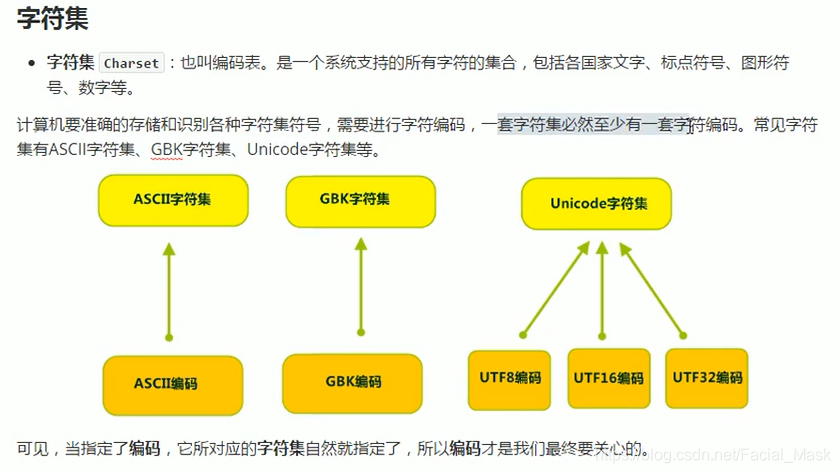
双编码的意思就是任何一个字符都是采用两个字节进行存储,所以gbk一个字符使用两个字节
GB18030使用的是多字节编码,有可能是一个字节,有可能是两个字节,有可能是四个字节,支持的文字非常多。

万国码:Unicode,

gbk当中两个字节存储一个中文,utf-8是三个字节对应一个中文,什么叫编码表,就是生活中的文字与计算机的存储的一种对应规则。
编码引出的问题
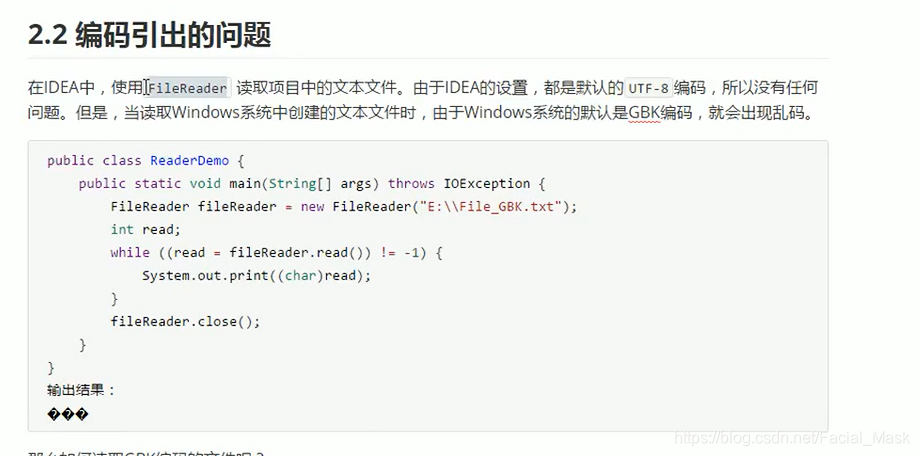
/** * @Auther: DaShu * @Date: 2021/6/9 20:09 * @Description: */ public class GbkTest { public static void main(String[] args) throws IOException { FileReader fr = new FileReader(new File("d:\\gbk编码.txt")); int len = 0; while((len = fr.read()) != -1){ System.out.print((char)len);//����Һô�Һ� } } }
编码和解码的方式不一样了。所以会造成乱码。
转换流
转换流的原理
FilerReader的原理是:底层使用fileInputStream这个字符流进行读取,然后fileReader查询utf8编码表进行转码把字节转换成我们能看懂的字符,
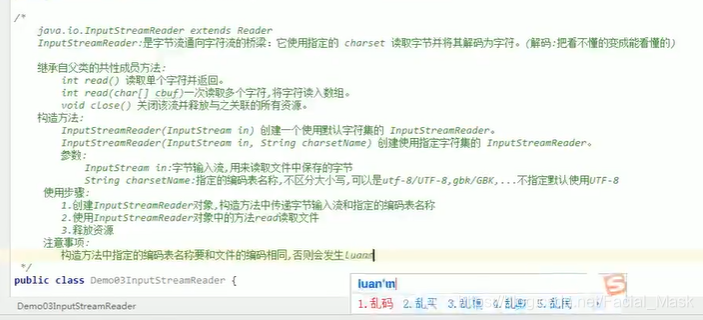
InputStreamReader是FileReader的父类,这个是字节流通向字符流的桥梁,他可以把字节流转换为字符流,他可以使用指定的字符集,
编码不一样占用的空间也不一样,字节的读写只能使用字节流,所以任何流的底层都是字节流。FileReader只能查询系统默认码表。


OutputStramWriter
以writer结尾肯定是一个字符流,extends Writer这是字符通过字节的桥梁,可以指定编码表,

class OutputStreamWriterTest{ public static void main(String[] args) throws Exception{ OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(new File("d:\\xxx.txt")),"GBK"); osw.write("我爱你中国,亲爱的目前"); osw.flush(); osw.close(); OutputStreamWriter osw1 = new OutputStreamWriter(new FileOutputStream(new File("d:\\xxxxxx.txt"))); osw1.write("我爱你中国,亲爱的目前"); osw1.flush(); osw1.close(); } }
InputStreamReader
字节流通向字符流的桥梁,extends Reader是一个字节流,按照指定字符集进行解码。
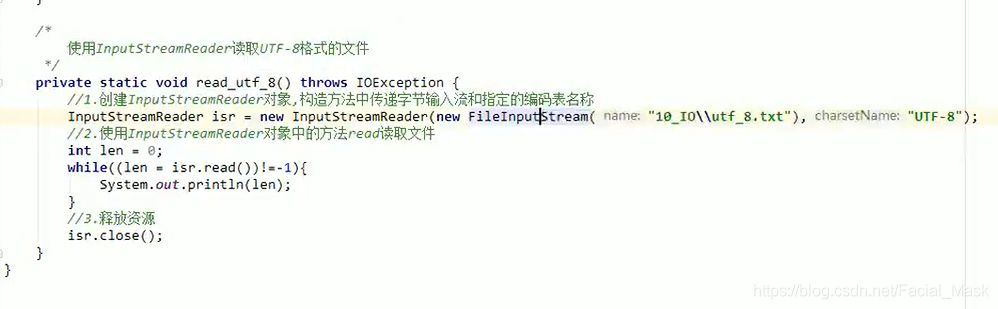
文件转码
序列化流和反序列化流
- 什么叫序列化,什么叫反序列化
把对象写入到磁盘中去保存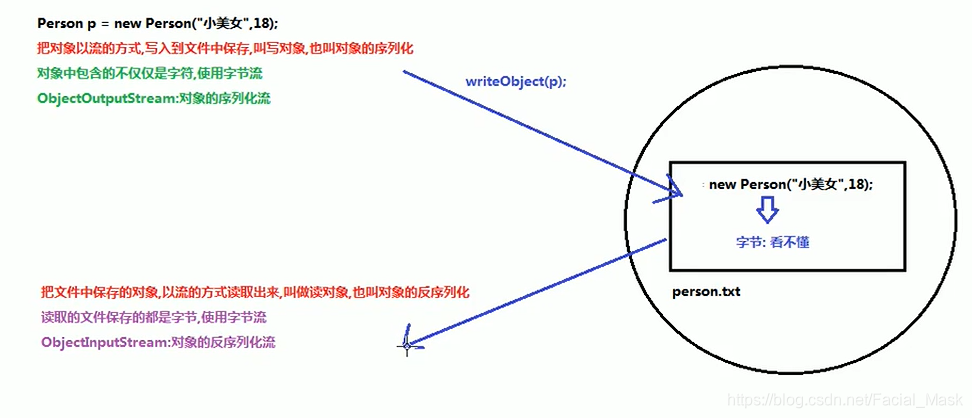
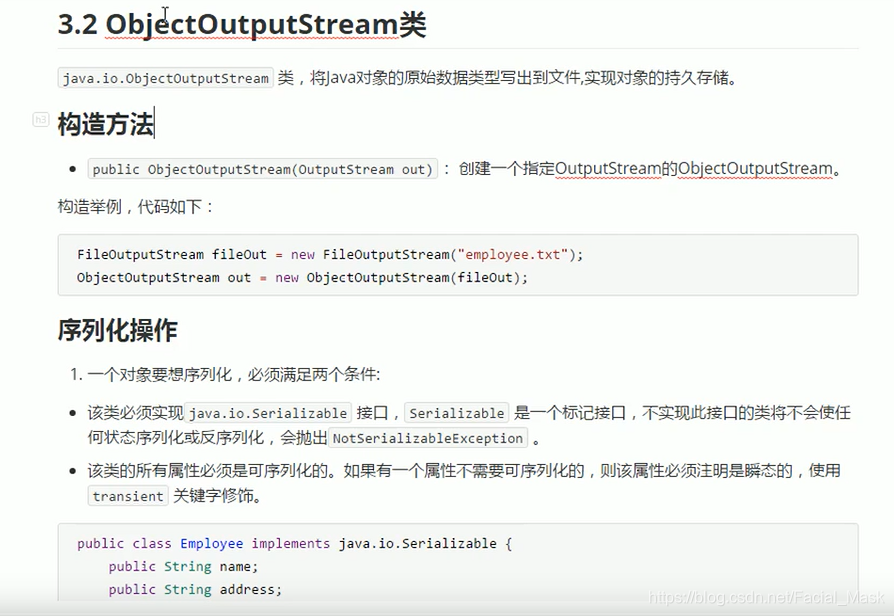


序列化接口是一种标记性接口
反序列化

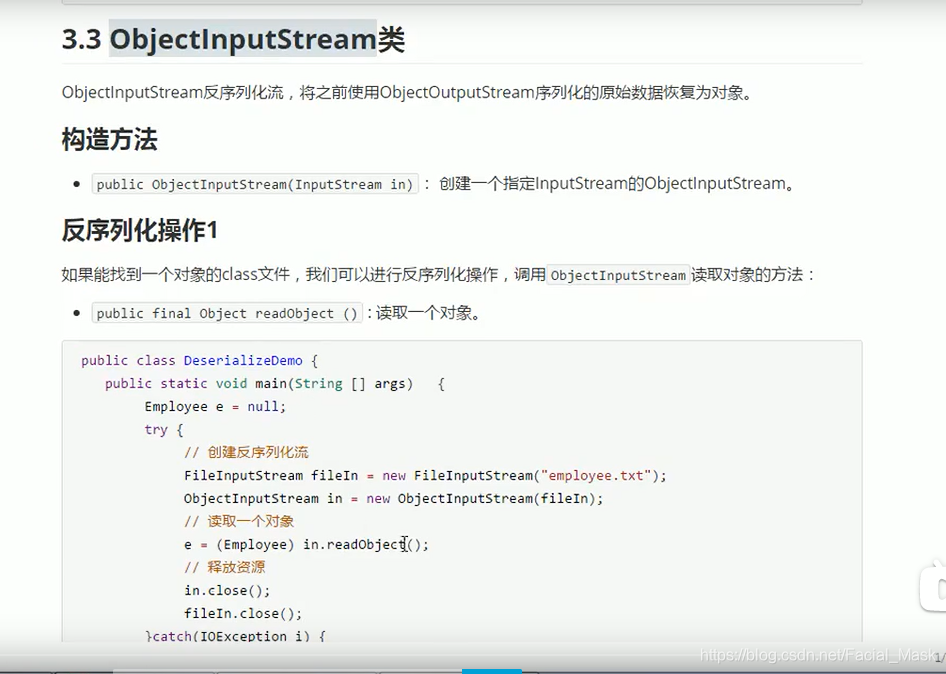
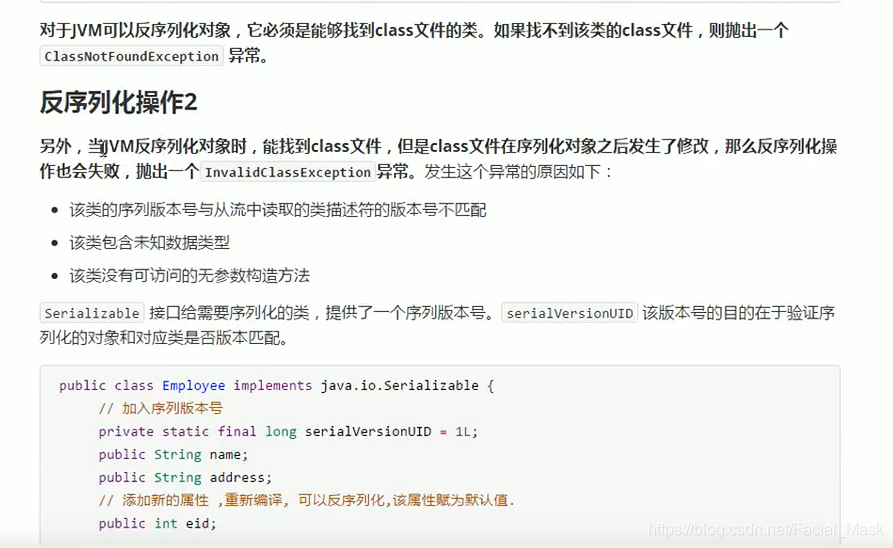
瞬态关键字 transient
静态的是不能被序列化的,
被transient修饰的成员变量也不能序列化,

被他修饰不能被序列化,就这么点东西。
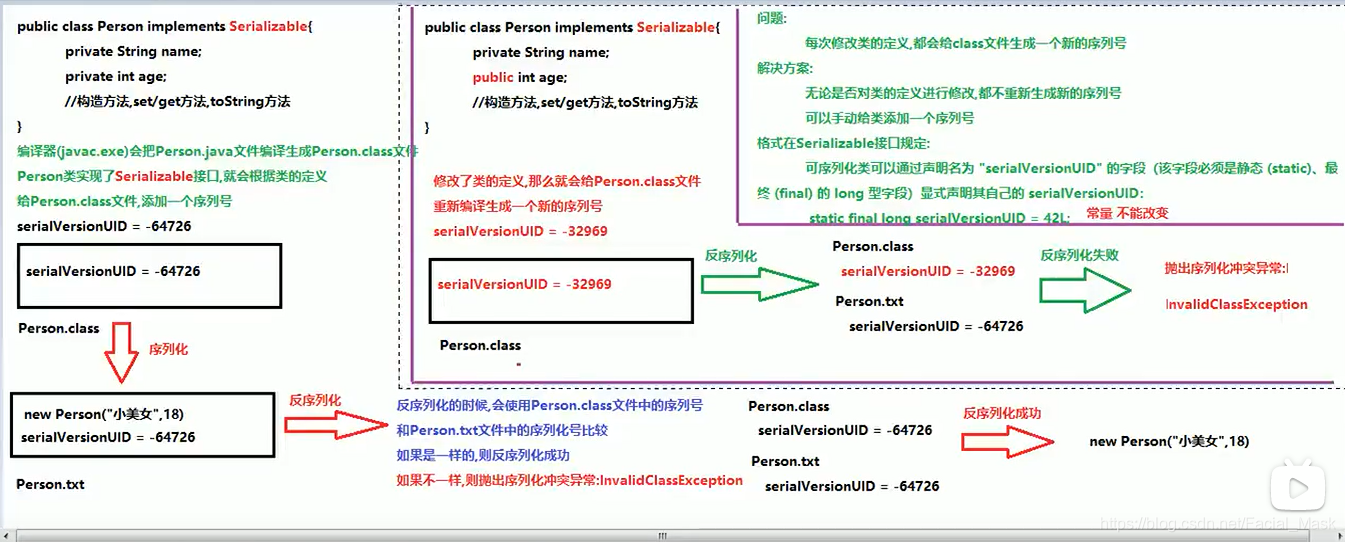
每次反序列化的时候都会验证一个class文件的 序列号和 序列化文件的序列号是否相同。
可以通过显示生命序列号的方法进行解决。
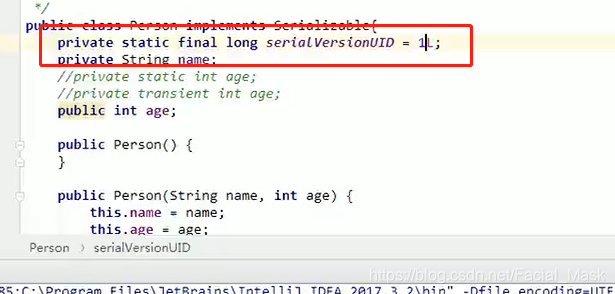
写这个值得目的在于不论我们如何更改我们的代码,我们的这个序列号都不会改变。这样的话,不论这个类怎么改,我都用的是这个序列号。
序列化集合
文件中保存多个对象的时候,我们可以吧多个对象存到一个集合中,对集合进行序列化和反序列化。目的:一次序列化多个对象
class ObjectOutputStreamTest{ public static void main(String[] args) throws IOException, ClassNotFoundException { ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("d:\\oos.txt"))); List<Teacher> list = new ArrayList<>(); list.add(new Teacher("小红","河北省石家庄市正定县")); list.add(new Teacher("aaa","河北省石家庄市正定县")); list.add(new Teacher("bbb","河北省石家庄市正定县")); list.add(new Teacher("ccc","河北省石家庄市正定县")); list.add(new Teacher("ddd","河北省石家庄市正定县")); oos.writeObject(list); oos.flush(); oos.close(); InputStream in; ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("d:\\oos.txt"))); List<Teacher> listTeachers = (List<Teacher>)ois.readObject(); ois.close(); for (Teacher listTeacher : listTeachers) { System.out.println(listTeacher.getAddr()); System.out.println(listTeacher.getName()); } //河北省石家庄市正定县 //小红 //河北省石家庄市正定县 //aaa //河北省石家庄市正定县 //bbb //河北省石家庄市正定县 //ccc //河北省石家庄市正定县 //ddd } }
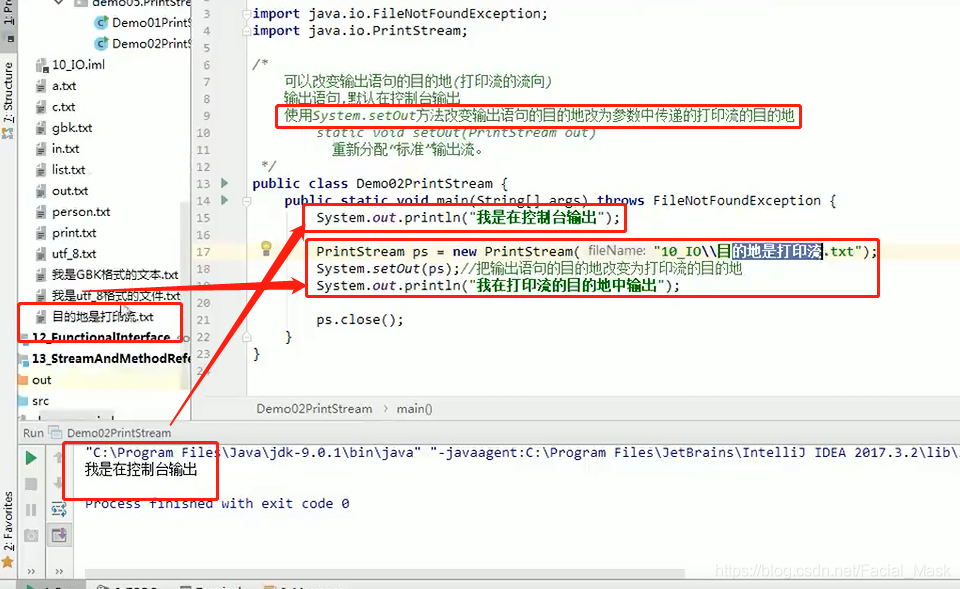
打印流PrintStream
打印流我们们天都在用
System.out.println
java.in.printStream 打印流:extends
特点:只负责数据的输出,不负责读取
这个流永远不会抛出ioException;
里边有特有的方法,println,print两个方法。
构造方法是

注意事项:
如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表 97-a,如果使用他自己的特有的print或者println方法写数据,写的数据原样输出,比方说写97打印的就是97