游客iigf2m33ba53k

已加入开发者社区1021天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖



我关注的人
粉丝
游客in3d2jyl5tsai
游客in3d2jyl5tsai
游客4snvrgn254kfg
游客4snvrgn254kfg
游客7jg3falezzovc
游客7jg3falezzovc
Anny2023
Anny2023
天天向上20160601
天天向上20160601
码字猴儿
码字猴儿
aliyun8562423054-13673
aliyun8562423054-13673
游客u4ivk5t3bybd4
游客u4ivk5t3bybd4

五只猫的爸
五只猫的爸
游客d4ctjwcbkna34
游客d4ctjwcbkna34
游客2k3ho6lengldi
游客2k3ho6lengldi
游客hafirrw3glhbe
游客hafirrw3glhbe
技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2023年01月
-
01.18 10:43:32
 发表了文章
2023-01-18 10:43:32
发表了文章
2023-01-18 10:43:32
盘一盘!实时自动驾驶车辆定位技术都有哪些?(视觉/Lidar/多传感器数据融合)(下)
与基于激光雷达的定位相比,基于视觉和数据融合的定位技术在提高精度方面的潜力约为2–5倍。基于激光雷达和视觉的定位可以通过提高图像配准方法的效率来降低计算复杂性。与基于激光雷达和视觉的定位相比,基于数据融合的定位可以实现更好的实时性能,因为每个独立传感器不需要开发复杂的算法来实现其最佳定位潜力。V2X技术可以提高定位鲁棒性。最后,讨论了基于定量比较结果的AVs定位的潜在解决方案和未来方向。
-
01.18 10:39:21发表了文章
2023-01-18 10:39:21
盘一盘!实时自动驾驶车辆定位技术都有哪些?(视觉/Lidar/多传感器数据融合)(上)
与基于激光雷达的定位相比,基于视觉和数据融合的定位技术在提高精度方面的潜力约为2–5倍。基于激光雷达和视觉的定位可以通过提高图像配准方法的效率来降低计算复杂性。与基于激光雷达和视觉的定位相比,基于数据融合的定位可以实现更好的实时性能,因为每个独立传感器不需要开发复杂的算法来实现其最佳定位潜力。V2X技术可以提高定位鲁棒性。最后,讨论了基于定量比较结果的AVs定位的潜在解决方案和未来方向。
-
01.18 10:36:01发表了文章
2023-01-18 10:36:01
多模态最新Benchmark!aiMotive DataSet:远距离感知数据集(下)
本文引入了一个多模态数据集,用于具有远程感知的鲁棒自动驾驶。该数据集由176个场景组成,具有同步和校准的激光雷达(Lidar)、相机和毫米波雷达(Radar),覆盖360度视场。所收集的数据是在白天、夜间和下雨时在高速公路、城市和郊区捕获的,并使用具有跨帧一致标识符的3D边界框进行标注。此外,本文训练了用于三维目标检测的单模态和多模态基线模型。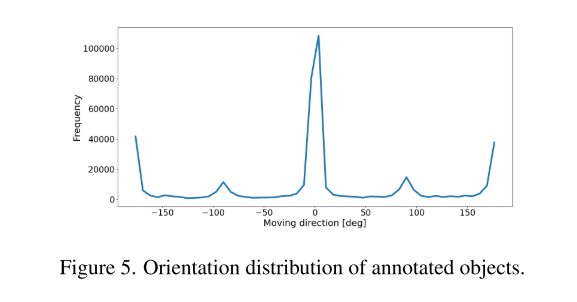
-
01.18 10:35:57发表了文章
2023-01-18 10:35:57
多模态最新Benchmark!aiMotive DataSet:远距离感知数据集(上)
本文引入了一个多模态数据集,用于具有远程感知的鲁棒自动驾驶。该数据集由176个场景组成,具有同步和校准的激光雷达(Lidar)、相机和毫米波雷达(Radar),覆盖360度视场。所收集的数据是在白天、夜间和下雨时在高速公路、城市和郊区捕获的,并使用具有跨帧一致标识符的3D边界框进行标注。此外,本文训练了用于三维目标检测的单模态和多模态基线模型。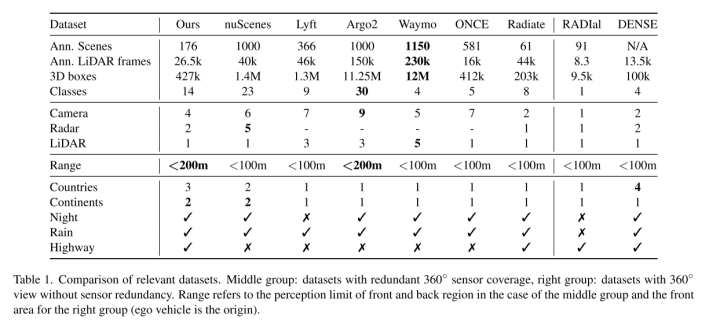
-
01.18 10:29:17发表了文章
2023-01-18 10:29:17
最新综述!分析用于实时车载激光雷达感知的点云深度学习表示(空间结构/光栅化/坐标系)
随着帧速率、点云大小和传感器分辨率的增加,这些点云的实时处理仍必须从车辆环境的这张日益精确的图片中提取语义。在这些点云上运行的深度神经网络性能和准确性的一个决定因素是底层数据表示及其计算方式。本文调查了神经网络中使用的计算表示与其性能特征之间的关系,提出了现代深度神经网络中用于3D点云处理的LiDAR点云表示的新计算分类法。使用这种分类法,对不同的方法家族进行结构化分析,论文揭示了在计算效率、内存需求和表示能力方面的共同优势和局限性,这些都是通过语义分割性能来衡量的。最后,论文为基于神经网络的点云处理方法的未来发展提供了一些见解和指导。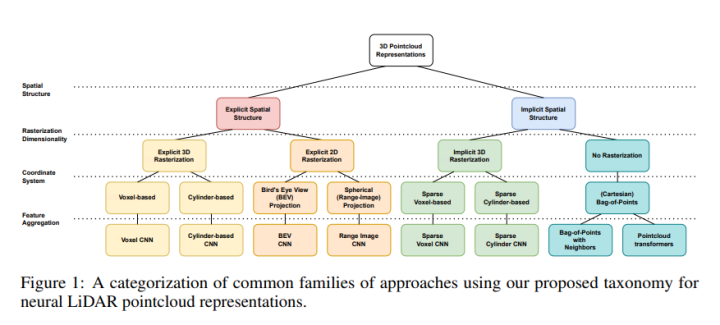
-
01.18 10:26:16发表了文章
2023-01-18 10:26:16
DETR系列大盘点 | 端到端Transformer目标检测算法汇总!(下)
自从VIT横空出世以来,Transformer在CV界掀起了一场革新,各个上下游任务都得到了长足的进步,今天就带大家盘点一下基于Transformer的端到端目标检测算法!
-
01.18 10:23:12发表了文章
2023-01-18 10:23:12
DETR系列大盘点 | 端到端Transformer目标检测算法汇总!(上)
自从VIT横空出世以来,Transformer在CV界掀起了一场革新,各个上下游任务都得到了长足的进步,今天就带大家盘点一下基于Transformer的端到端目标检测算法!
-
01.18 10:19:10发表了文章
2023-01-18 10:19:10
Nuscenes SOTA!BEVFormer v2: 通过透视监督使流行的图像Backbones适应BEV识别!
作者提出了一种具有透视监督的新型鸟瞰图(BEV)检测器,它收敛更快,更适合目前的图像主干网络。现有的SOTA BEV检测器通常与某些深度预训练的主干网(如VoVNet)相连,阻碍了图像backbones和BEV检测器之间的协同作用。为了解决这一限制,论文优先考虑通过引入透视空间监督来简化BEV检测器的优化方案。为此提出了一种两级BEV检测器,其中来自透视头部的proposal被输入鸟瞰头部,用于最终预测。为了评估模型的有效性,作者进行了广泛的消融研究,重点是监督的形式和拟议检测器的通用性。所提出的方法在传统和主流图像主干上得到了验证,并在大规模nuScene数据集上获得了新的SOTA结果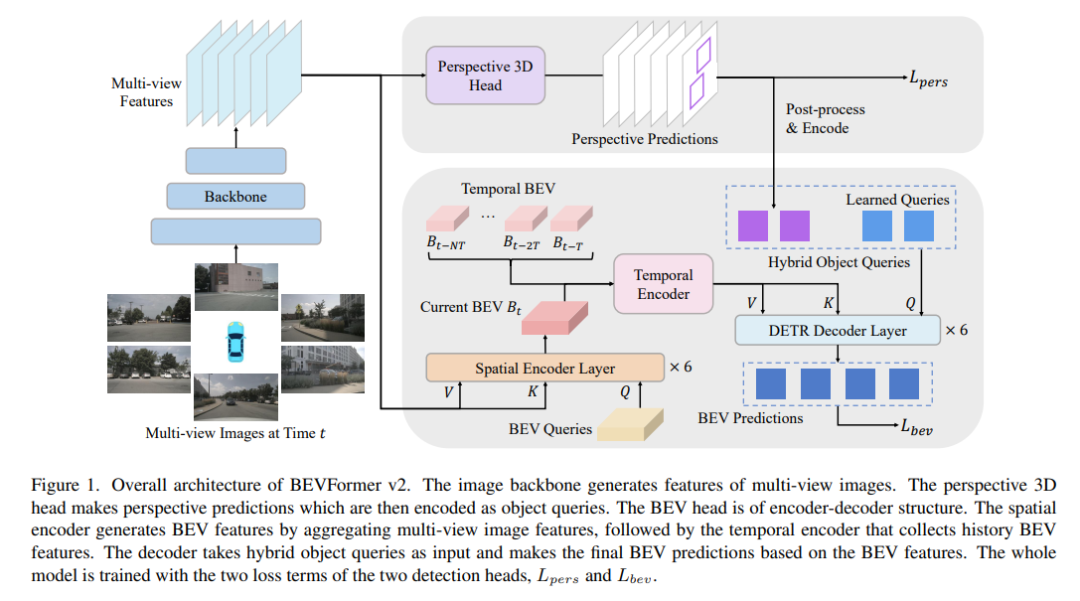
-
01.18 10:15:01发表了文章
2023-01-18 10:15:01
激光雷达与视觉联合标定综述!(系统介绍/标定板选择/在线离线标定等)
由于2D识别的成功,论文引入了一个大型基准,称为OMNI3D,重新审视了3D目标检测的任务。OMNI3D对现有数据集进行了重新利用和组合,生成了234k张图像,标注了300多万个实例和97个类别。由于相机内参的变化以及场景和目标类型的丰富多样性,这种规模的3D检测具有挑战性。论文提出了一个名为Cube R-CNN的模型,旨在通过统一的方法在摄像机和场景类型之间进行泛化。结果表明,在更大的OMNI3D和现有基准上,Cube R-CNN优于先前的工作。最后,论文证明了OMNI3D是一个强大的3D目标识别数据集,表明它提高了单个数据集的性能,并可以通过预训练加速对新的较小数据集的学习。
-
01.18 10:09:18发表了文章
2023-01-18 10:09:18
最新!OMNI3D:3D目标检测的大型基准和模型(Meta AI)
由于2D识别的成功,论文引入了一个大型基准,称为OMNI3D,重新审视了3D目标检测的任务。OMNI3D对现有数据集进行了重新利用和组合,生成了234k张图像,标注了300多万个实例和97个类别。由于相机内参的变化以及场景和目标类型的丰富多样性,这种规模的3D检测具有挑战性。论文提出了一个名为Cube R-CNN的模型,旨在通过统一的方法在摄像机和场景类型之间进行泛化。结果表明,在更大的OMNI3D和现有基准上,Cube R-CNN优于先前的工作。最后,论文证明了OMNI3D是一个强大的3D目标识别数据集,表明它提高了单个数据集的性能,并可以通过预训练加速对新的较小数据集的学习。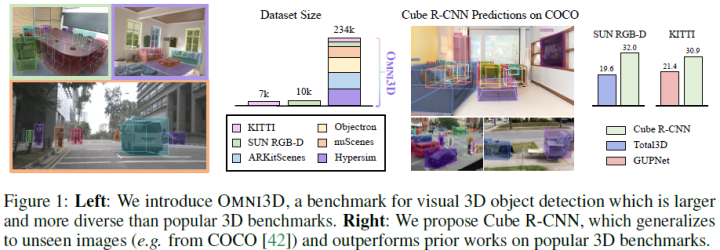
-
01.18 10:02:11发表了文章
2023-01-18 10:02:11
领域最全 | 计算机视觉算法在路面坑洼检测中的应用综述(基于2D图像/3D LiDAR/深度学习)(下)
本文首先介绍了用于2D和3D道路数据采集的传感系统,包括摄像机、激光扫描仪和微软Kinect。随后,对 SoTA 计算机视觉算法进行了全面深入的综述,包括: (1)经典的2D图像处理,(2)3D点云建模与分割,(3)机器/深度学习。本文还讨论了基于计算机视觉的路面坑洼检测方法目前面临的挑战和未来的发展趋势: 经典的基于2D图像处理和基于3D点云建模和分割的方法已经成为历史; 卷积神经网络(CNN)已经展示了引人注目的路面坑洼检测结果,并有望在未来的进展中打破瓶颈的自/无监督学习多模态语义分割。作者相信本研究可为下一代道路状况评估系统的发展提供实用的指导。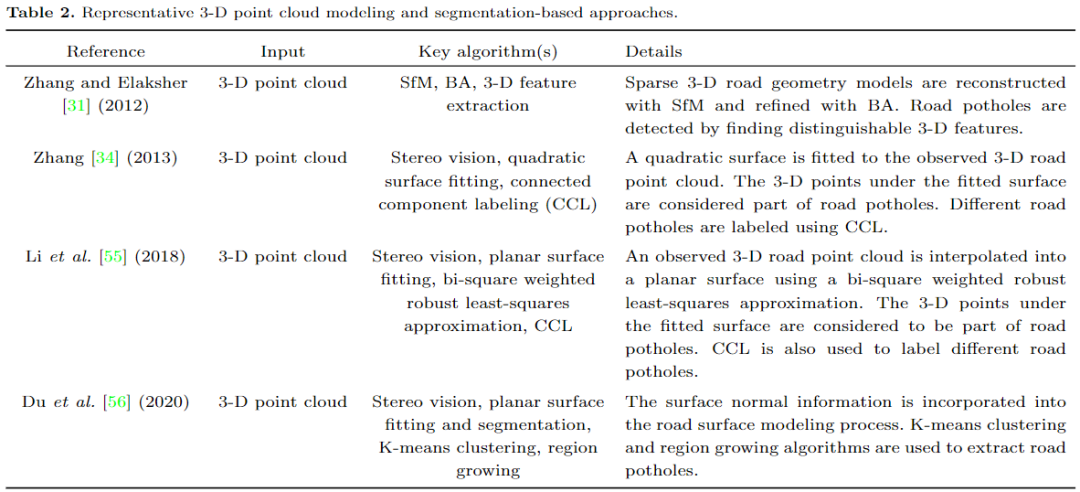
-
01.18 10:00:01发表了文章
2023-01-18 10:00:01
领域最全 | 计算机视觉算法在路面坑洼检测中的应用综述(基于2D图像/3D LiDAR/深度学习)(上)
本文首先介绍了用于2D和3D道路数据采集的传感系统,包括摄像机、激光扫描仪和微软Kinect。随后,对 SoTA 计算机视觉算法进行了全面深入的综述,包括: (1)经典的2D图像处理,(2)3D点云建模与分割,(3)机器/深度学习。本文还讨论了基于计算机视觉的路面坑洼检测方法目前面临的挑战和未来的发展趋势: 经典的基于2D图像处理和基于3D点云建模和分割的方法已经成为历史; 卷积神经网络(CNN)已经展示了引人注目的路面坑洼检测结果,并有望在未来的进展中打破瓶颈的自/无监督学习多模态语义分割。作者相信本研究可为下一代道路状况评估系统的发展提供实用的指导。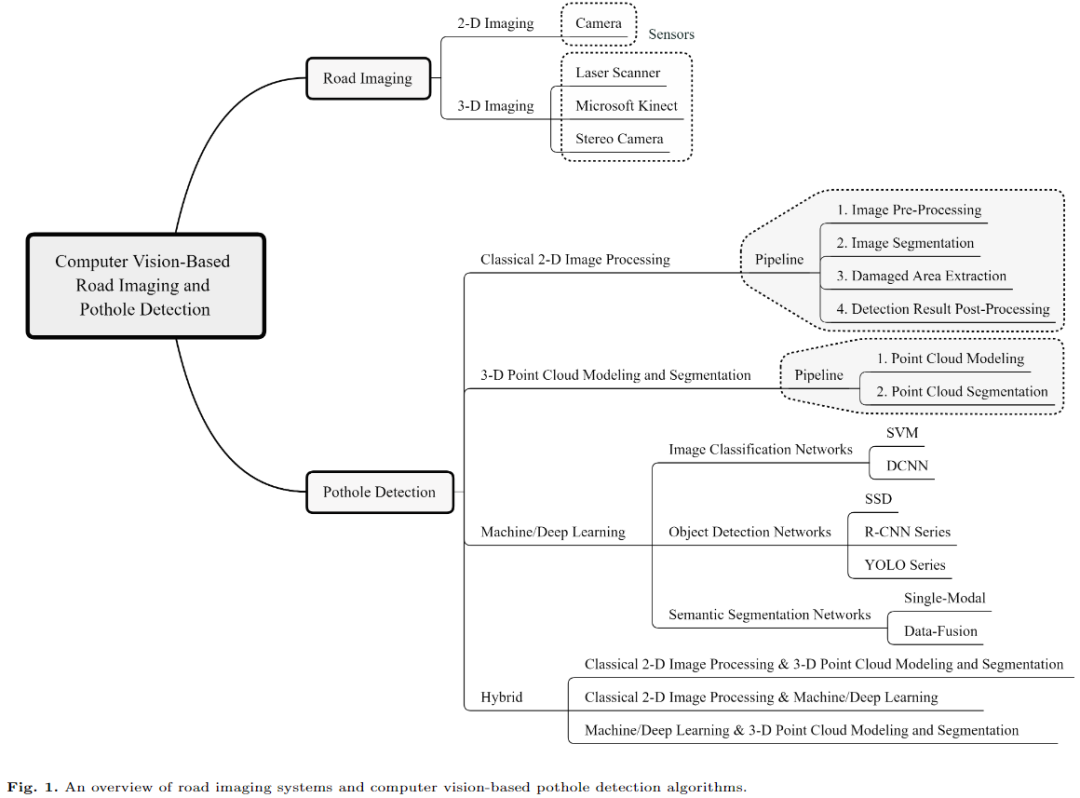
-
01.18 09:56:32发表了文章
2023-01-18 09:56:32
一文尽览 | 轨迹预测二十年发展全面回顾!(基于物理/机器学习/深度学习/强化学习)(下)
为了在动态环境中安全驾驶,自动驾驶车辆应该能够预测附近交通参与者的未来状态,尤其是周围车辆,类似于人类驾驶员的预测驾驶能力。这就是为什么研究人员致力于轨迹预测领域并提出不同的方法。本文旨在对过去二十年中提出的自动驾驶轨迹预测方法进行全面和比较性的回顾!!!它从问题公式和算法分类开始。然后,详细介绍和分析了基于物理、经典机器学习、深度学习和强化学习的流行方法。最后,论文评估了每种方法的性能,并概述了潜在的研究方向。
-
01.18 09:53:35发表了文章
2023-01-18 09:53:35
一文尽览 | 轨迹预测二十年发展全面回顾!(基于物理/机器学习/深度学习/强化学习)(上)
为了在动态环境中安全驾驶,自动驾驶车辆应该能够预测附近交通参与者的未来状态,尤其是周围车辆,类似于人类驾驶员的预测驾驶能力。这就是为什么研究人员致力于轨迹预测领域并提出不同的方法。本文旨在对过去二十年中提出的自动驾驶轨迹预测方法进行全面和比较性的回顾!!!它从问题公式和算法分类开始。然后,详细介绍和分析了基于物理、经典机器学习、深度学习和强化学习的流行方法。最后,论文评估了每种方法的性能,并概述了潜在的研究方向。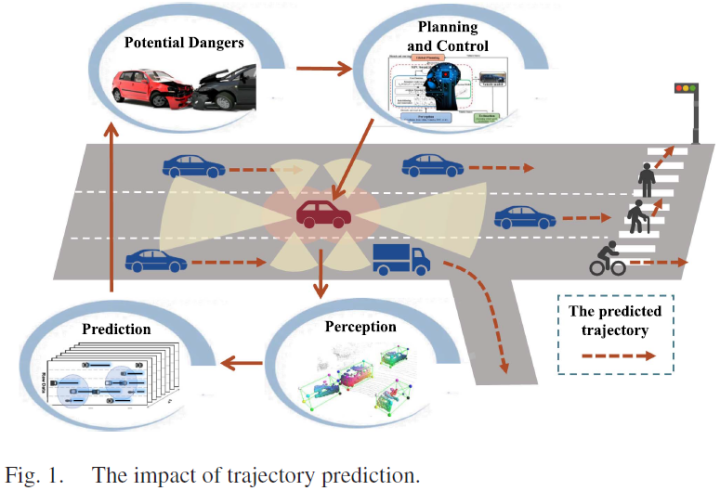
-
01.18 09:47:27发表了文章
2023-01-18 09:47:27
首篇!无相机参数BEV感知!(北航、地平线)
CFT在nuScenes检测任务排行榜上实现了49.7%的NDS,与其他几何引导方法相比,这是第一个去除相机参数的工作。在没有时间输入和其他模态信息的情况下,CFT以较小的图像输入(1600×640)实现了第二高的性能。由于view-attention的变体,CFT将普通注意力的内存和transformer FLOPs分别减少了约12%和60%,NDS提高了1.0%。此外,它对噪声相机参数的天然鲁棒性使CFT更具竞争力!!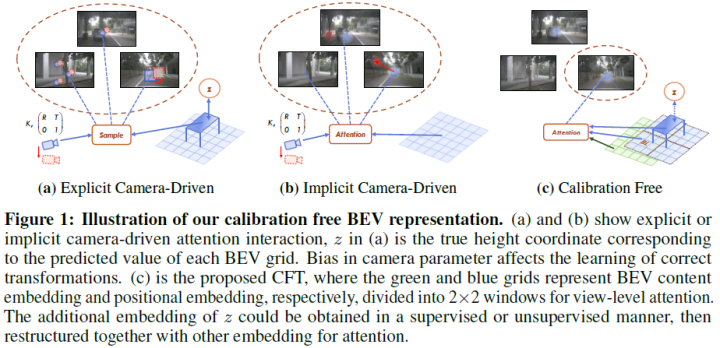
-
01.18 01:43:29发表了文章
2023-01-18 01:43:29
IROS2022 | 训练数据不够?那就学习模拟真实的激光雷达!
模拟逼真的传感器是自动驾驶系统数据生成中的一个挑战,通常涉及精心制作的传感器设计、场景特性和物理建模。为了缓解这一问题,论文引入了一种用于真实激光雷达传感器的数据驱动模拟的管道!!论文提出了一个模型,该模型直接从真实数据集学习RGB图像和相应的激光雷达特征(如光线下降或perpoint强度)之间的映射。结果表明,该模型可以学习如何对真实效果进行编码,例如透明表面上的落点或反射材料上的高强度反射。当应用于现成模拟器软件提供的简单的光线投射点云时,论文的模型通过预测强度和基于场景外观去除点云来增强数据,以匹配真实的激光雷达传感器。
-
01.18 01:37:14发表了文章
2023-01-18 01:37:14
纯视觉3D检测综述!一文详解3D检测现状、趋势和未来方向!(下)
基于图像的3D目标检测是自动驾驶领域的一个基本问题,也是一个具有挑战性的问题,近年来受到了业界和学术界越来越多的关注。得益于深度学习技术的快速发展,基于图像的3D检测取得了显著的进展。特别是,从2015年到2021年,已经有超过200篇研究这个问题的著作,涵盖了广泛的理论、算法和应用。然而,到目前为止,还没有一个调查来收集和组织这方面的知识。本文首次对这一新兴的不断发展的研究领域进行了全面综述,总结了基于图像的3D检测最常用的流程,并对其各个组成部分进行了深入分析。此外,作者还提出了两个新的分类法,将最先进的方法组织成不同的类别,以期提供更多的现有方法的系统综述,并促进与未来作品的公平比较。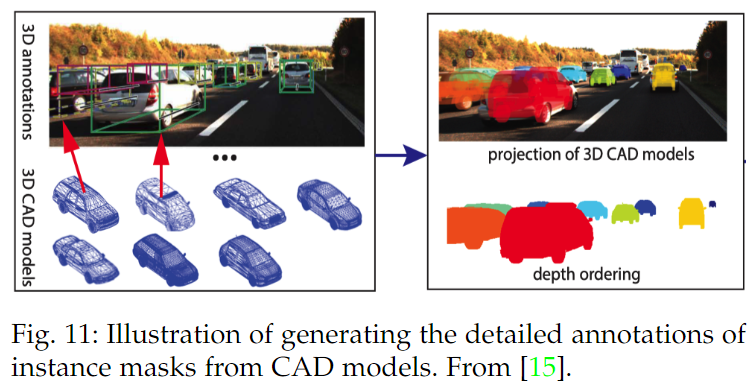
-
01.18 01:37:06发表了文章
2023-01-18 01:37:06
纯视觉3D检测综述!一文详解3D检测现状、趋势和未来方向!(中)
基于图像的3D目标检测是自动驾驶领域的一个基本问题,也是一个具有挑战性的问题,近年来受到了业界和学术界越来越多的关注。得益于深度学习技术的快速发展,基于图像的3D检测取得了显著的进展。特别是,从2015年到2021年,已经有超过200篇研究这个问题的著作,涵盖了广泛的理论、算法和应用。然而,到目前为止,还没有一个调查来收集和组织这方面的知识。本文首次对这一新兴的不断发展的研究领域进行了全面综述,总结了基于图像的3D检测最常用的流程,并对其各个组成部分进行了深入分析。此外,作者还提出了两个新的分类法,将最先进的方法组织成不同的类别,以期提供更多的现有方法的系统综述,并促进与未来作品的公平比较。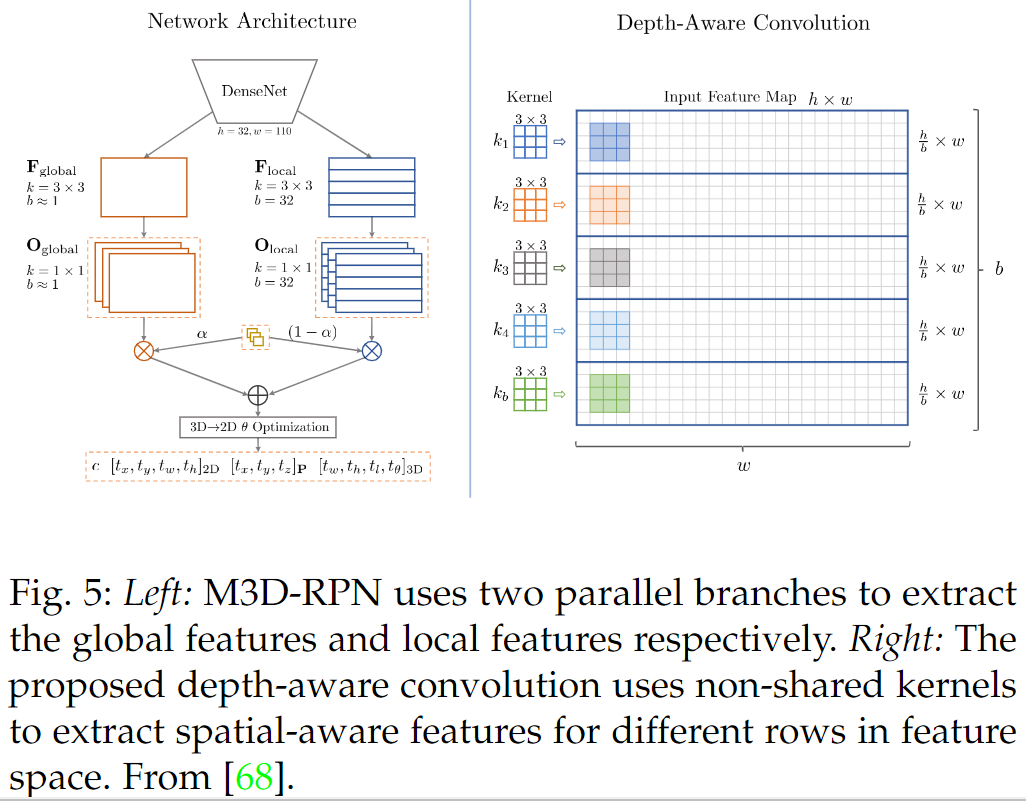
-
01.18 01:31:18发表了文章
2023-01-18 01:31:18
纯视觉3D检测综述!一文详解3D检测现状、趋势和未来方向!(上)
基于图像的3D目标检测是自动驾驶领域的一个基本问题,也是一个具有挑战性的问题,近年来受到了业界和学术界越来越多的关注。得益于深度学习技术的快速发展,基于图像的3D检测取得了显著的进展。特别是,从2015年到2021年,已经有超过200篇研究这个问题的著作,涵盖了广泛的理论、算法和应用。然而,到目前为止,还没有一个调查来收集和组织这方面的知识。本文首次对这一新兴的不断发展的研究领域进行了全面综述,总结了基于图像的3D检测最常用的流程,并对其各个组成部分进行了深入分析。此外,作者还提出了两个新的分类法,将最先进的方法组织成不同的类别,以期提供更多的现有方法的系统综述,并促进与未来作品的公平比较。在
-
01.18 01:20:23发表了文章
2023-01-18 01:20:23
SSDA-YOLO:用于跨域目标检测的半监督域自适应YOLO方法
即使最先进的方法在大规模基准测试(例如,PascalVOC、MSCOCO和OpenImages)上取得了优异的结果,在非常不同的目标域场景下进行测试时,也会出现显著的性能下降。
-
01.18 01:12:20发表了文章
2023-01-18 01:12:20
最新代码开源!TartanCalib:自适应亚像素细化的广角镜头标定
作者测试了三种利用中间相机模型的关键方法:(1)将图像分解为虚拟针孔相机,(2)将目标重新投影到图像帧中,以及(3)自适应亚像素细化。将自适应子像素细化和特征重投影相结合,可将重投影误差显著提高26.59%,帮助检测到最多42.01%的特征,并提高密集深度映射下游任务的性能。最后,TartanCalib是开源的,并在一个易于使用的标定工具箱中实现。作者还提供了一个translation 层和其它最先进的工作,允许使用数千个参数回归通用模型或使用更稳健的求解器。为此,TartanCalib是广角标定的首选工具!
-
01.18 01:07:20发表了文章
2023-01-18 01:07:20
2022最新综述!稀疏数据下的深度图补全(深度学习/非引导/RGB引导)(下)
获取正确的像素级场景深度在各种任务中发挥着重要作用,如场景理解、自动驾驶、机器人导航、同时定位和建图、智能农业和增强现实。因此,这是过去几十年来研究的一个长期目标。获得场景深度的一种成本有效的方法是使用单目深度估计算法,从单个图像直接估计场景深度。
-
01.18 01:07:17发表了文章
2023-01-18 01:07:17
2022最新综述!稀疏数据下的深度图补全(深度学习/非引导/RGB引导)(上)
获取正确的像素级场景深度在各种任务中发挥着重要作用,如场景理解、自动驾驶、机器人导航、同时定位和建图、智能农业和增强现实。因此,这是过去几十年来研究的一个长期目标。获得场景深度的一种成本有效的方法是使用单目深度估计算法,从单个图像直接估计场景深度。
-
01.18 01:01:05发表了文章
2023-01-18 01:01:05
PSA-Det3D:探究3D目标检测小尺寸解决方案
作者提出了PSA-Det3D网络提升3D小尺寸目标检测精度,包含PSA (Pillar Set Abstraction),FPC (Foreground Point Compensation)和point-based detection模块。PSA模块是基于SA (Set Abstraction)设计,通过pillar query operation扩大感受野,有效聚合点特征。FPC模块利用前景点分割和候选框生成模块,定位更多的遮挡物体。前景点和预测的中心点被整合在一起,用以预测最终的检测结果。在KITTI 3D检测数据集中,PSA-Det3D取得了较好的性能,尤其是对于小尺寸目标。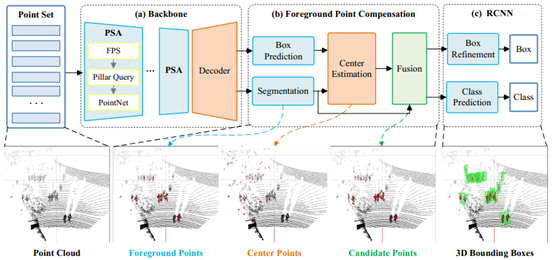
-
01.18 00:53:30发表了文章
2023-01-18 00:53:30
一文详解视觉Transformer在CV中的现状、趋势和未来方向(分类/检测/分割/多传感器融合)(下)
本综述根据三个基本的CV任务和不同的数据流类型,全面调查了100多种不同的视觉Transformer,并提出了一种分类法,根据其动机、结构和应用场景来组织代表性方法。由于它们在训练设置和专用视觉任务上的差异,论文还评估并比较了不同配置下的所有现有视觉Transformer。此外,论文还揭示了一系列重要但尚未开发的方面,这些方面可能使此类视觉Transformer能够从众多架构中脱颖而出,例如,松散的高级语义嵌入,以弥合视觉Transformer与序列式之间的差距。最后,提出了未来有前景的研究方向。
-
01.18 00:51:49发表了文章
2023-01-18 00:51:49
一文详解视觉Transformer在CV中的现状、趋势和未来方向(分类/检测/分割/多传感器融合)(中)
本综述根据三个基本的CV任务和不同的数据流类型,全面调查了100多种不同的视觉Transformer,并提出了一种分类法,根据其动机、结构和应用场景来组织代表性方法。由于它们在训练设置和专用视觉任务上的差异,论文还评估并比较了不同配置下的所有现有视觉Transformer。此外,论文还揭示了一系列重要但尚未开发的方面,这些方面可能使此类视觉Transformer能够从众多架构中脱颖而出,例如,松散的高级语义嵌入,以弥合视觉Transformer与序列式之间的差距。最后,提出了未来有前景的研究方向。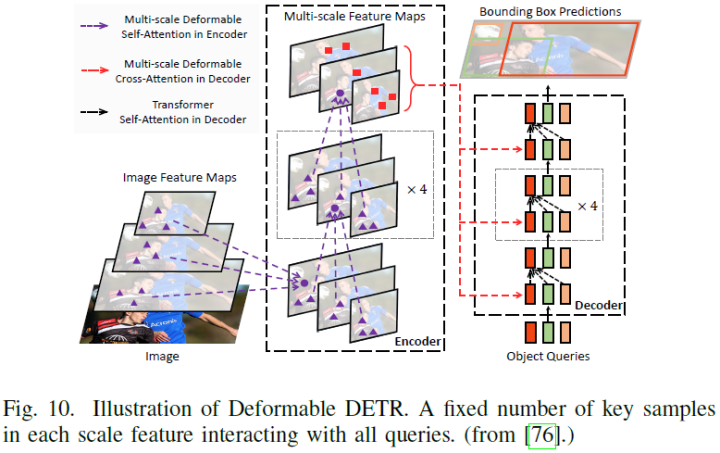
-
01.18 00:50:12发表了文章
2023-01-18 00:50:12
一文详解视觉Transformer在CV中的现状、趋势和未来方向(分类/检测/分割/多传感器融合)(上)
本综述根据三个基本的CV任务和不同的数据流类型,全面调查了100多种不同的视觉Transformer,并提出了一种分类法,根据其动机、结构和应用场景来组织代表性方法。由于它们在训练设置和专用视觉任务上的差异,论文还评估并比较了不同配置下的所有现有视觉Transformer。此外,论文还揭示了一系列重要但尚未开发的方面,这些方面可能使此类视觉Transformer能够从众多架构中脱颖而出,例如,松散的高级语义嵌入,以弥合视觉Transformer与序列式之间的差距。最后,提出了未来有前景的研究方向。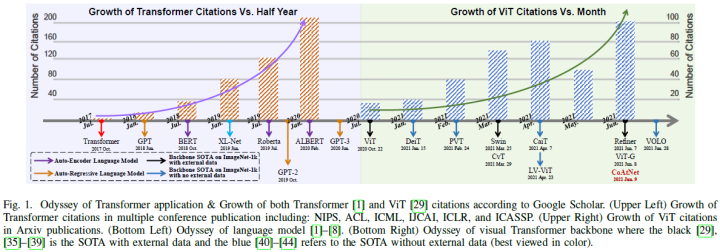
-
01.18 00:43:46发表了文章
2023-01-18 00:43:46
多传感器融合新思路!CRAFT:一种基于空间-语义信息互补的RV融合3D检测方法
为了解决late-fusion无法充分发挥两种模态互补性的缺点,作者提出了一种proposal-level的毫米波与相机融合方法,首先为了解决毫米波角分辨率低导致的难以区分径向物体以及多径干扰造成的假阳性幽灵点的问题,对毫米波数据使用图像数据进行增强生成带有语义特征的雷达特征,随后通过图像模态的预测框转换到极坐标系中自适应地融合增强后的雷达特征,完成了spatial-contextual两个层面的融合,融合结构采用了传统的transformer的encoder结构,完美地兼容了两个模态之间的数据结构上的差异,最后作者在nuScenes数据集上达到了mAP:41.1%和NDS:52.3%,相比B
-
01.18 00:37:28发表了文章
2023-01-18 00:37:28
史上最全 | 基于深度学习的3D分割综述(RGB-D/点云/体素/多目)(下)
3D目标分割是计算机视觉中的一个基本且具有挑战性的问题,在自动驾驶、机器人、增强现实和医学图像分析等领域有着广泛的应用。它受到了计算机视觉、图形和机器学习社区的极大关注。传统上,3D分割是用人工设计的特征和工程方法进行的,这些方法精度较差,也无法推广到大规模数据上。在2D计算机视觉巨大成功的推动下,深度学习技术最近也成为3D分割任务的首选。近年来已涌现出大量相关工作,并且已经在不同的基准数据集上进行了评估。本文全面调研了基于深度学习的3D分割的最新进展,涵盖了150多篇论文。论文总结了最常用的范式,讨论了它们的优缺点,并分析了这些分割方法的对比结果。并在此基础上,提出了未来的研究方向。
-
01.18 00:35:20发表了文章
2023-01-18 00:35:20
史上最全 | 基于深度学习的3D分割综述(RGB-D/点云/体素/多目)(上)
3D目标分割是计算机视觉中的一个基本且具有挑战性的问题,在自动驾驶、机器人、增强现实和医学图像分析等领域有着广泛的应用。它受到了计算机视觉、图形和机器学习社区的极大关注。传统上,3D分割是用人工设计的特征和工程方法进行的,这些方法精度较差,也无法推广到大规模数据上。在2D计算机视觉巨大成功的推动下,深度学习技术最近也成为3D分割任务的首选。近年来已涌现出大量相关工作,并且已经在不同的基准数据集上进行了评估。本文全面调研了基于深度学习的3D分割的最新进展,涵盖了150多篇论文。论文总结了最常用的范式,讨论了它们的优缺点,并分析了这些分割方法的对比结果。并在此基础上,提出了未来的研究方向。
-
01.18 00:28:59发表了文章
2023-01-18 00:28:59
2022最新!更面向工业场景:基于视觉方案不同挑战下的车道检测与跟踪(下)
本文作者提出了一种鲁棒的车道检测和跟踪方法来检测车道线,该方法主要介绍了三个关键技术。首先,应用双边滤波器来平滑和保留边缘,引入了一个优化的强度阈值范围(OITR)来提高canny算子的性能,该算子检测低强度(有色、腐蚀或模糊)车道标记的边缘。第二,提出了一种稳健的车道验证技术,即基于角度和长度的几何约束(ALGC)算法,然后进行霍夫变换,以验证车道线的特征并防止不正确的车道线检测。最后,提出了一种新的车道线跟踪技术,即水平可调车道重新定位范围(HALRR)算法,该算法可以在左、右或两条车道标记在短时间内部分和完全不可见时跟踪车道位置。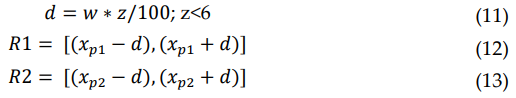
-
01.18 00:28:56发表了文章
2023-01-18 00:28:56
2022最新!更面向工业场景:基于视觉方案不同挑战下的车道检测与跟踪(上)
本文作者提出了一种鲁棒的车道检测和跟踪方法来检测车道线,该方法主要介绍了三个关键技术。首先,应用双边滤波器来平滑和保留边缘,引入了一个优化的强度阈值范围(OITR)来提高canny算子的性能,该算子检测低强度(有色、腐蚀或模糊)车道标记的边缘。第二,提出了一种稳健的车道验证技术,即基于角度和长度的几何约束(ALGC)算法,然后进行霍夫变换,以验证车道线的特征并防止不正确的车道线检测。最后,提出了一种新的车道线跟踪技术,即水平可调车道重新定位范围(HALRR)算法,该算法可以在左、右或两条车道标记在短时间内部分和完全不可见时跟踪车道位置。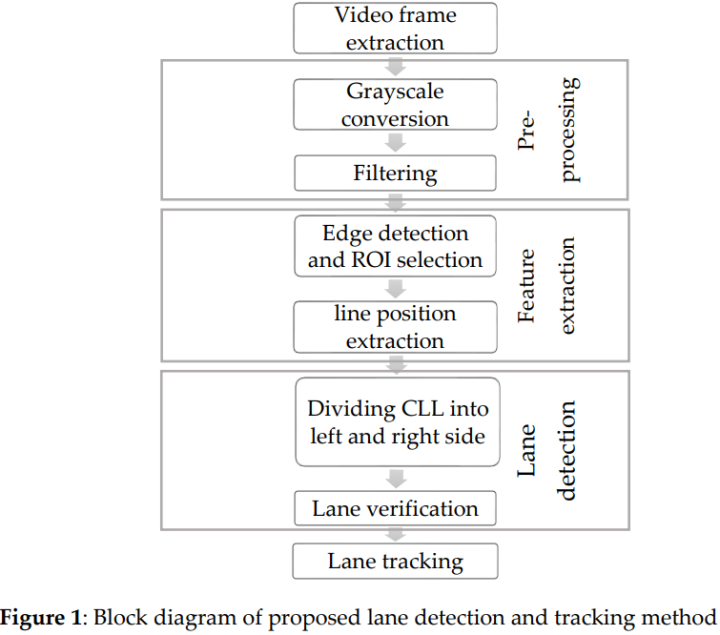
-
01.18 00:23:44发表了文章
2023-01-18 00:23:44
2022最新!视觉SLAM综述(多传感器/姿态估计/动态环境/视觉里程计)(下)
论文调查的主要目的是介绍VSLAM系统的最新进展,并讨论现有的挑战和未来趋势。论文对在VSLAM领域发表的45篇有影响力的论文进行了深入的调查,并根据不同的特点对这些方法进行了分类,包括novelty domain、目标、采用的算法和语义水平。最后论文讨论了当前的趋势和未来的方向,有助于研究人员进行研究。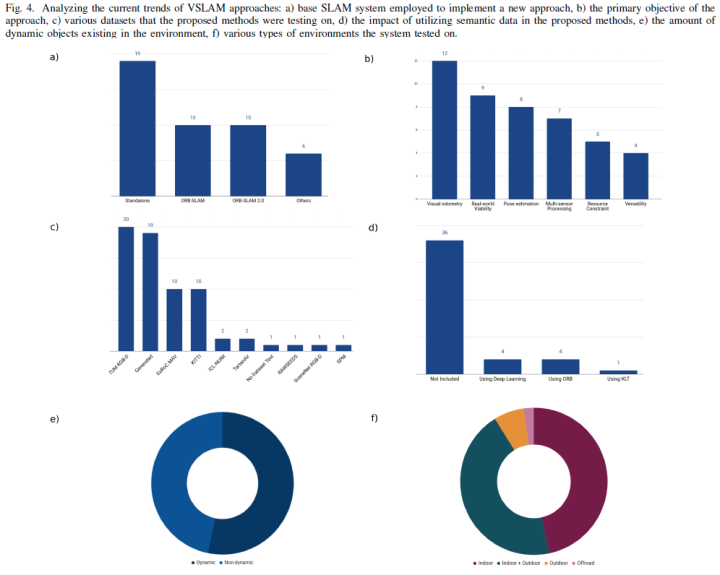
-
01.18 00:23:39发表了文章
2023-01-18 00:23:39
2022最新!视觉SLAM综述(多传感器/姿态估计/动态环境/视觉里程计)(上)
论文调查的主要目的是介绍VSLAM系统的最新进展,并讨论现有的挑战和未来趋势。论文对在VSLAM领域发表的45篇有影响力的论文进行了深入的调查,并根据不同的特点对这些方法进行了分类,包括novelty domain、目标、采用的算法和语义水平。最后论文讨论了当前的趋势和未来的方向,有助于研究人员进行研究。
-
01.18 00:17:39发表了文章
2023-01-18 00:17:39
ECCV 2022 | 稀有类别提升31%!如何解决3D检测中长尾问题?(Waymo最新)
在本项研究中,作者确定了一个新的概念维度-稀疏-挖掘新的数据,以提高模型在长尾问题上的表现。作者表明,稀有性,而不是困难性,是以数据为中心的3D 检测器改进的关键,因为稀有性是缺乏数据支持的结果,而困难性与问题的基本模糊性有关。提出了一种基于流模型的特征空间密度估计的稀有目标识别方法,并提出了一种基于代价感知的稀有目标tracks挖掘方法,提高了模型的整体性能,更重要的是显著提高了稀有目标的性能(提高了30.97%)。
-
01.18 00:13:46发表了文章
2023-01-18 00:13:46
一文尽览 | 全景/鱼眼相机低速自动驾驶的近距离感知(识别+重建+定位+工程化)(下)
本文的工作部分受到了Malik等人在[5]中的工作的启发。这项工作的作者提出,计算机视觉的核心问题是重建、识别和重组,他们称之为计算机视觉的3R。在此,论文建议将计算机视觉的3R扩展并专门化为自动驾驶计算机视觉的4R:重建、识别、重组和重新定位。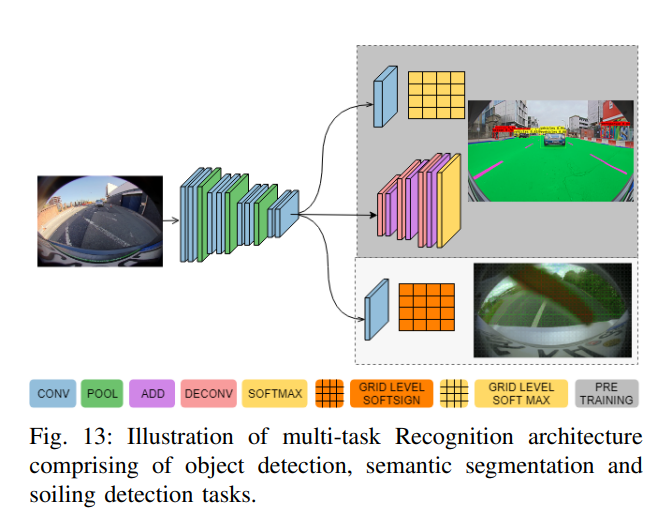
-
01.18 00:12:06发表了文章
2023-01-18 00:12:06
一文尽览 | 全景/鱼眼相机低速自动驾驶的近距离感知(识别+重建+定位+工程化)(上)
本文的工作部分受到了Malik等人在[5]中的工作的启发。这项工作的作者提出,计算机视觉的核心问题是重建、识别和重组,他们称之为计算机视觉的3R。在此,论文建议将计算机视觉的3R扩展并专门化为自动驾驶计算机视觉的4R:重建、识别、重组和重新定位。
-
01.18 00:08:53发表了文章
2023-01-18 00:08:53
手把手教学!TensorRT部署实战:YOLOv5的ONNX模型部署
手把手教学!TensorRT部署实战:YOLOv5的ONNX模型部署
-
01.18 00:04:58发表了文章
2023-01-18 00:04:58
大火的4D Radar数据集及基线模型汇总
Astyx数据集是第一个公开的包含4D雷达点云的数据集,提出了一个基于雷达、激光雷达和摄像机数据的以雷达为中心的汽车数据集,用于3D物体检测。主要重点是向研究界提供高分辨率雷达数据,刺激使用雷达传感器数据的算法研究。为此,提供了用于物体检测的半自动生成和手动重新定义的3D地面真实数据。论文描述了生成此类数据集的完整过程,重点介绍了相应高分辨率雷达的一些主要功能,并通过在此数据集上显示基于深度学习的3D对象检测算法的结果,展示了其在3-5级自动驾驶应用中的使用。
-
01.17 23:51:12发表了文章
2023-01-17 23:51:12
Nuscenes和KITTI双SOTA!3D目标检测中的同质多模态特征融合与交互(ECCV2022)
多模态3D物体检测一直是自动驾驶领域中的一个活跃研究课题,然而,探索稀疏3D点和密集2D像素之间的跨模态特征融合并非易事,最近的方法要么将图像特征与投影到2D图像平面上的点云特征融合,要么将稀疏点云与密集图像像素组合。这些融合方法经常遭受严重的信息丢失,从而导致性能次优。为了解决这些问题,本文构建了点云和图像之间的均匀结构,通过将相机特征转换到LiDAR 3D空间中来避免投影信息丢失。论文主要提出了一种用于三维目标检测的同质多模态特征融合与交互方法(HMFI)。具体来说,首先设计了一个图像体素提升模块(IVLM),以将2D图像特征提升到3D空间中并生成均匀图像体素特征。
-
01.17 23:46:17发表了文章
2023-01-17 23:46:17
nuScenes 纯视觉新SOTA!SOLOFusion:时序立体3D检测的新观点和基线
虽然最近基于纯视觉的3D检测方法利用了时序信息,但它们使用的有限历史信息限制了时序融合性能提升的上限。论文观察到现有多帧图像融合的本质是时序立体匹配,且目前算法的性能受到以下因素影响:1)匹配分辨率的低粒度;2)有限历史信息的使用产生的次优多目设置。
-
01.17 23:41:43发表了文章
2023-01-17 23:41:43
一文尽览 | 首篇Transformer在3D点云中的应用综述(检测/跟踪/分割/降噪/补全)(下)
Transformer 一直是自然语言处理 (NLP) 和计算机视觉 (CV) 的核心。NLP 和 CV 的巨大成功激发了研究者对 Transformer 在点云处理中的使用的探索。但是,Transformer如何应对点云的不规则性和无序性?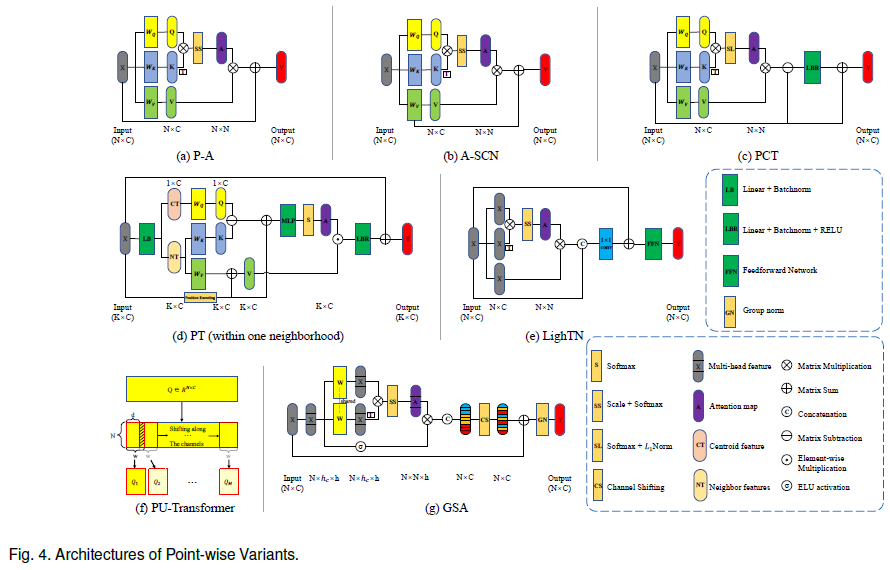
-
01.17 23:31:36发表了文章
2023-01-17 23:31:36
NVRadarNet:基于纯Radar的障碍物和可行驶区域检测(英伟达最新)
Free space定义为可行驶的网格区域。通过引入Lidar的标记数据对毫米波进行监督,能够有效增强毫米波对静态目标的感知能力的同时解决了毫米波数据难以标注的问题。另一方面作者通过预测dense occupancy probability map以生成RDM(radial distance map)用于自动驾驶路径规划。
-
01.17 23:27:44发表了文章
2023-01-17 23:27:44
Simple-BEV: 多传感器BEV感知真正重要的是什么?(斯坦福大学最新)
不依赖高密度激光雷达的无人驾驶车辆,构建3D感知系统是一个很关键的问题,因为与camera和其他传感器相比,激光雷达系统的成本较高。最近的工作开发了多种仅camera的方法,其中特征可从多camera图像“提升”到2D ground plane,从而生成3D空间的“鸟瞰图”(BEV)特征表示。这一系列工作产生了多种新颖的“提升”方法,但训练设置中的其他细节同时也发生了变化,这使得大家不清楚什么是最佳方法。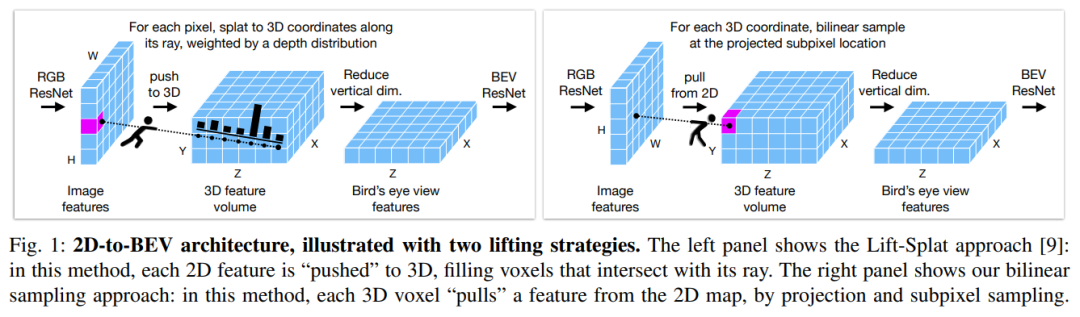
-
01.17 23:16:42发表了文章
2023-01-17 23:16:42
万字长文 | 多目标跟踪最新综述(基于Transformer/图模型/检测和关联/孪生网络)(下)
随着自动驾驶技术的发展,多目标跟踪已成为计算机视觉领域研究的热点问题之一。MOT 是一项关键的视觉任务,可以解决不同的问题,例如拥挤场景中的遮挡、相似外观、小目标检测困难、ID切换等。为了应对这些挑战,研究人员尝试利用transformer的注意力机制、利用图卷积神经网络获得轨迹的相关性、不同帧中目标与siamese网络的外观相似性,还尝试了基于简单 IOU 匹配的 CNN 网络、运动预测的 LSTM。为了把这些分散的技术综合起来,作者研究了过去三年中的一百多篇论文,试图提取出近年来研究者们更加关注的解决 MOT 问题的技术。
-
01.17 23:12:40发表了文章
2023-01-17 23:12:40
万字长文 | 多目标跟踪最新综述(基于Transformer/图模型/检测和关联/孪生网络)(上)
随着自动驾驶技术的发展,多目标跟踪已成为计算机视觉领域研究的热点问题之一。MOT 是一项关键的视觉任务,可以解决不同的问题,例如拥挤场景中的遮挡、相似外观、小目标检测困难、ID切换等。为了应对这些挑战,研究人员尝试利用transformer的注意力机制、利用图卷积神经网络获得轨迹的相关性、不同帧中目标与siamese网络的外观相似性,还尝试了基于简单 IOU 匹配的 CNN 网络、运动预测的 LSTM。为了把这些分散的技术综合起来,作者研究了过去三年中的一百多篇论文,试图提取出近年来研究者们更加关注的解决 MOT 问题的技术。
-
01.17 23:05:04发表了文章
2023-01-17 23:05:04
充分考虑工业真实场景!基于激光雷达相机融合的鲁棒3D目标检测benchmark
充分考虑工业真实场景!基于激光雷达相机融合的鲁棒3D目标检测benchmark
-
01.17 22:56:40发表了文章
2023-01-17 22:56:40
单目多帧自监督深度估计(2021-2022)研究进展
自从17年MonoDepth系列论文问世, 单目自监督深度估计算法越来越受到研究者的重视。人们发现, 在自动驾驶场景中,原来单目自监督方法也能计算出不错的深度效果。
-
发表了文章
2023-02-20
逐步揭开模型面纱!首篇深度视觉建模中的可解释AI综述
-
发表了文章
2023-02-20
面向工程,高精度高效率!Fast BEV:快速而强大的BEV感知基线(NIPS2022)
-
发表了文章
2023-02-20
目标跟踪 | 3D目标跟踪高级入门!
-
发表了文章
2023-02-20
3D目标检测中点云的稀疏性问题及解决方案
-
发表了文章
2023-02-20
美团最新!FastPillars:基于Pillar的最强3D检测落地方案
-
发表了文章
2023-02-20
单目3D检测入门!从图像角度分析3D目标检测场景:MonoDLE
-
发表了文章
2023-02-20
最新综述!基于视觉的自动驾驶环境感知(单目、双目和RGB-D)
-
发表了文章
2023-02-20
诺亚最新!AOP-Net:一体式3D检测和全景分割的感知网络
-
发表了文章
2023-02-20
最新导航综述!SLAM方法/数据集/传感器融合/路径规划与仿真多个主题(下)
-
发表了文章
2023-02-20
最新导航综述!SLAM方法/数据集/传感器融合/路径规划与仿真多个主题(上)
-
发表了文章
2023-02-04
高精地图落地 | InstaGraM:实时端到端矢量化高精地图新SOTA!
-
发表了文章
2023-02-04
首篇BEV感知生成工作!BEVGen:从鸟瞰图布局生成环视街景图像
-
发表了文章
2023-02-04
TPAMI 2022 | 视觉transformer最新调研!(下)
-
发表了文章
2023-02-04
TPAMI 2022 | 视觉transformer最新调研!(上)
-
发表了文章
2023-02-04
3D车道线检测能否成为自动驾驶的核心?盘一盘近三年的SOTA论文!(下)
-
发表了文章
2023-02-04
3D车道线检测能否成为自动驾驶的核心?盘一盘近三年的SOTA论文!(上)
-
发表了文章
2023-02-04
最新鱼眼BEV感知 | FPNet:面向泊车场景的失真不敏感多任务算法(TIV 2022)(下)
-
发表了文章
2023-02-04
最新鱼眼BEV感知 | FPNet:面向泊车场景的失真不敏感多任务算法(TIV 2022)(上)
-
发表了文章
2023-02-04
实时部署!DSVT:3D动态稀疏体素Transformer主干(北大&华为)
-
发表了文章
2023-02-04
V2X会是未来趋势吗?看看这种轻量级方法,大幅降低碰撞概率!
滑动查看更多
暂无更多信息
暂无更多信息