
本篇文章将介绍折半查找算法。
@[toc]
何为折半查找?
上一篇文章介绍了顺序查找算法,我们知道,虽然顺序查找算法适用性高,但效率太低,那么能不能在此基础上继续提高算法的效率呢?
这个时候,折半查找诞生了,它的原理是每次都将待查找的记录所在的区间缩小一半,比如:
若要在该序列中查找元素值4,折半查找是如何做到的呢?
它需要先设置两个游标,一个指向最左边,一个指向最右边: 这两个游标所表示的范围即为查找区间,初始我们在下标为1到10的区间内查找,这个查找也是讲究方法的,不是一个一个地去遍历查找。
这两个游标所表示的范围即为查找区间,初始我们在下标为1到10的区间内查找,这个查找也是讲究方法的,不是一个一个地去遍历查找。
我们还需要借助一个游标,用它来表示区间的中间位置:
这个mid表示的就是区间的中间位置,计算方法为:(low + high) / 2。
此时我们让待查找元素值与中间位置元素值比较,若相等,则查找成功,直接返回mid值;
若不相等,此时分为两种情况,待查找元素值比mid位置的元素值大或者比mid位置的元素值小。因为我们要查找的元素值为4,4 < 5,所以待查找的元素值肯定在mid位置的左边,此时我们缩小查找区间,让游标high指向mid的前一个位置:
此时要重新计算mid的值,(1 + 4) / 2 = 2,所以mid应该指向下标2的位置:
继续让待查找元素值与mid位置元素值比较,此时4 > 2,所以待查找元素值肯定在mid位置的右边,继续缩小查找区间,让游标low指向mid的后一个元素:
此时再次重新计算mid的值,(3 + 4) / 2 = 3,让mid指向下标为3的位置: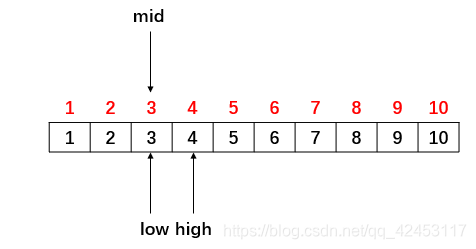
继续比较待查找元素值与mid位置的值,```4 > ,待查找元素值仍然在mid位置的右边,再次缩小区间,让low指向mid的后一个位置: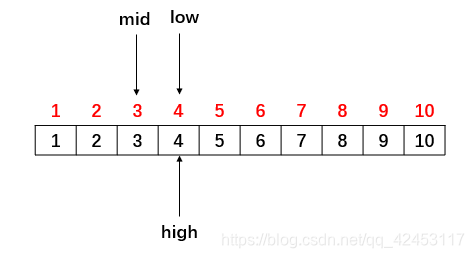
此时计算mid的值,(4 + 4) / 2: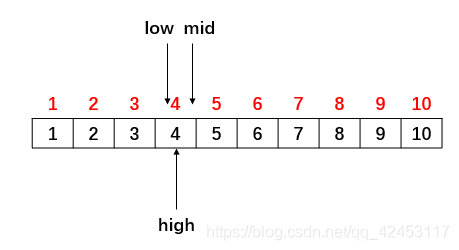
很巧的是三个游标指向了同一个位置,此时再比较,4 = 4,查找成功,返回mid的值为4。
我们再来查找一个序列中不存在的值,比如查找15,初始状态如下:
开始比较,15比mid位置的元素值大,说明待查找元素在mid位置的右边,缩小区间,让low指向mid位置的后一个元素,然后重新计算mid:
继续比较,15比mid位置的元素值大,继续缩小区间,重新计算mid: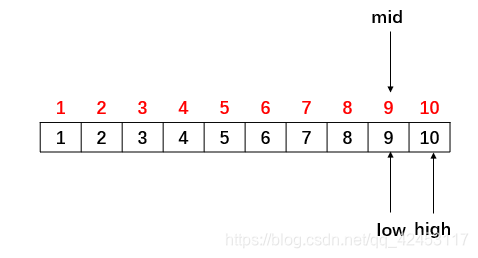
继续比较,15比mid位置的元素值大,继续缩小区间,重新计算mid: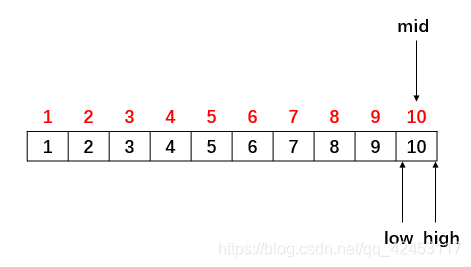
再次比较,15比mid位置的元素值大,此时再次缩小区间,游标low指向下标为11的位置,此时所有的区间均已查找完毕,所以查找的终止条件应为:low > high,若游标满足该条件,则证明查找失败。
算法实现
有了前面的分析铺垫,算法实现就会非常简单:
//折半查找算法
int BiSearch(SSTable st,int key){
int low,high,mid;
//为游标low、high设初始值
low = 1;
high = st.length;
while(low <= high){
//当low > high时退出循环
//计算游标mid的位置
mid = (low + high) / 2;
if(st.elem[mid].key == key){
//若当前位置元素值等于待查找元素值,查找成功,返回mid
return mid;
}else if(st.elem[mid].key < key){
//若当前位置元素值小于待查找元素值,则表示待查找元素值在当前位置的右边
low = mid + 1; //修改游标low
}else {
//此时说明待查找元素值在当前位置的左边
high = mid - 1; //修改游标high
}
}
return 0; //查找失败,返回0
}
递归实现
从分析折半查找的过程之后,大家可能就有感觉,这个查找算法是能够用递归实现的, 因为每次的查找过程是一样的,下面是递归的折半查找算法实现:
//折半查找算法递归实现
int BiSearch(SSTable st,int key,int low,int high){
int mid;
if(low > high){
//递归结束条件
return 0; //查找失败,返回0
}
//求出游标mid
mid = (low + high) / 2;
if(st.elem[mid].key == key){
//查找成功,返回mid
return mid;
}else if(st.elem[mid].key < key){
//此时待查找元素在mid位置的右边,递归调用
BiSearch(st,key,mid + 1,high); //修改游标low
}else{
//反之,修改游标high
BiSearch(st,key,low,mid - 1);
}
}
非常简单,不做过多解释。
效率分析
还是来分析一下折半查找算法的效率。
比如下面的一个序列:
我们知道,折半查找第一次去比较的是中间位置的元素,在该序列中,中间位置值为5,如果我们要查找的元素值就为5,那么只需比较一次即可;
若待查找元素值为3,则需要比较两次才能找到;
折半查找算法的效率同样受待查找元素值影响。
若我们把只需比较一次即可找到的元素5作为根结点形成一棵二叉树: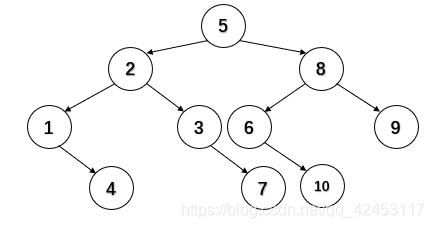
其中各个结点所在的层数即为比较此时,比如结点2在二叉树中的第二层,则需比较2次才能查找到元素2;结点7在第四层,则需比较4次才能查找到元素7。
所以每个元素值的比较次数都小于等于二叉树的深度,而根据二叉树性质可得出结论:
$$比较次数 ≤「log_2n」 + 1$$
由此还可以得出查找不成功的比较次数等于路径上的内部结点数,即:
$$比较次数 ≤「log_2n」 + 1$$
假定每个元素的查找概率相等,则查找成功时的平均长度为:
$$\frac{n + 1}{n}log_2(n + 1) - 1 ≈ log_2(n + 1) - 1$$
所以折半查找算法的时间复杂度为:logn。
总结一下,折半查找法的优点是:
效率比顺序查找高
但也有缺点:
只适用于顺序表,且限于顺序存储结构(对线性链表无效)
只适用于有序的序列

