邻居的尾巴

已加入开发者社区1793天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝

暂无个人介绍
暂无精选文章
暂无更多信息
2022年05月
-
05.30 20:09:57
 发表了文章
2022-05-30 20:09:57
发表了文章
2022-05-30 20:09:57
测试平台系列(81) 编写在线执行Redis功能
编写在线执行Redis功能
-
05.30 20:08:18发表了文章
2022-05-30 20:08:18
测试平台系列(80) 封装Redis客户端
封装Redis客户端
-
05.30 20:06:39发表了文章
2022-05-30 20:06:39
测试平台系列(79) 编写Redis配置功能(下)
编写Redis配置功能(下)
-
05.30 20:05:45发表了文章
2022-05-30 20:05:45
测试平台系列(78) 编写Redis配置管理功能(上)
编写Redis配置管理功能(上)
-
05.30 19:40:43发表了文章
2022-05-30 19:40:43
测试平台系列(77) 完善测试计划页面
完善测试计划页面
-
05.30 19:38:23发表了文章
2022-05-30 19:38:23
测试平台系列(76) 编写测试计划前端部分
编写测试计划前端部分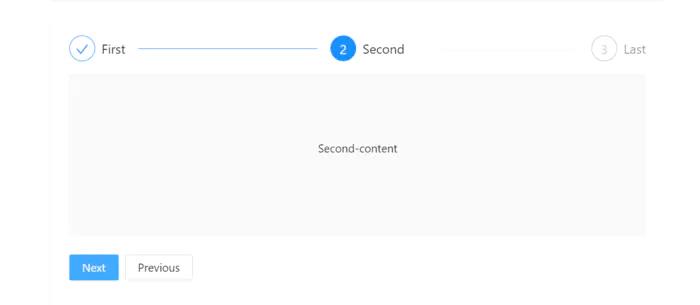
-
05.30 19:37:24发表了文章
2022-05-30 19:37:24
测试平台系列(75) 完善测试计划的删改查功能
测试平台系列(75) 完善测试计划的删改查功能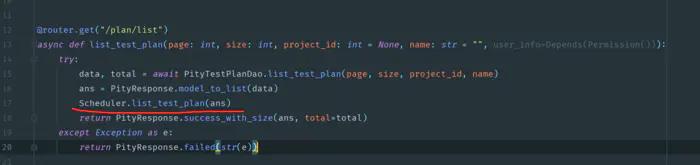
-
05.30 19:36:01发表了文章
2022-05-30 19:36:01
测试平台系列(74) 测试计划定时执行初体验
测试计划定时执行初体验
-
05.30 19:34:29发表了文章
2022-05-30 19:34:29
FastApi下载文件
FastApi下载文件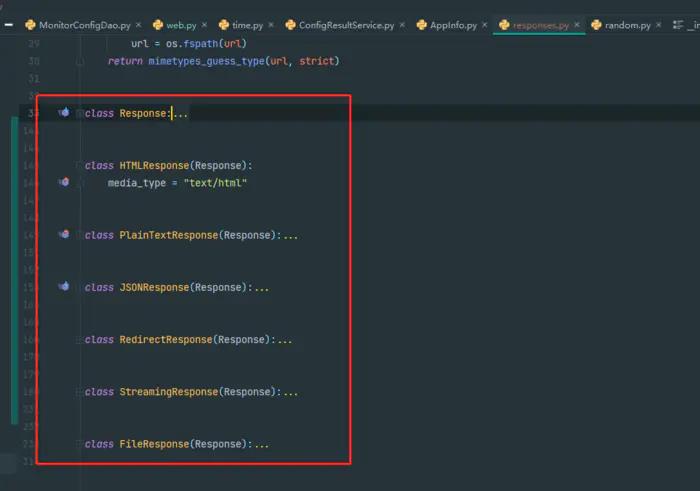
-
05.30 19:09:23发表了文章
2022-05-30 19:09:23
Python Excel工具类封装, 给excel表头搞点颜色
Python Excel工具类封装, 给excel表头搞点颜色
-
05.30 19:08:53发表了文章
2022-05-30 19:08:53
测试平台系列(73) 设计测试计划功能
设计测试计划功能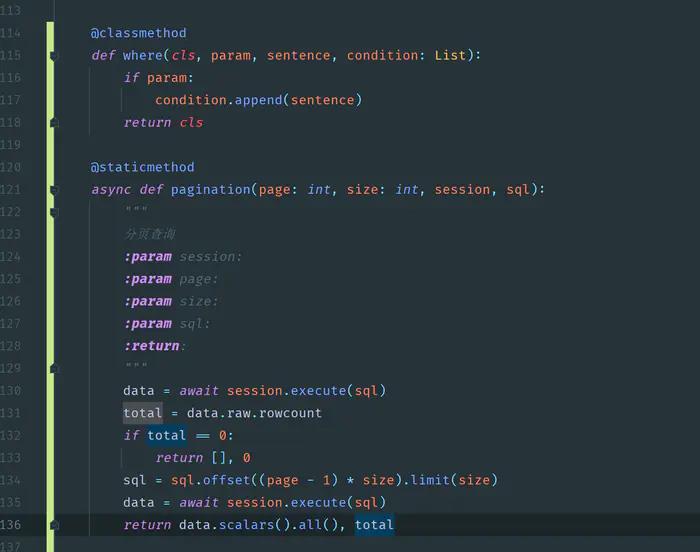
-
05.30 19:08:04发表了文章
2022-05-30 19:08:04
测试平台系列(72) 了解ApScheduler基本用法
了解ApScheduler基本用法
-
05.30 19:07:09发表了文章
2022-05-30 19:07:09
测试平台系列(71) Python定时任务方案
Python定时任务方案
-
05.30 19:06:30发表了文章
2022-05-30 19:06:30
Python展示requests下载文件进度(赶紧收藏吧)
Python展示requests下载文件进度
-
05.30 19:05:50发表了文章
2022-05-30 19:05:50
测试平台系列(70) 丰富断言类型
丰富断言类型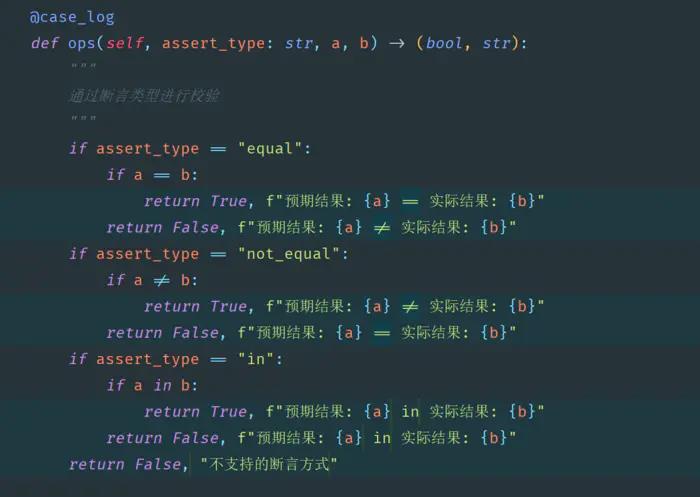
-
05.30 19:01:11发表了文章
2022-05-30 19:01:11
如何让python项目花里胡哨
如何让python项目花里胡哨
-
05.30 18:59:28发表了文章
2022-05-30 18:59:28
测试平台系列(69) 数据构造器支持sql语句
数据构造器支持sql语句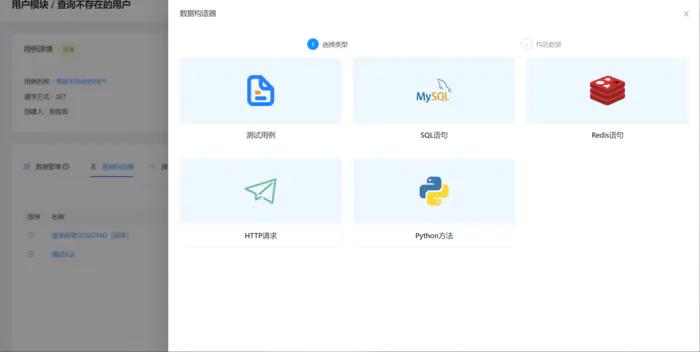
-
05.30 15:14:02发表了文章
2022-05-30 15:14:02
Selenium获取动态图片验证码
Selenium获取动态图片验证码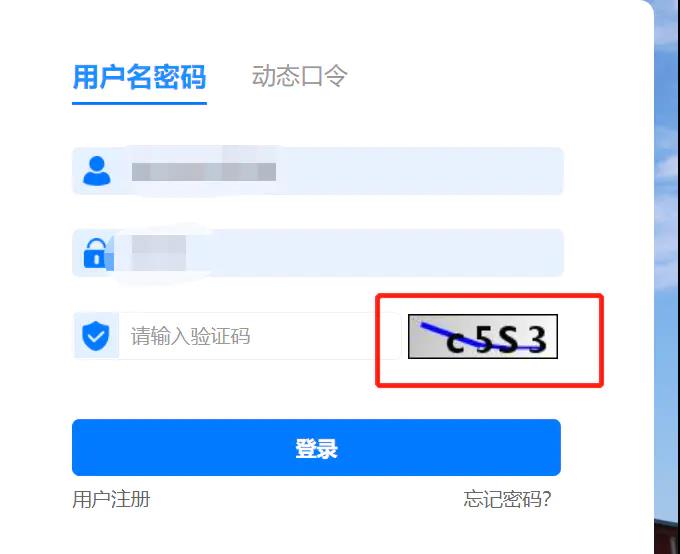
-
05.30 15:12:20发表了文章
2022-05-30 15:12:20
测试平台系列(68) 解决数据驱动带来的麻烦
解决数据驱动带来的麻烦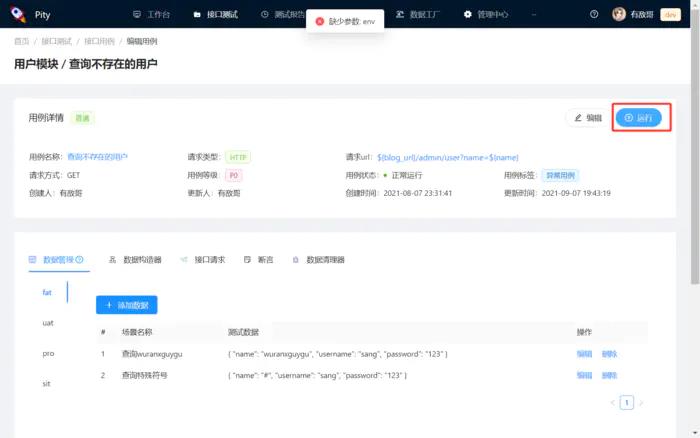
-
05.30 14:53:45发表了文章
2022-05-30 14:53:45
测试平台系列(67) 玩转数据驱动
玩转数据驱动
-
05.30 14:51:51发表了文章
2022-05-30 14:51:51
React实现组件全屏化
本文基于React+antd,给大家演示一个完整的全屏demo。 起因是开发今天给我提了一个sql编辑器输入框比较小,不支持放大,不太方便。希望能够全屏显示,联想到自己以后可能也会需要,便研究并记录之。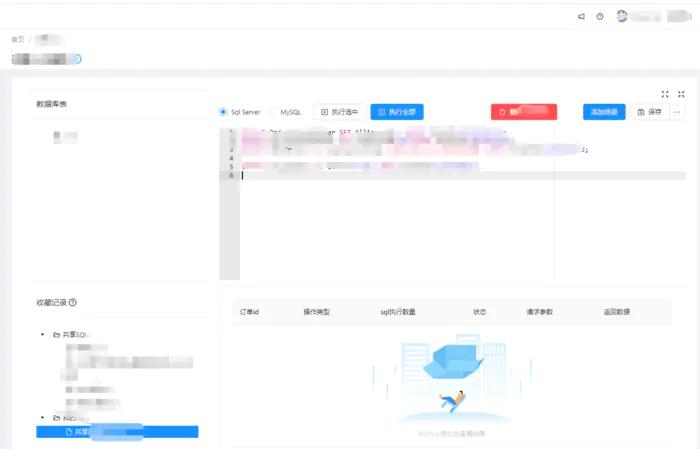
-
05.30 14:49:38发表了文章
2022-05-30 14:49:38
Python小知识之对象的比较
Python小知识之对象的比较
-
05.30 14:48:27发表了文章
2022-05-30 14:48:27
测试平台系列(66) 数据驱动之基础Model
数据驱动之基础Model
-
05.30 14:13:57发表了文章
2022-05-30 14:13:57
几分钟就能学会的Python虚拟环境教程
几分钟就能学会的Python虚拟环境教程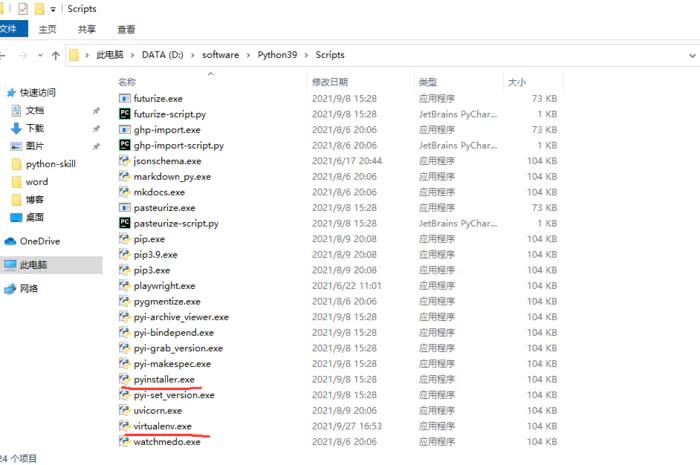
-
05.30 14:12:59发表了文章
2022-05-30 14:12:59
测试平台系列(65) 异步方法装饰器
异步方法装饰器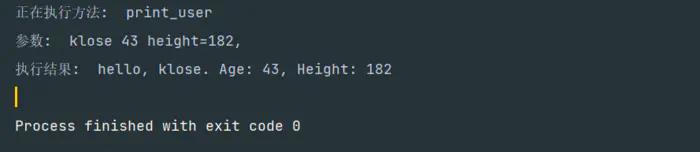
-
05.30 14:11:31发表了文章
2022-05-30 14:11:31
测试平台系列(64) 用Sqlalchemy填下断言的坑
用Sqlalchemy填下断言的坑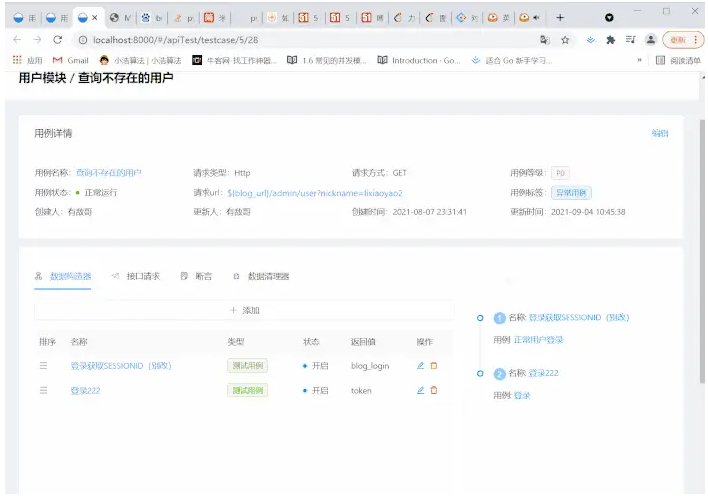
-
05.30 14:08:17发表了文章
2022-05-30 14:08:17
测试平台系列(63) 软删除之殇
软删除之殇 -
05.30 14:07:53发表了文章
2022-05-30 14:07:53
测试平台系列(62) 让前置条件有自己的顺序
让前置条件有自己的顺序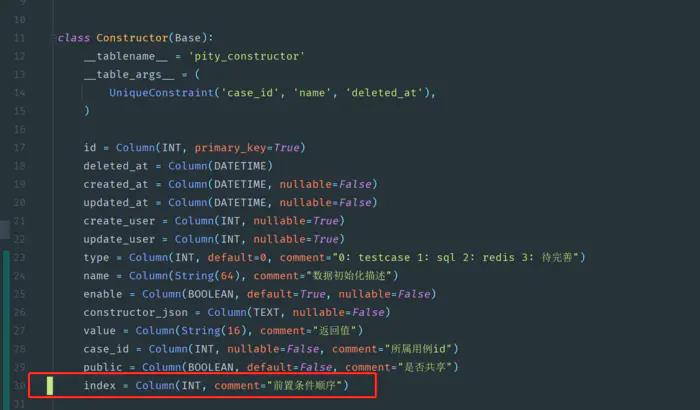
-
05.30 14:00:30发表了文章
2022-05-30 14:00:30
测试平台系列(61) 重构用例详情页面
重构用例详情页面
-
05.29 21:36:51发表了文章
2022-05-29 21:36:51
测试平台系列(60) 在Linux机器上部署Pity
在Linux机器上部署Pity
-
05.29 21:34:39发表了文章
2022-05-29 21:34:39
测试平台系列(59) 调整用例列表页
调整用例列表页
-
05.29 21:31:19发表了文章
2022-05-29 21:31:19
测试平台系列(58) 设计用例目录
设计用例目录
-
05.29 21:27:07发表了文章
2022-05-29 21:27:07
测试平台系列(57) 美化代码编辑器
美化代码编辑器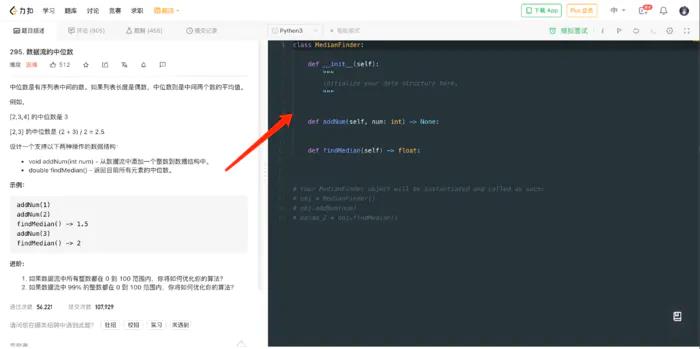
-
05.29 21:23:49发表了文章
2022-05-29 21:23:49
测试平台系列(56) JSON深层次对比方案
JSON深层次对比方案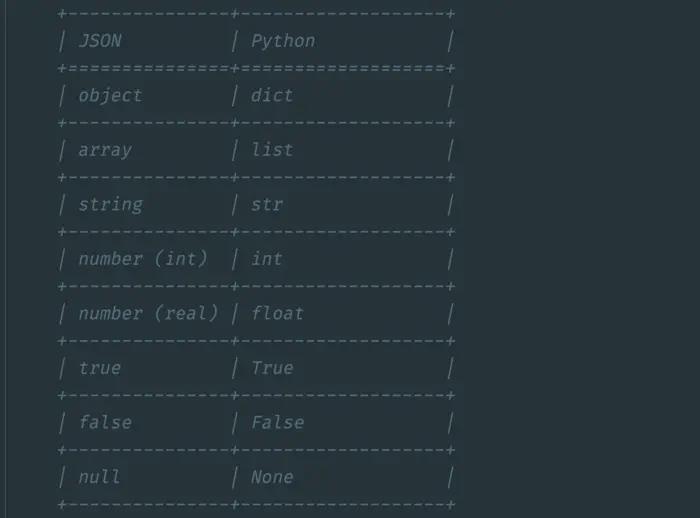
-
05.29 20:33:48发表了文章
2022-05-29 20:33:48
测试平台系列(55) 引入AceEditor(代码编辑器)
引入AceEditor(代码编辑器)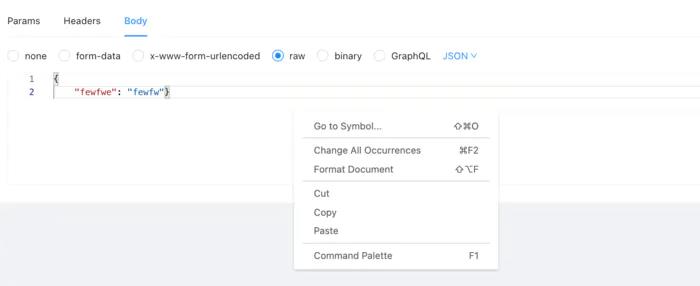
-
05.29 20:31:02发表了文章
2022-05-29 20:31:02
一文搞懂Unittest测试方法执行顺序
一文搞懂Unittest测试方法执行顺序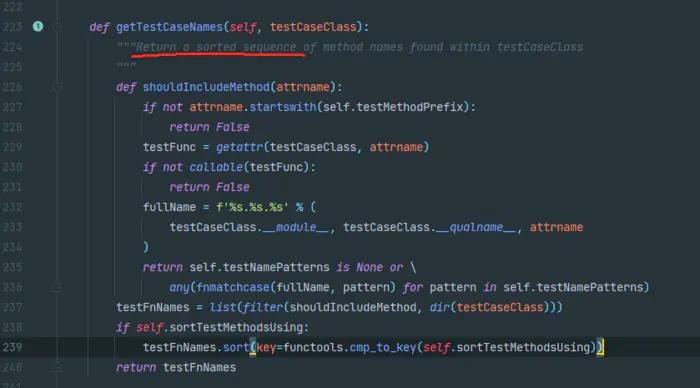
-
05.29 20:11:58发表了文章
2022-05-29 20:11:58
测试平台系列(54) 数据库表接口适配前端页面(下)
数据库表接口适配前端页面(下)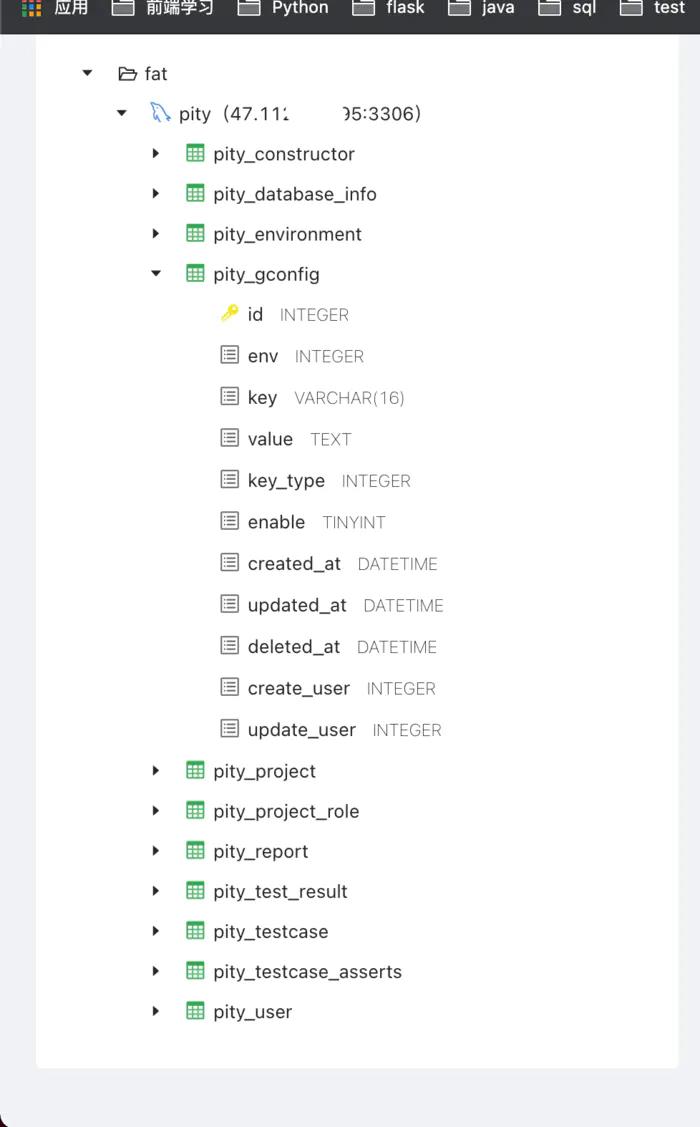
-
05.29 20:06:09发表了文章
2022-05-29 20:06:09
测试平台系列(53) 数据库表接口适配前端页面(上)
数据库表接口适配前端页面(上)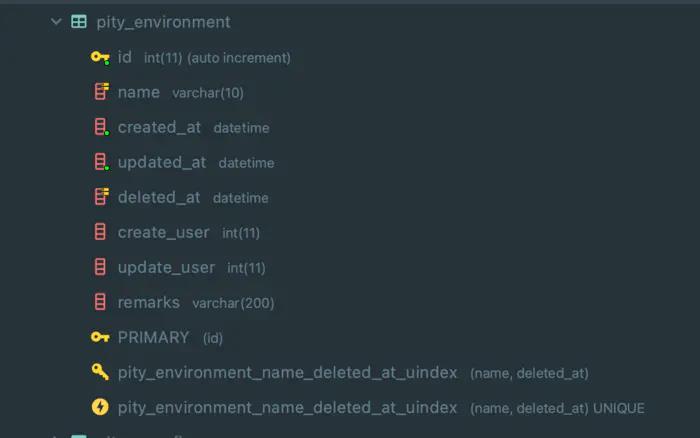
-
05.29 20:04:55发表了文章
2022-05-29 20:04:55
测试平台系列(52) 改造异步数据库连接方案
改造异步数据库连接方案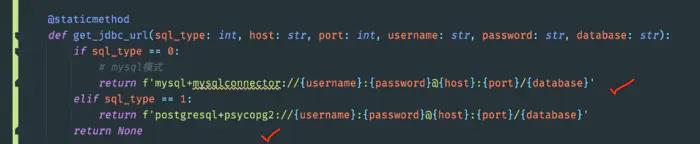
-
05.29 20:02:42发表了文章
2022-05-29 20:02:42
测试平台系列(51) 编写数据库连接相关方法
编写数据库连接相关方法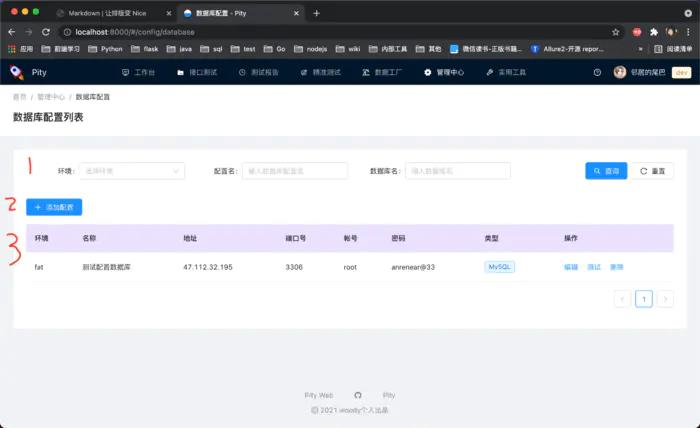
-
05.29 20:00:30发表了文章
2022-05-29 20:00:30
测试平台系列(50) 编写数据库连接配置功能(1)
编写数据库连接配置功能(1)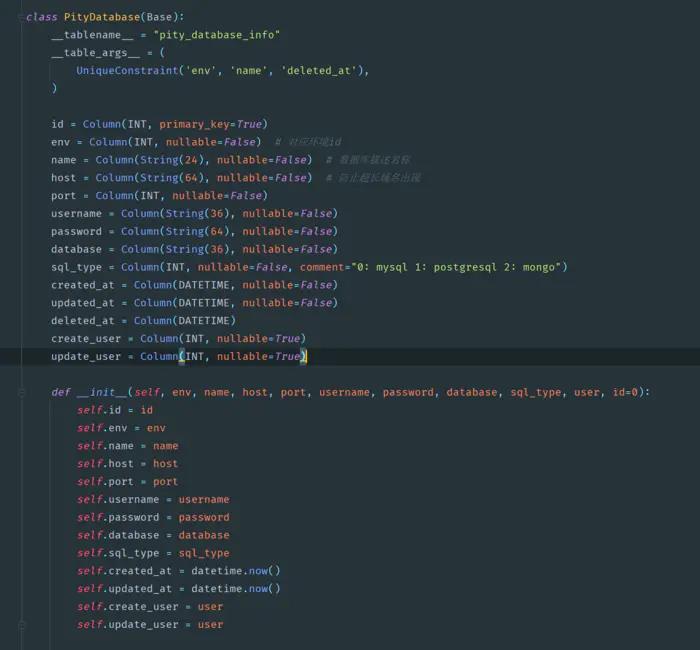
-
05.28 21:18:22发表了文章
2022-05-28 21:18:22
测试平台系列(49) 写入/读取用例执行数据
写入/读取用例执行数据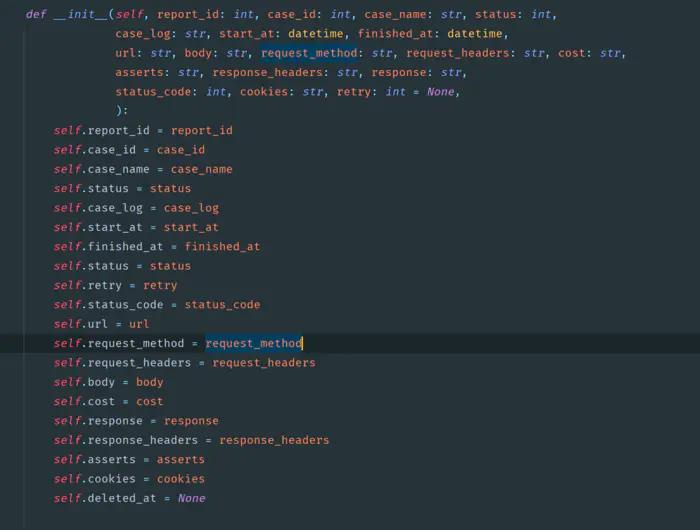
-
05.28 21:09:00发表了文章
2022-05-28 21:09:00
测试平台系列(48) 编写构建历史页面
编写构建历史页面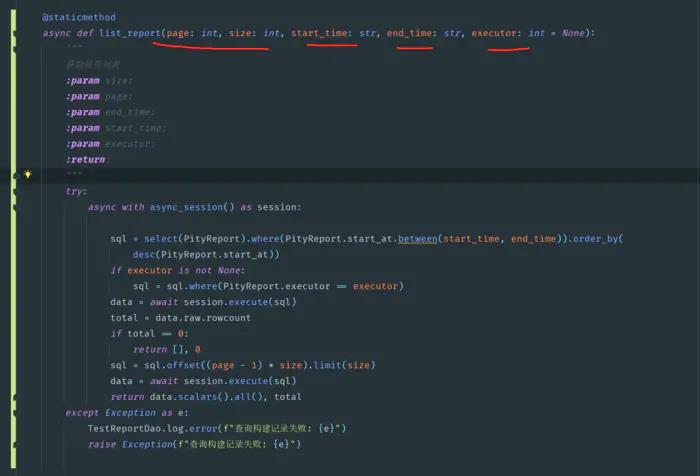
-
05.28 21:07:51发表了文章
2022-05-28 21:07:51
测试平台系列(47) 编写测试报告之构建记录
编写测试报告之构建记录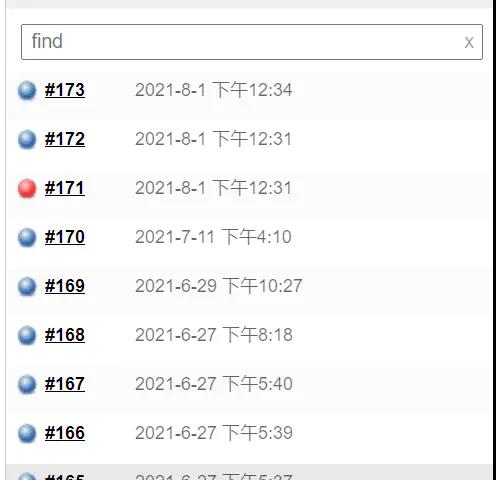
-
05.28 21:06:28发表了文章
2022-05-28 21:06:28
测试平台系列(46) 用例并发之我全都要
用例并发之我全都要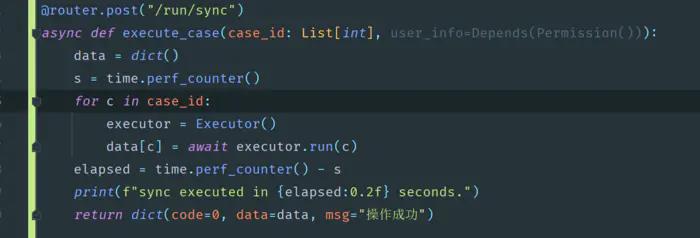
-
05.28 21:04:59发表了文章
2022-05-28 21:04:59
测试平台系列(45) 前后端合并(下)
前后端合并(下)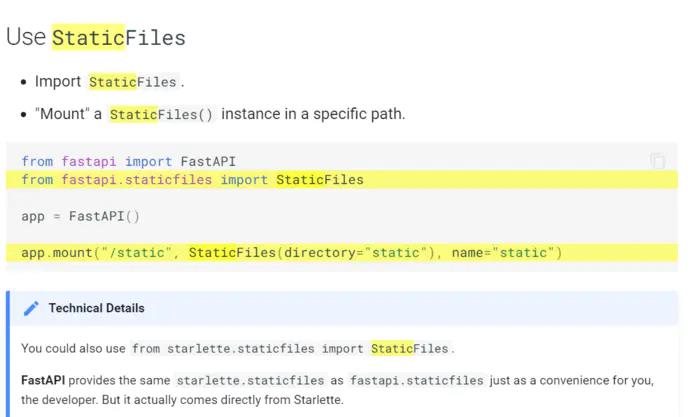
-
05.28 21:02:49发表了文章
2022-05-28 21:02:49
测试平台系列(44) 前后端合并(上)
前后端合并(上)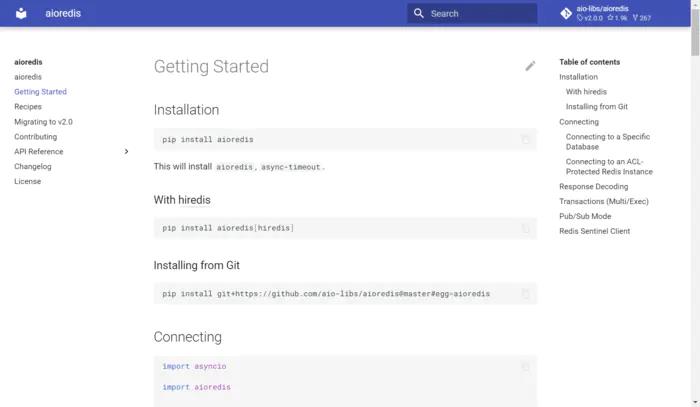
-
05.28 20:26:59发表了文章
2022-05-28 20:26:59
测试平台系列(43) aiohttp初体验
aiohttp初体验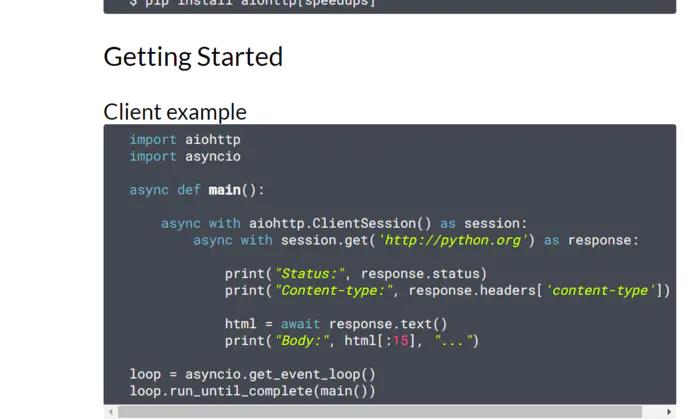
-
05.28 20:25:02发表了文章
2022-05-28 20:25:02
测试平台系列(42) 编写数据构造器功能(下)
编写数据构造器功能(下)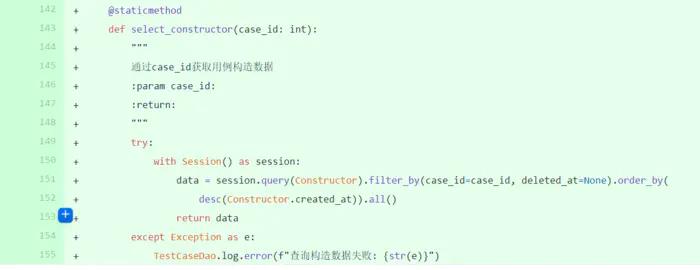
-
05.28 20:13:54发表了文章
2022-05-28 20:13:54
测试平台系列(41) 编写数据构造器功能(上)
编写数据构造器功能(上)
-
发表了文章
2022-05-30
测试平台系列(81) 编写在线执行Redis功能
-
发表了文章
2022-05-30
测试平台系列(80) 封装Redis客户端
-
发表了文章
2022-05-30
测试平台系列(79) 编写Redis配置功能(下)
-
发表了文章
2022-05-30
测试平台系列(78) 编写Redis配置管理功能(上)
-
发表了文章
2022-05-30
测试平台系列(77) 完善测试计划页面
-
发表了文章
2022-05-30
测试平台系列(76) 编写测试计划前端部分
-
发表了文章
2022-05-30
测试平台系列(75) 完善测试计划的删改查功能
-
发表了文章
2022-05-30
测试平台系列(74) 测试计划定时执行初体验
-
发表了文章
2022-05-30
FastApi下载文件
-
发表了文章
2022-05-30
Python Excel工具类封装, 给excel表头搞点颜色
-
发表了文章
2022-05-30
测试平台系列(73) 设计测试计划功能
-
发表了文章
2022-05-30
测试平台系列(72) 了解ApScheduler基本用法
-
发表了文章
2022-05-30
测试平台系列(71) Python定时任务方案
-
发表了文章
2022-05-30
Python展示requests下载文件进度(赶紧收藏吧)
-
发表了文章
2022-05-30
测试平台系列(70) 丰富断言类型
-
发表了文章
2022-05-30
如何让python项目花里胡哨
-
发表了文章
2022-05-30
测试平台系列(69) 数据构造器支持sql语句
-
发表了文章
2022-05-30
Selenium获取动态图片验证码
-
发表了文章
2022-05-30
测试平台系列(68) 解决数据驱动带来的麻烦
-
发表了文章
2022-05-30
测试平台系列(67) 玩转数据驱动
滑动查看更多
暂无更多信息
暂无更多信息