 algorain
algorain
algorain_个人页
algorain

文章
8
问答
2
视频
0
个人介绍
暂无个人介绍
擅长的技术
- 微服务
- Java
获得更多能力

通用技术能力:
暂时未有相关通用技术能力~
云产品技术能力:
-
Clouder
-
Apsara Clouder基础技能认证:阿里巴巴编码规范
获得于2019-07-23 11:38:23
-
Apsara Clouder基础技能认证:阿里巴巴编码规范
阿里云技能认证
详细说明
暂无更多信息
2023年08月
-
08.13 22:06:53
 发表了文章
2023-08-13 22:06:53
发表了文章
2023-08-13 22:06:53
consul安装启动流程
consul安装启动流程 -
08.10 20:16:27
 回答了问题
2023-08-10 20:16:27
回答了问题
2023-08-10 20:16:27
如何训练属于自己的“通义千问”呢?
赞22 踩0 评论0 -
08.10 19:49:06发表了文章
2023-08-10 19:49:06
通义千问开源模型免费部署使用
使用modelScope部署通义千问模型 -
08.07 21:06:09发表了文章
2023-08-07 21:06:09
梳理日常开发涉及的负载均衡
负载均衡是当前分布式微服务时代最能提及的词之一,出于对分层、解耦、弱依赖、可配置、可靠性等概念的解读,一对一的模式变得不再可信赖,千变万化的网络环境中,冗余和备份显得格外重要
2023年07月
-
07.17 23:09:36发表了文章
2023-07-17 23:09:36
简易注册中心监控NAS断电断网
日常使用NAS过程中,偶尔会出现家里断电或者断网的情况,NAS自带网络断开的通知功能,但需要是恢复网络链接后才会通知,而此时都恢复了,再通知也就没那么重要,还有断电情况下也是需要回家才能知道,断电保护可以使用UPS,当停电后UPS通过usb数据线会给NAS发送通知 -
07.12 21:59:23发表了文章
2023-07-12 21:59:23
阿里云Redis与Tair压力测评
无意中发现阿里云开发社区的训练营活动,其中有一个7天玩转Redis、tair训练营计划,里面可以免费领取三个月的试用礼包,因为是参营任务,不领取都不行的那种,领取之后放着也是放着,不如跑跑数据看看Redis和Tair的性能有什么区别,简单的压力测试下,本次测试并不精确,也不具有太多参考意义,真的就是为了测试而测试。 -
07.09 22:31:03回答了问题
2023-07-09 22:31:03
在关系型数据库中,主键是什么意思?
赞2 踩0 评论1 -
07.09 20:21:55发表了文章
2023-07-09 20:21:55
BFF网关模式开发指南
BFF是近些年新衍生出来的一种开发模式,或者说是一种适配模式的系统,BFF全称为Backend OF Front意为后端的前端,为了适配微服务模式下前端后端系统接口调用混乱而出现的。在如今微服务盛行的趋势下,大型系统中划分出了数十个服务模块,例如商品,门店,运费,红包,订单,优惠券,CMS,用户,搜索,推荐,广告等等系统,前端也有小程序,APP,网页等端。由此产生了很多问题: -
07.07 10:41:07发表了文章
2023-07-07 10:41:07
python解析考试题库数据
应单位要求需要参加某个考试,但考试需要从手机端登陆学习,1000多道题需要挨个刷一遍太过于麻烦,萌生了把题目和答案全部扒下来的想法,再用python做数据的清洗和梳理,最后整合出来所有的考试题库信息。 -
07.06 21:14:49发表了文章
2023-07-06 21:14:49
面试题分析:统计网站访问次数
平台的访问量非常高,需要实时统计网站的访问次数,请设计一个计数器解决: 初级工程师,可能回答使用synchronized锁或重入锁,进一步探讨,synchronized锁太重,有没其他方式,可能回答atomic类,进一步问,atomic类原理,什么场景下适合用,什么场景下不适合用 atomic和synchronized都是单机方案,当一个服务器不能满足性能要求时,线上使用集群,如何在集群场景下实现计数器
-
发表了文章
2023-08-13
consul安装启动流程
-
发表了文章
2023-08-10
通义千问开源模型免费部署使用
-
发表了文章
2023-08-07
梳理日常开发涉及的负载均衡
-
发表了文章
2023-07-17
简易注册中心监控NAS断电断网
-
发表了文章
2023-07-12
阿里云Redis与Tair压力测评
-
发表了文章
2023-07-09
BFF网关模式开发指南
-
发表了文章
2023-07-07
python解析考试题库数据
-
发表了文章
2023-07-06
面试题分析:统计网站访问次数
滑动查看更多
-
回答了问题
2023-08-10
如何训练属于自己的“通义千问”呢?
首先可以参考modelScope社区给出的使用文档,已经足够全面
https://modelscope.cn/models/qwen/Qwen-7B-Chat/quickstart
但在按照文档中步骤部署时,还是有些错误问题发生,可以搜索参考的解决方式不多,所以记录下来
个人电脑部署
这里不太建议使用自己的笔记本部署通义千问模型,因为实在是太耗资源,我使用的M2芯片的MacBook Pro即使运行起来了,但模型回答一个问题都需要四五分钟的时间,内存全部占满,其他应用程序也都强制退出了。所以还是使用社区提供的免费资源,或者有更高配置的服务器来部署模型。而且期间还有各种问题,搜了很多github上的问答才解决,耗时耗力,这里就不记录了,很不推荐这种方式。
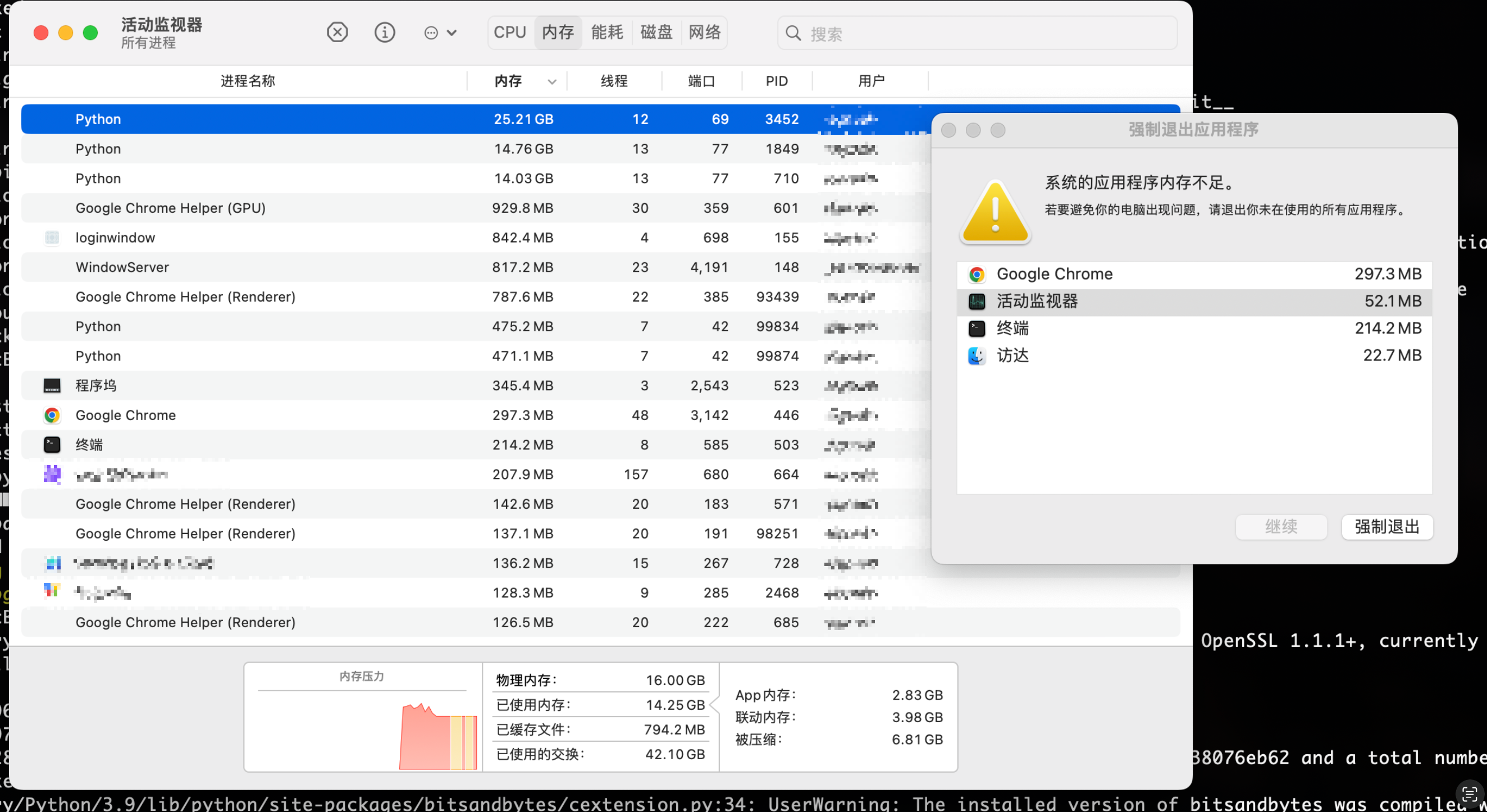
免费算力服务器
打开modelScope社区后,点击登录注册可以看到免费赠送算力的活动

注册完成后在对应模型里可以看到,随时都能启用的服务器

这里CPU环境的服务器勉强可以跑起来模型,但运行效果感人,而且配置过程中有各种问题需要修改,而GPU环境启动模型可以说是非常流畅,体验效果也很好
CPU环境启动
社区提供的服务器配置已经很高了,8核32G,但因为是纯CPU环境,启动过程中还是有些问题
安装依赖包
第一行命令不需要运行,服务器已经自带了modelscope包

只需要新建一个Terminal窗口来执行第二条命令

启动代码
直接运行文档提供的代码会报错,这里是因为纯CPU环境导致的

错误 1
RuntimeError: "addmm_implcpu" not implemented for 'Half'Hide Error Details
RuntimeError: "addmm_impl_cpu_" not implemented for 'Half' --------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) Cell In[1], line 8 5 model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',device_map="auto", trust_remote_code=True,fp16 = True).eval() 6 model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat",revision = 'v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参 ----> 8 response, history = model.chat(tokenizer, "你好", history=None) 9 print(response) 10 response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history) File ~/.cache/huggingface/modules/transformers_modules/Qwen-7B-Chat/modeling_qwen.py:1010, in QWenLMHeadModel.chat(self, tokenizer, query, history, system, append_history, stream, stop_words_ids, **kwargs) 1006 stop_words_ids.extend(get_stop_words_ids( 1007 self.generation_config.chat_format, tokenizer 1008 )) 1009 input_ids = torch.tensor([context_tokens]).to(self.device) -> 1010 outputs = self.generate( 1011 input_ids, 1012 stop_words_ids = stop_words_ids, 1013 return_dict_in_generate = False, 1014 **kwargs, 1015 ) 1017 response = decode_tokens( 1018 outputs[0], 1019 tokenizer, (...) 1024 errors='replace' 1025 ) 1027 if append_history:错误 2
ValueError: The current
device_maphad weights offloaded to the disk. Please provide anoffload_folderfor them. Alternatively, make sure you havesafetensorsinstalled if the model you are using offers the weights in this format.Hide Error DetailsValueError: The current `device_map` had weights offloaded to the disk. Please provide an `offload_folder` for them. Alternatively, make sure you have `safetensors` installed if the model you are using offers the weights in this format. --------------------------------------------------------------------------- ValueError Traceback (most recent call last) Cell In[2], line 5 2 from modelscope import GenerationConfig 4 tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',trust_remote_code=True) ----> 5 model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',device_map="auto", trust_remote_code=True,fp16 = True).eval() 6 model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat",revision = 'v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参 7 model.float() File /opt/conda/lib/python3.8/site-packages/modelscope/utils/hf_util.py:98, in get_wrapped_class.<locals>.ClassWrapper.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs) 95 else: 96 model_dir = pretrained_model_name_or_path ---> 98 model = module_class.from_pretrained(model_dir, *model_args, 99 **kwargs) 100 model.model_dir = model_dir 101 return model解决方式
首先确保torch 2.0.1版本,然后在代码中添加这两行,即可运行
model.float()
offload_folder="offload_folder",
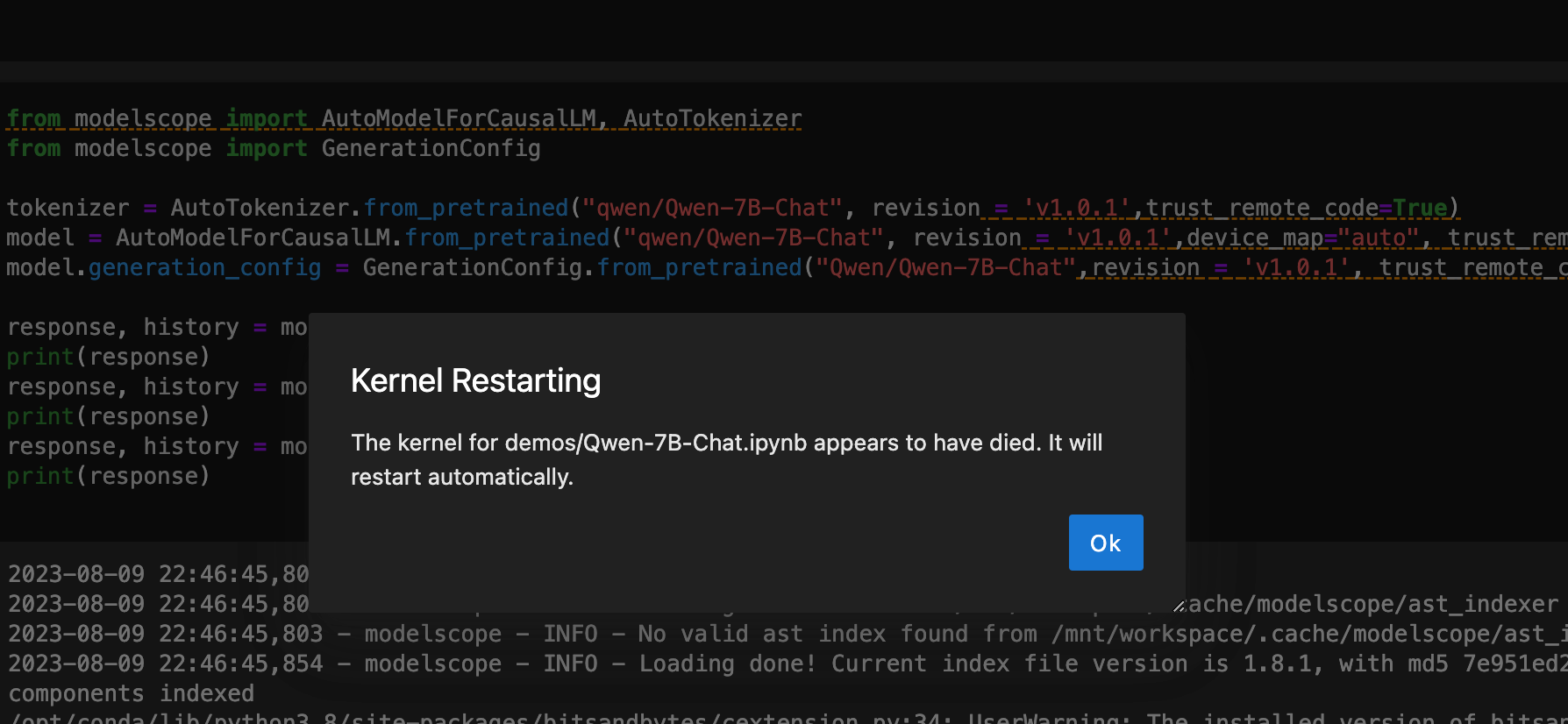
from modelscope import AutoModelForCausalLM, AutoTokenizer from modelscope import GenerationConfig import datetime print("启动时间:" + str(datetime.datetime.now())) tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision = 'v1.0.5',device_map="auto",offload_folder="offload_folder", trust_remote_code=True,fp16 = True).eval() model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat",revision = 'v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参 model.float() print("开始执行:" + str(datetime.datetime.now())) response, history = model.chat(tokenizer, "你好", history=None) print(response) print("第一个问题处理完毕:" + str(datetime.datetime.now())) response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history) print(response) print("第二个问题处理完毕:" + str(datetime.datetime.now())) response, history = model.chat(tokenizer, "它有什么好玩的景点", history=history) print(response) print("第三个问题处理完毕:" + str(datetime.datetime.now()))运行起来之后速度实在感人,没回答一个问题都需要 5 分钟左右,还有一定概率直接启动失败

启动模型过程中会出现这种报错,点击OK重新执行就好了,可能是服务器负载太高
 赞22 踩0 评论0
赞22 踩0 评论0 -
回答了问题
2023-07-09
在关系型数据库中,主键是什么意思?
在数据表中主键是指能够唯一标识表中每条记录的关键特征。
主键的特点包括:- 主键的值必须唯一,用于区分表中的不同记录
- 每个表都必须有主键
- 主键列不允许包含空值
- 一张表中只能有一个主键
设置主键的目的是为了唯一标识表中的每条记录,以便于快速查询数据。选择合适的主键对于数据库的设计尤为重要,通常优先考虑业务含义较强的列作为主键,例如用户ID,学号等。但不建议使用uuid这样的字符串作为主键,因为要考虑主键的性能。
赞2 踩0 评论1
滑动查看更多
暂无更多信息