






暂时未有相关云产品技术能力~
大家好,我是Echo_Wish,在大数据、运维和人工智能领域有着丰富的学习和实践经验。我专注于数据分析、系统运维和AI应用,掌握了Python、.NET、C#、TensorFlow等技术。在我的微信公众号“CYN数维智汇”上,分享这些领域的实战心得和前沿知识,欢迎关注,一起探索科技的无限可能!
2024年05月
 发表了文章
2024-02-22 20:45:29
发表了文章
2024-02-21 00:28:10
发表了文章
2024-02-19 10:29:13
发表了文章
2024-02-17 13:46:12
发表了文章
2024-02-16 11:39:11
发表了文章
2024-02-15 21:33:44
发表了文章
2024-02-14 22:23:59
发表了文章
2024-02-13 15:05:28
发表了文章
2024-02-12 20:46:20
发表了文章
2024-02-11 20:35:55
发表了文章
2024-02-10 09:24:30
发表了文章
2024-02-09 15:11:55
发表了文章
2024-02-08 21:18:10
发表了文章
2024-02-07 14:08:59
发表了文章
2024-02-06 17:26:56
发表了文章
2024-02-05 15:35:19
发表了文章
2024-02-04 11:40:42
发表了文章
2024-02-03 22:55:29
发表了文章
2024-02-02 12:49:45
发表了文章
2024-02-01 09:12:31
发表了文章
2024-01-31 21:49:04
发表了文章
2024-01-30 10:58:01
发表了文章
2024-01-29 08:44:48
发表了文章
2024-01-28 13:10:48
发表了文章
2024-01-27 09:01:42
发表了文章
2024-01-26 08:48:35
发表了文章
2024-01-25 08:56:00
发表了文章
2024-01-24 08:46:29
发表了文章
2024-01-23 12:44:46
发表了文章
2024-01-22 08:31:20
发表了文章
2024-01-21 10:21:54
发表了文章
2024-01-20 09:39:37
发表了文章
2024-01-19 00:06:17
发表了文章
2024-02-22 20:45:29
发表了文章
2024-02-21 00:28:10
发表了文章
2024-02-19 10:29:13
发表了文章
2024-02-17 13:46:12
发表了文章
2024-02-16 11:39:11
发表了文章
2024-02-15 21:33:44
发表了文章
2024-02-14 22:23:59
发表了文章
2024-02-13 15:05:28
发表了文章
2024-02-12 20:46:20
发表了文章
2024-02-11 20:35:55
发表了文章
2024-02-10 09:24:30
发表了文章
2024-02-09 15:11:55
发表了文章
2024-02-08 21:18:10
发表了文章
2024-02-07 14:08:59
发表了文章
2024-02-06 17:26:56
发表了文章
2024-02-05 15:35:19
发表了文章
2024-02-04 11:40:42
发表了文章
2024-02-03 22:55:29
发表了文章
2024-02-02 12:49:45
发表了文章
2024-02-01 09:12:31
发表了文章
2024-01-31 21:49:04
发表了文章
2024-01-30 10:58:01
发表了文章
2024-01-29 08:44:48
发表了文章
2024-01-28 13:10:48
发表了文章
2024-01-27 09:01:42
发表了文章
2024-01-26 08:48:35
发表了文章
2024-01-25 08:56:00
发表了文章
2024-01-24 08:46:29
发表了文章
2024-01-23 12:44:46
发表了文章
2024-01-22 08:31:20
发表了文章
2024-01-21 10:21:54
发表了文章
2024-01-20 09:39:37
发表了文章
2024-01-19 00:06:17
 发表了文章
2024-01-18 08:57:09
发表了文章
2024-01-17 08:57:21
发表了文章
2024-01-16 12:25:11
发表了文章
2024-01-18 08:57:09
发表了文章
2024-01-17 08:57:21
发表了文章
2024-01-16 12:25:11
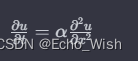
2024年02月
 回答了问题
2024-02-22 20:52:18
回答了问题
2024-02-21 00:22:14
回答了问题
2024-02-21 00:21:49
回答了问题
2024-02-13 21:27:15
回答了问题
2024-02-04 11:59:07
回答了问题
2024-02-04 11:46:26
回答了问题
2024-02-22 20:52:18
回答了问题
2024-02-21 00:22:14
回答了问题
2024-02-21 00:21:49
回答了问题
2024-02-13 21:27:15
回答了问题
2024-02-04 11:59:07
回答了问题
2024-02-04 11:46:26
2024年01月
回答了问题
2024-01-30 11:04:43
回答了问题
2024-01-29 15:00:04
回答了问题
2024-01-26 14:30:14
回答了问题
2024-01-24 08:43:34
回答了问题
2024-01-23 17:01:21
回答了问题
2024-01-19 15:44:34
回答了问题
2024-01-16 13:18:14
回答了问题
2024-01-16 13:13:52
发表了文章
2025-11-29
发表了文章
2025-11-29
发表了文章
2025-11-29
发表了文章
2025-11-28
发表了文章
2025-11-28
发表了文章
2025-11-28
发表了文章
2025-11-27
发表了文章
2025-11-27
发表了文章
2025-11-27
发表了文章
2025-11-26
发表了文章
2025-11-26
发表了文章
2025-11-25
发表了文章
2025-11-25
发表了文章
2025-11-25
发表了文章
2025-11-24
发表了文章
2025-11-24
发表了文章
2025-11-24
发表了文章
2025-11-23
发表了文章
2025-11-23
发表了文章
2025-11-21
 回答了问题
2025-10-29
回答了问题
2025-10-29
回答了问题
2025-10-29
回答了问题
2025-09-04
回答了问题
2025-09-04
回答了问题
2025-08-14
回答了问题
2025-08-01
回答了问题
2025-07-22
回答了问题
2025-07-07
回答了问题
2025-07-02
回答了问题
2025-06-10
回答了问题
2025-05-28
回答了问题
2025-05-19
回答了问题
2025-05-05
回答了问题
2025-04-22
回答了问题
2025-04-14
回答了问题
2025-04-14
回答了问题
2025-04-09
回答了问题
2025-04-09
回答了问题
2025-04-09
回答了问题
2025-10-29
回答了问题
2025-10-29
回答了问题
2025-10-29
回答了问题
2025-09-04
回答了问题
2025-09-04
回答了问题
2025-08-14
回答了问题
2025-08-01
回答了问题
2025-07-22
回答了问题
2025-07-07
回答了问题
2025-07-02
回答了问题
2025-06-10
回答了问题
2025-05-28
回答了问题
2025-05-19
回答了问题
2025-05-05
回答了问题
2025-04-22
回答了问题
2025-04-14
回答了问题
2025-04-14
回答了问题
2025-04-09
回答了问题
2025-04-09
回答了问题
2025-04-09





