云祁

已加入开发者社区1699天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

开发者认证勋章
开发者认证勋章

江湖新秀
江湖新秀



我关注的人








粉丝

技术能力
兴趣领域
- Java
- Go
- 容器
- 数据库
擅长领域
技术认证
-
-
 Apsara Clouder大数据技能认证:MOOC网站日志分析
获得于2020-04-15 10:23:31
Apsara Clouder大数据技能认证:MOOC网站日志分析
获得于2020-04-15 10:23:31 -
Apsara Clouder大数据技能认证:使用时间序列分解模型预测商品销量
获得于2020-04-14 17:15:03
-
Apsara Clouder大数据技能认证:基于机器学习PAI实现精细化营销
获得于2020-04-13 16:36:34
-
Apsara Clouder大数据技能认证:使用Quick BI 制作企业数据分析报表
获得于2020-04-10 17:10:39
-
-
-
阿里云大数据助理工程师认证(ACA)
获得于2020-04-15 10:23:47
-
暂无个人介绍
暂无精选文章
暂无更多信息
2022年06月
-
06.14 22:51:36
 发表了文章
2022-06-14 22:51:36
发表了文章
2022-06-14 22:51:36
数仓实践:浅谈 Kimball 维度建模2
数仓实践:浅谈 Kimball 维度建模2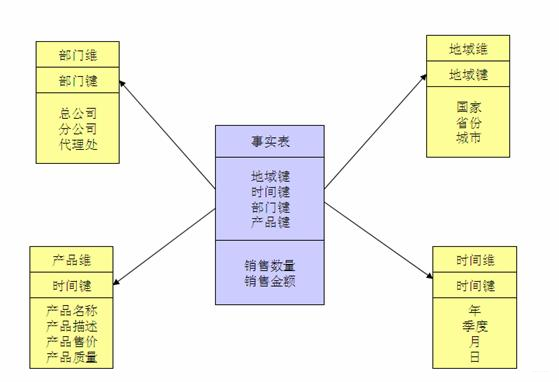
-
06.14 22:51:00发表了文章
2022-06-14 22:51:00
数仓实践:浅谈 Kimball 维度建模1
数仓实践:浅谈 Kimball 维度建模1
-
06.14 22:50:36发表了文章
2022-06-14 22:50:36
数仓实践:总线矩阵架构设计2
数仓实践:总线矩阵架构设计2 -
06.14 22:49:32发表了文章
2022-06-14 22:49:32
数仓实践:总线矩阵架构设计1
数仓实践:总线矩阵架构设计1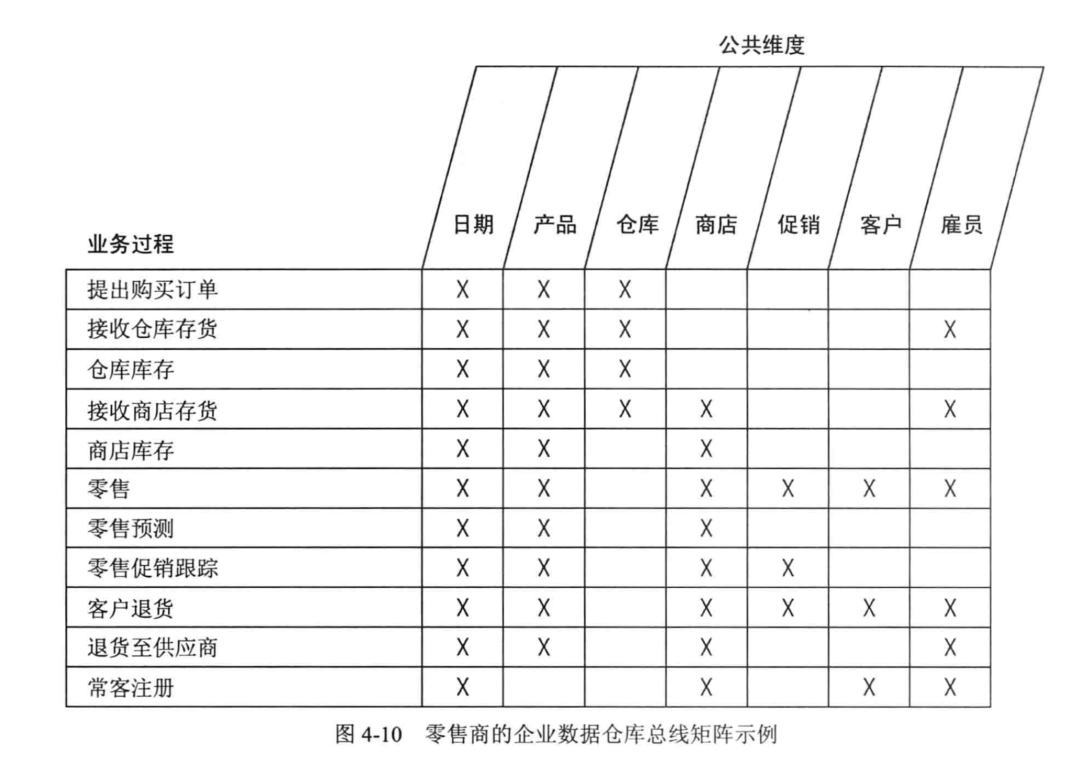
-
06.14 22:46:57发表了文章
2022-06-14 22:46:57
数仓建设:数据域和主题域是什么关系?
数仓建设:数据域和主题域是什么关系?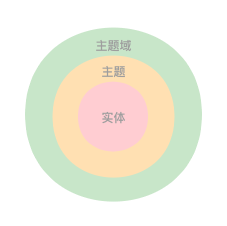
-
06.14 22:33:20发表了文章
2022-06-14 22:33:20
如何构建用户画像,给用户打“标签”?2
如何构建用户画像,给用户打“标签”?2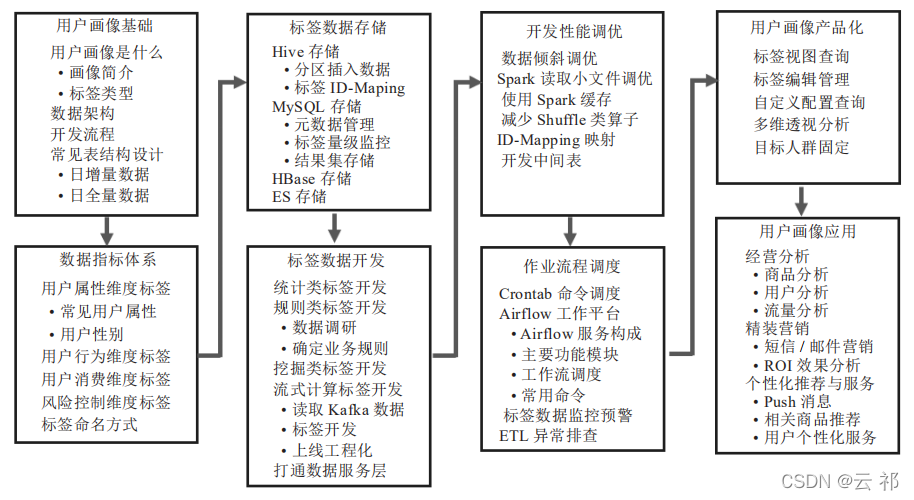
-
06.14 22:33:17发表了文章
2022-06-14 22:33:17
如何构建用户画像,给用户打“标签”?1
如何构建用户画像,给用户打“标签”?1
-
06.14 22:20:45发表了文章
2022-06-14 22:20:45
Hive 调优集锦,让 Hive 调优想法不再碎片化3
Hive 调优集锦,让 Hive 调优想法不再碎片化3 -
06.14 22:20:40发表了文章
2022-06-14 22:20:40
Hive 调优集锦,让 Hive 调优想法不再碎片化2
Hive 调优集锦,让 Hive 调优想法不再碎片化2
-
06.14 22:20:35发表了文章
2022-06-14 22:20:35
Hive 调优集锦,让 Hive 调优想法不再碎片化1
Hive 调优集锦,让 Hive 调优想法不再碎片化1
-
06.14 21:34:58发表了文章
2022-06-14 21:34:58
数据能力的构建过程
数据能力的构建过程 -
06.14 21:30:40发表了文章
2022-06-14 21:30:40
如何优雅的设计DWS层?
如何优雅的设计DWS层?
-
06.14 21:27:39发表了文章
2022-06-14 21:27:39
什么是OneData?阿里数据中台实施方法论解读
什么是OneData?阿里数据中台实施方法论解读
-
06.14 21:22:35发表了文章
2022-06-14 21:22:35
数据仓库常见建模方法与大数据领域建模实例综述
数据仓库常见建模方法与大数据领域建模实例综述
-
06.14 21:18:07发表了文章
2022-06-14 21:18:07
真的了解 HDFS 的 SecondaryNameNode 是干什么的?
真的了解 HDFS 的 SecondaryNameNode 是干什么的?
-
06.14 21:15:11发表了文章
2022-06-14 21:15:11
大白话彻底搞懂 HBase Rowkey 设计和实现方式
大白话彻底搞懂 HBase Rowkey 设计和实现方式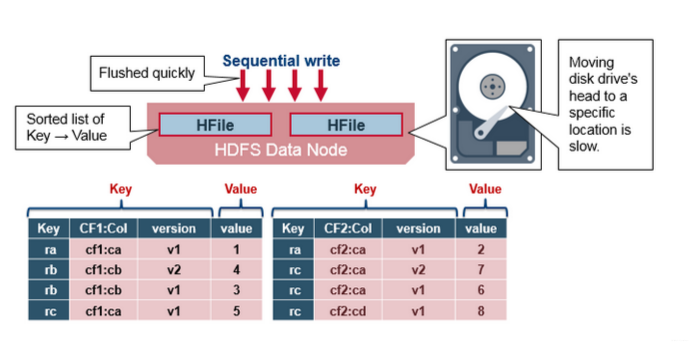
-
06.14 21:11:55发表了文章
2022-06-14 21:11:55
Hadoop 数据仓库建设实践(理论结合实践)
Hadoop 数据仓库建设实践(理论结合实践)
-
06.14 21:07:38发表了文章
2022-06-14 21:07:38
聊聊数据仓库中维度表设计的二三事
聊聊数据仓库中维度表设计的二三事
-
06.14 21:00:39发表了文章
2022-06-14 21:00:39
干货 | Apache Flink 入门技术分享 PPT(多图预警)2
干货 | Apache Flink 入门技术分享 PPT(多图预警)2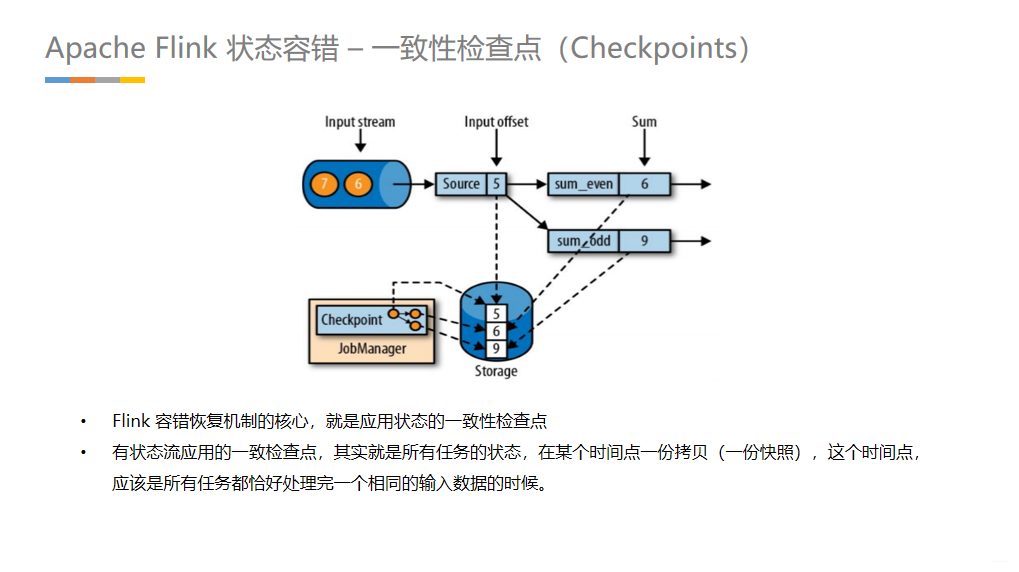
-
06.14 21:00:36发表了文章
2022-06-14 21:00:36
干货 | Apache Flink 入门技术分享 PPT(多图预警)1
干货 | Apache Flink 入门技术分享 PPT(多图预警)1
-
06.14 20:51:31发表了文章
2022-06-14 20:51:31
浅谈大数据建模的主要技术:维度建模
浅谈大数据建模的主要技术:维度建模
-
06.14 20:44:53发表了文章
2022-06-14 20:44:53
《离线和实时大数据开发实战》(五)Hive 优化实践2
《离线和实时大数据开发实战》(五)Hive 优化实践2
-
06.14 20:44:50发表了文章
2022-06-14 20:44:50
《离线和实时大数据开发实战》(五)Hive 优化实践1
《离线和实时大数据开发实战》(五)Hive 优化实践1
-
06.14 20:30:13发表了文章
2022-06-14 20:30:13
《离线和实时大数据开发实战》(四)Hive 原理实践2
《离线和实时大数据开发实战》(四)Hive 原理实践2
-
06.14 20:30:04发表了文章
2022-06-14 20:30:04
《离线和实时大数据开发实战》(四)Hive 原理实践1
《离线和实时大数据开发实战》(四)Hive 原理实践1
-
06.14 20:15:38发表了文章
2022-06-14 20:15:38
面试官最爱问的「Hive调优」,17个切入点带你一举拿下2
面试官最爱问的「Hive调优」,17个切入点带你一举拿下2
-
06.14 20:15:35发表了文章
2022-06-14 20:15:35
面试官最爱问的「Hive调优」,17个切入点带你一举拿下 1
面试官最爱问的「Hive调优」,17个切入点带你一举拿下 1
-
06.14 20:07:44发表了文章
2022-06-14 20:07:44
JVM 从入门到精通(八)JVM运行时数据区——本地方法栈
JVM 从入门到精通(八)JVM运行时数据区——本地方法栈
-
06.14 20:06:13发表了文章
2022-06-14 20:06:13
《离线和实时大数据开发实战》(三)Hadoop原理实战
《离线和实时大数据开发实战》(三)Hadoop原理实战
-
06.14 20:02:36发表了文章
2022-06-14 20:02:36
JVM 从入门到精通(七)本地方法接口
JVM 从入门到精通(七)本地方法接口
-
06.14 19:58:56发表了文章
2022-06-14 19:58:56
《离线和实时大数据开发实战》(二)大数据平台架构 & 技术概览2
《离线和实时大数据开发实战》(二)大数据平台架构 & 技术概览2
-
06.14 19:58:53发表了文章
2022-06-14 19:58:53
《离线和实时大数据开发实战》(二)大数据平台架构 & 技术概览1
《离线和实时大数据开发实战》(二)大数据平台架构 & 技术概览1
-
06.14 19:51:44发表了文章
2022-06-14 19:51:44
《离线和实时大数据开发实战》(一)构建大数据开发知识体系图谱
《离线和实时大数据开发实战》(一)构建大数据开发知识体系图谱
-
06.14 19:47:32发表了文章
2022-06-14 19:47:32
JVM 从入门到精通(六)JVM运行时数据区——虚拟机栈3
JVM 从入门到精通(六)JVM运行时数据区——虚拟机栈3
-
06.14 19:47:29发表了文章
2022-06-14 19:47:29
JVM 从入门到精通(六)JVM运行时数据区——虚拟机栈2
JVM 从入门到精通(六)JVM运行时数据区——虚拟机栈2
-
06.14 19:47:23发表了文章
2022-06-14 19:47:23
JVM 从入门到精通(六)JVM运行时数据区——虚拟机栈1
JVM 从入门到精通(六)JVM运行时数据区——虚拟机栈1
-
06.14 19:10:14发表了文章
2022-06-14 19:10:14
通俗易懂 !Kafka 开发快速入门看这篇就够了3
通俗易懂 !Kafka 开发快速入门看这篇就够了3 -
06.14 19:10:09发表了文章
2022-06-14 19:10:09
通俗易懂 !Kafka 开发快速入门看这篇就够了2
通俗易懂 !Kafka 开发快速入门看这篇就够了2
-
06.14 19:10:04发表了文章
2022-06-14 19:10:04
通俗易懂 !Kafka 开发快速入门看这篇就够了1
通俗易懂 !Kafka 开发快速入门看这篇就够了1
-
06.13 23:41:13发表了文章
2022-06-13 23:41:13
【Kafka】(二十四)轻量级流计算 Kafka Streams 实践总结
【Kafka】(二十四)轻量级流计算 Kafka Streams 实践总结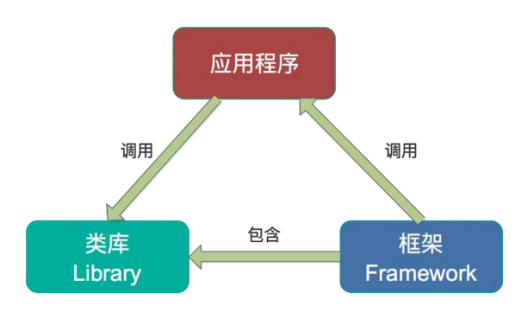
-
06.13 23:36:03发表了文章
2022-06-13 23:36:03
【MySQL】(十三)浅谈 MySQL 索引优化分析2
【MySQL】(十三)浅谈 MySQL 索引优化分析2
-
06.13 23:36:00发表了文章
2022-06-13 23:36:00
【MySQL】(十三)浅谈 MySQL 索引优化分析1
【MySQL】(十三)浅谈 MySQL 索引优化分析1
-
06.13 23:28:59发表了文章
2022-06-13 23:28:59
【Flume】(六)Flume 开发实战案例分享3
【Flume】(六)Flume 开发实战案例分享3
-
06.13 23:28:51发表了文章
2022-06-13 23:28:51
【Flume】(六)Flume 开发实战案例分享2
【Flume】(六)Flume 开发实战案例分享2
-
06.13 23:28:47发表了文章
2022-06-13 23:28:47
【Flume】(六)Flume 开发实战案例分享1
【Flume】(六)Flume 开发实战案例分享1
-
06.13 23:02:26发表了文章
2022-06-13 23:02:26
【Kylin】(二)Apache Kylin 环境搭建
【Kylin】(二)Apache Kylin 环境搭建
-
06.13 22:59:07发表了文章
2022-06-13 22:59:07
【Kylin】(一)初识 Apache Kylin 2
【Kylin】(一)初识 Apache Kylin 2
-
发表了文章
2022-06-14
数仓实践:浅谈 Kimball 维度建模2
-
发表了文章
2022-06-14
数仓实践:浅谈 Kimball 维度建模1
-
发表了文章
2022-06-14
数仓实践:总线矩阵架构设计2
-
发表了文章
2022-06-14
数仓实践:总线矩阵架构设计1
-
发表了文章
2022-06-14
数仓建设:数据域和主题域是什么关系?
-
发表了文章
2022-06-14
如何构建用户画像,给用户打“标签”?2
-
发表了文章
2022-06-14
如何构建用户画像,给用户打“标签”?1
-
发表了文章
2022-06-14
Hive 调优集锦,让 Hive 调优想法不再碎片化3
-
发表了文章
2022-06-14
Hive 调优集锦,让 Hive 调优想法不再碎片化2
-
发表了文章
2022-06-14
Hive 调优集锦,让 Hive 调优想法不再碎片化1
-
发表了文章
2022-06-14
数据能力的构建过程
-
发表了文章
2022-06-14
如何优雅的设计DWS层?
-
发表了文章
2022-06-14
什么是OneData?阿里数据中台实施方法论解读
-
发表了文章
2022-06-14
数据仓库常见建模方法与大数据领域建模实例综述
-
发表了文章
2022-06-14
真的了解 HDFS 的 SecondaryNameNode 是干什么的?
-
发表了文章
2022-06-14
大白话彻底搞懂 HBase Rowkey 设计和实现方式
-
发表了文章
2022-06-14
Hadoop 数据仓库建设实践(理论结合实践)
-
发表了文章
2022-06-14
聊聊数据仓库中维度表设计的二三事
-
发表了文章
2022-06-14
干货 | Apache Flink 入门技术分享 PPT(多图预警)2
-
发表了文章
2022-06-14
干货 | Apache Flink 入门技术分享 PPT(多图预警)1
滑动查看更多
暂无更多信息
暂无更多信息