今天更好了吗?_个人页


文章
0
问答
311
视频
0
个人介绍
暂无个人介绍
擅长的技术

-
 提交了问题
2022-04-01
提交了问题
2022-04-01
在一些在线数据库服务中,关系型数据库服务是什么呢?
-
提交了问题
2022-04-01
在构建运营商行业数据时,它的架构特点是什么呢?
-
提交了问题
2022-04-01
在构建云关系型数据中,对游戏行业的挑战都有哪些呢?
-
提交了问题
2022-04-01
Saas多租户解决方案中,常见的 Saas 设计模式都有哪些呢?
-
提交了问题
2022-04-01
区别于传统模式,Saas模式的优势在哪里呢?
-
提交了问题
2022-04-01
在新零售行业中,为什么要采用大促营销的解决方案呢?
-
提交了问题
2022-04-01
在构架云关系型数据库时,大促营销解决方案的价值在哪里呢?
-
提交了问题
2022-04-01
在构建云关系型数据库时,RDS服务高可用的解决方案的内容是什么呢?
-
提交了问题
2022-04-01
基于安全可靠的特点,解决数据安全的方案主要有哪些呢?
-
提交了问题
2022-04-01
在新零售行业数据库中,为什么要提供ISV支持呢?
-
提交了问题
2022-04-01
新零售行业的特点中,运维便捷是指要为客户提供哪些服务呢?
-
提交了问题
2022-04-01
在新零售行业数据库的特点中,有哪些是需要特别关注的呢?
-
提交了问题
2022-03-28
sentinel是怎样保护服务的稳定性的呢?
-
提交了问题
2022-03-28
阿里的开源组件包括哪些呢?
-
提交了问题
2022-03-28
spring cloud 的优点是什么或者说它的作用是什么呢?
-
提交了问题
2022-03-28
spring cloud 是什么呢?
-
提交了问题
2022-03-28
dubbo缺省会出现什么情况呢?
-
提交了问题
2022-03-28
为什么需要用到中间件维护服务地址呢?
-
提交了问题
2022-03-28
dubbo的基本架构是什么呢?
-
提交了问题
2022-03-28
ribbon是如何工作的呢?
-
提交了问题
2022-03-28
ribbon的作用是什么呢?
-
提交了问题
2022-03-28
负载均衡的核心原理是什么呢?
-
提交了问题
2022-03-28
nacos目前的应用范围是哪里呢?
-
提交了问题
2022-03-28
Ingress-nginx是如何迁移的呢?
-
提交了问题
2022-03-28
云原生时代对于网关的优势在哪里呢?
-
提交了问题
2022-03-28
高扩展指的是什么呢?
-
提交了问题
2022-03-28
如何看Tegine与Envoy是否可以满足我们的业务需求呢?
-
提交了问题
2022-03-28
如何判断网关产品具有丰富的可观测性呢?
-
提交了问题
2022-03-28
传统网关是怎样进行部署的呢?
-
提交了问题
2022-03-28
如何解决网关的集群规模非常大时,不能随意地做reload呢?
-
提交了问题
2022-03-28
为什么我们说配置的热更新是非常重要的呢?
-
提交了问题
2022-03-28
CTO1本地生活战役的业务目标是什么呢?
-
提交了问题
2022-03-28
dubbo的局限性在哪里呢?
-
提交了问题
2022-03-28
注册中心的头部信息时,应注意什么?
-
提交了问题
2022-03-28
为什么要清理迁移配置呢?
-
提交了问题
2022-03-28
如何动态调整服务注册和订阅方式呢?
-
提交了问题
2022-03-28
什么情况下需要修改Ribbon组件呢?
-
提交了问题
2022-03-28
Spring Cloud 应用如何保证业务不停机的情况下无缝迁移到MSE?
-
提交了问题
2022-03-28
Dubbo 应用如何保证业务不停机的情况下无缝迁移到MSE?
-
提交了问题
2022-03-28
为什么要开源nacos呢?
-
提交了问题
2022-03-28
对于单个租户来说,如何创建namespace呢?
-
提交了问题
2022-03-28
namespace的设计目的是什么?
-
提交了问题
2022-03-28
nacos配置管理的基础模型是什么呀?
-
提交了问题
2022-03-28
异地多活主要应用于哪些领域呢?
-
提交了问题
2022-03-28
阿里云MSHA的是怎样工作的呢?
-
提交了问题
2022-03-28
如何能在性能、高可用和资源利用之间取得最大平衡呢?
-
提交了问题
2022-03-28
什么情况下选择PTS+MSE+AHAS+ARMS+ACKZ组合呢?
-
提交了问题
2022-03-28
nacos-sync组件在那些场景中使用呢?
-
提交了问题
2022-03-28
云原生网关在实际的应用有哪些呀?
-
提交了问题
2022-03-28
云原生网关是怎么样构建的呀?
暂无更多信息
暂无更多信息
-
 回答了问题
2023-05-07
回答了问题
2023-05-07
datawork中如何管理模型创建模型呢?
1.打开DDM客户端。单击开始菜单栏中的新建,弹出新建模型对话框。
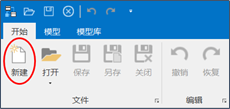 2.选择好目标模型后,单击确定,在模型树上会创建一个新的模型,您可以在模型中添加表/实体、字段/属性等元素。
2.选择好目标模型后,单击确定,在模型树上会创建一个新的模型,您可以在模型中添加表/实体、字段/属性等元素。 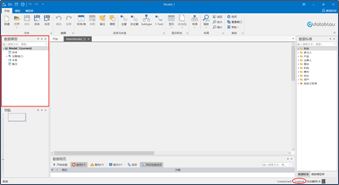 赞0 踩0 评论0
赞0 踩0 评论0 -
回答了问题
2022-04-01
在构建数据库的过程中,将关系型数据库分为哪几个部分呢?
主要分为三大功能模块:客户端的数据库访问接口、服务器端的SQL引擎模块与存储引擎模块。
赞0 踩0 评论0 -
回答了问题
2022-04-01
基于不同的数据模型,可以将数据库分为哪几种呢?
基于不同的数据模型,数据库主要分为关系型和非关系型。关系型数据库采用二维关系表组织和存储数据,采用统一的SQL查询语言,支持事务处理的ACID特性,数据结构化高,冗余度低;分为传统关系型、分布式关系型,以及整合SQL和NoSQL优势同时支持OLTP与OLAP系统的NewSQL。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在电力营销算费业务数据库中,为什么要缓存 Tair 的价值呢?
算费中间结果性能大幅度提升
减少业务对底层关系库的依赖,业务逻辑解耦。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在新一代算费业务架构中,为什么要选择 Polar DB-X 呢?
高并发的数据读写能力
水平扩展架构
海量数据存储能力
数据强一致性保证
赞0 踩0 评论0 -
回答了问题
2022-04-01
在关系型数据库中,oracle 和 mysql 两者的区别在哪里呢?
oracle:通常会创建一个数据库,数据库中包含多个用户。不同用户下会有好多表。一般就创建一个数据库用。
oracle:通常会创建一个数据库,数据库中包含多个用户。不同用户下会有好多表。oracle:通常会创建一个数据库,数据库中包含多个用户。不同用户下会有好多表。一般就创建一个数据库用。
mysql:它的默认用户是root,在用户下创立许多数据库,数据库下还有好多表。一般情况下,就用默认用户,不会创建多个用户。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在交通物流行业的业务改造中,X-Engine 是什么呢?
在交通物流行业的业务改造中,X-Engine是阿里云数据库产品事业部自我研发的关联计算机的业务,它的目的是储存和处置数据库的引擎装置。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在云原生多模数据库中,lindorm主要提供哪些服务呢?
云原生多模数据库Lindorm提供各规模、多模型的云原生数据库服务。它可以·同时容纳HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多个开源的标准接口。同时,也适用于大量数据的成本低、性能存储高处理,并且弹性按需付费。
赞0 踩0 评论0 -
回答了问题
2022-04-01
PolarDB Share Nothing & Everything 的结构一体化优势在哪里呢?
一、Leverage PolarDB已经共享了基础设施,存储、管控、监控、审计这些功能;
二、Share Nothing以存储计算分离架构基础,不断扩展,不需要数据就可以迁移,减轻了传统分布式的Data Skew问题;
三、Share Everything场景写瓶颈大幅缓解,多节点可写;
赞0 踩0 评论0 -
回答了问题
2022-04-01
在云原生数据库中,PolarDB-X的技术架构是什么呢?
PolarDB-X联合harding On MySQL、NewSQL等多个数据理念,具有云原生分布式的特点,在底层中运用了PolarDB云原生数据库的技术,上层中,也采取了许多分布式技术。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在构建数据库的过程中,AnalyticDB 对于企业数据化的建设有什么作用呢?
AnalyticDB可以通过SQL,建构关系型数据仓库。具有管理简单、节点数量伸缩方便等优点,支持丰富的可视化工具以及ETL软件,降低了企业建设数据化的程度。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在数据存储方面,分析型数据库的工作原理是什么呢?
在数据存储模型中,采取关系模型储存数据,使用SQL计算分析,不用提前建模。采用云端的伸缩能力,AnalyticDB许多量级的数据时,实现真正地快速计算。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在构建数仓数据中,分析型数据库是什么呢?
阿里云分析型数据库,也可以叫AnalyticDB,是云端托管的PB级高并发实时数据仓库,是专注于服务OLAP领域的数据仓库。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在运营商行业中,分布式改造中的垂直拆分是怎样进行的呢?
进行垂直拆分,按照原来的业务系统,将原来整体的系统拆分成多个系统。系统内部数据都是自己包含的,并且不会与其他系统共用一个数据库,系统与系统之间的相互联通是通过暴露和调用服务来实现的。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在数据结构的映射中,怎样找到redis数据的二级索引呢?
我们把redis数据结构拆分为meta和data两类,进行不同的编码,通过meta可以去找到其对应的data,也即二级索引。
赞0 踩0 评论0 -
回答了问题
2022-04-01
如何应对 redis 带来的挑战,提高全量同步的效率呢?
需要对rocksdb进行改造,给予高性能的存储引擎TairDB,并完成redis数据结构向kv的简单反映,使redis数据能够存储在磁盘上;使用阿里云ESSD高效云盘为存储底座,利用云盘快照进行备份和全量同步,避免fork带来的问题并提高全量同步效率。
赞0 踩0 评论0 -
回答了问题
2022-04-01
为什么要结合新技术新硬件,推出 Tair 持久存储系列的数据库呢?
一、所有的Redis数据都储存在内存之上,带来成本高的问题。
二、对于支持储存大量数据也有许多缺点,比如在AOFREWRITE和生成RDB快照时会有较高的latency spike,在大数据中同步的耗时较长、容易失败。
赞0 踩0 评论0 -
回答了问题
2022-04-01
与 DTS 双向同步相比,全球多活的优势在哪儿呢?
全球多活的延迟稳定性高,波动比较小。Replicator配备有独立的资源,如果出现源端的写入量较大的情况,依旧能够快速获取到等待同步的数据(T1+T2的时延基本稳定在400毫秒)。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在 Redis 全球多活中,负载分离是应用于哪些方面的呢?
在一些比如大型促销的场景下,预测可能会有会有超大的QPS请求和访问流量,可其分摊至多个子实例,突破单个实例的负载限制。
赞0 踩0 评论0 -
回答了问题
2022-04-01
在业务分布较广时,全球多活功能有什么优势呢?
在业务分布较广时,全球多活可以建立或确定需要同步的子实例,不用通过业务自身过杂的设计来完成,这就降低业务设计的复杂程度,让用户专注于上层业务的开发。可提供跨域复制能力,快速实现数据异地灾备和多活。
赞0 踩0 评论0
滑动查看更多
暂无更多信息