

勋章








我关注的人






粉丝









技术能力
-
Java
高级
能力说明:
精通JVM运行机制,包括类生命、内存模型、垃圾回收及JVM常见参数;能够熟练使用Runnable接口创建线程和使用ExecutorService并发执行任务、识别潜在的死锁线程问题;能够使用Synchronized关键字和atomic包控制线程的执行顺序,使用并行Fork/Join框架;能过开发使用原始版本函数式接口的代码。
暂时未有相关云产品技术能力~
管住嘴,迈开腿。一个努力接受现在的自己的程序员。






-
发表了文章 2025-01-25
【JUC进阶】01. Synchroized实现原理
Synchronized是在并发编程中很经常使用,Java中除了提供Lock等API来实现互斥以外,还提供了语法(关键字)层面的Synchronized来实现互斥同步原语,今天闲来聊聊Synchronized关键字。
-
发表了文章 2023-07-12
【JUC基础】17. 并发编程常见问题
多线程固然可以提升系统的吞吐量,也可以最大化利用系统资源,提升相应速度。但同时也提高了编程的复杂性,也提升了程序调试的门槛。今天就来汇总一些常见的并发编程中的问题。
-
发表了文章 2023-06-13
【JUC基础】16. Fork Join
“分而治之”一直是一个非常有效的处理大量数据的方法。著名的MapReduce也是采取了分而治之的思想。。简单地说,就是如果你要处理 1000 个数据,但是你并不具备处理 1000个数据的能力,那么你可以只处理其中的 10 个,然后分阶段处理 100 次,将 100 次的结进行合成,就是最终想要的对原始 1000 个数据的处理结果。而这就是Fork Join的基本思想。
-
发表了文章 2023-06-06
【JUC基础】15. Future模式
Future 模式是多线程开发中非常常见的一种设计模式,它的核心思想是异步调用。当我们需要调用一个函数方法时,如果这个函数执行得很慢,那么我们就要进行等待。但有时候,我们可能并不急着要结果。因此,我们可以让被调者立即返回,让它在后台慢慢处理这个请求。对于调用者来说,则可以先处理一些其他任务,在真正需要数据的场合再去尝试获得需要的数据。
-
发表了文章 2023-06-04
【JUC基础】14. ThreadLocal
一般提到多线程并发总是要说资源竞争,线程安全。而通常保证线程安全的其中一种方式便是控制资源的访问,也就是加锁。其实还有另一种方式,那么便是增加资源来保证所有对象不竞争少数资源。比如,有100个人需要填写信息表,如果只有一只笔,那么要么变成串行,一个一个填写,要么就是我写一半你写一半。那么如果准备100只笔,100个人每个人都有一只笔能够填写信息表,那么就不会出现竞争的情况,也就能顺利的保证信息表的填写。这支笔也就是我们今天要说的ThreadLocal。
-
发表了文章 2023-06-03
【JUC基础】13. 线程池(二)
我们继续前面的《【JUC基础】12.线程池(一)》。
-
发表了文章 2023-05-31
【JUC基础】12. 线程池(一)
我们知道多线程的使用,是为了最大限度发挥现代多核处理器的计算能力,提高系统的吞吐量和性能。但是如果不加以控制和管理,随意使用多线程,对系统性能反而会有不利的影响。线程数量和系统CPU资源是息息相关的,随意使用甚至可能会耗尽系统CPU资源和内存资源。
-
发表了文章 2023-05-28
【JUC基础】11. 并发下的集合类
我们直到ArrayList,HashMap等是线程不安全的容器。但是我们通常会频繁的在JUC中使用集合类,那么应该如何确保线程安全?
-
发表了文章 2023-05-25
【JUC基础】10. Atomic原子类
Atomic英译为原子的。原子结构通常称为不可分割的最小单位。而在JUC中,java.util.concurrent.atomic 包是 Java 并发库中的一个包,提供了原子操作的支持。它包含了一些原子类,用于在多线程环境下进行线程安全的原子操作。使用原子类可以避免使用锁和同步机制,从而减少了线程竞争和死锁的风险,并提高了多线程程序的性能和可伸缩性。
-
发表了文章 2023-05-22
【JUC基础】09. LockSupport
LockSupport是一个线程阻塞工具,可以在线程任意位置让线程阻塞。线程操作阻塞的方式其实还有Thread.suspend()和Object.wait()。而LockSupport与suspend()相比,弥补了由于resume()方法而导致线程被挂起(类似死锁)的问题,也弥补了wait()需要先获得某个对象锁的问题,也不会抛出InterruptedException异常。
-
发表了文章 2023-05-18
【JUC基础】08. 三大工具类
JUC包中包含了三个非常实用的工具类:CountDownLatch(倒计数器),CyclicBarrier(循环栅栏),Semaphore(信号量)。
-
发表了文章 2023-05-10
【JUC基础】06. 生产者和消费者问题
学习JUC,就不得不提生产者消费者。生产者消费者模型是一种经典的多线程模型,用于解决生产者和消费者之间的数据交换问题。在生产者消费者模型中,生产者生产数据放入共享的缓冲区中,消费者从缓冲区中取出数据进行消费。在这个过程中,生产者和消费者之间需要保持同步,以避免数据出现错误或重复。今天我们就来说说生产者消费者模型,以及JUC中如何解决该模型的同步问题。
-
发表了文章 2023-05-10
【JUC基础】05. Synchronized和ReentrantLock
前面两篇中分别讲了Synchronized和ReentrantLock。两种方式都能实现同步锁,且也都能解决多线程的并发问题。那么这两个有什么区别呢? 这个也是一个高频的面经题。
-
发表了文章 2023-05-09
【JUC基础】04. Lock锁
java.util.concurrent.locks为锁定和等待条件提供一个框架的接口和类,说白了就是锁所在的包。
-
发表了文章 2023-05-09
【JUC基础】02. JUC思维导图
juc思维导图,用于JUC内容学习
-
发表了文章 2023-05-01
【JUC基础】01. 初步认识JUC
前段时间,有朋友跟我说,能否写一些关于JUC的教程文章。本来呢,JUC也有在我的专栏计划之内,只是一直都还没空轮到他,那么既然有这样的一个契机,那就把JUC计划提前吧。那么今天就重点来初步认识一下什么是JUC,以及一些基本的JUC相关基础知识。
-
发表了文章 2023-04-18
ChatGPT生成一篇文章:关于Docker
如今AI智能如火如荼,如果不会点ChatGPT总感觉有点落后了。最近刚好重新复习了一遍Docker,这里尝试通过ChatGPT来生成一篇关于Docker文章。来看效果。
-
发表了文章 2023-04-12
【JUC基础】03. 几段代码看懂synchronized
程序员经常听到“并发锁”这个名词,而且实际项目中也确实避免不了要加锁。那么什么是锁?锁的是什么?今天文章从8个有意思的案例,彻底弄清这两个问题。
-
发表了文章 2023-04-11
无聊小知识.04 以下代码会输出什么?
今天同事给我看了一段代码,然后这段简单的代码,我却陷入了沉思。
-
发表了文章 2023-04-09
无聊小知识.03 wait(),notify()虚假唤醒
无聊小知识.03 wait(),notify()虚假唤醒
-
发表了文章 2023-04-06
HTML编写圣诞树代码
HTML编写圣诞树代码
-
发表了文章 2023-04-05
【Spring源码】Spring事务原理
事务是访问并可能更新数据库中各种数据项的一个程序执行单元,这个操作单元要么全部执行成功,要么全部执行失败。同时也是恢复和并发控制的基本单位。
-
发表了文章 2023-04-04
Netty之EventLoop
EventLoop本质是一个单线程执行器(同时维护了一个Selector),里面有run方法处理channel上源源不断的io事件。
-
发表了文章 2023-04-04
Netty入门Demo
Netty入门Demo
-
发表了文章 2023-04-02
NIO消息黏包和半包处理
我们在进行NIO编程时,通常会使用缓冲区进行消息的通信(ByteBuffer),而缓冲区的大小是固定的。那么除非你进行自动扩容(Netty就是这么处理的),否则的话,当你的消息存进该缓冲区就会存在消息边界的问题,典型的边界问题就是黏包和半包现象。
-
发表了文章 2023-04-02
【Spring源码】循环依赖如何处理?
面试官:“看过Spring源码吧,简单说说Spring如何解决循环依赖问题?” 大神仙:“Spring利用到了三级缓存来解决循环依赖问题”。 面试官:“三级缓存是怎么处理的?为什么一定得是三级缓存?三级缓存别是对应存储的是什么?” 大神仙:“......”
-
发表了文章 2023-04-01
【Spring源码】讲讲Bean的生命周期
面试官:“看过Spring源码吧,简单说说Spring中Bean的生命周期”
-
发表了文章 2023-03-30
【Spring源码】 BeanFactory和FactoryBean是什么?
面试官:“看过Spring源码吧,简单说说Spring中BeanFactory和FactoryBean的区别是什么?”
-
发表了文章 2023-03-27
关于netty的EventLoop
关于netty的EventLoop
-
发表了文章 2023-03-26
JVM学习.05 JVM常见的排障和调优
前面介绍了JVM相关的内存和线程相关的技术。对于JVM也算有了一个比较系统、完整的理论基础。理论总是作为指导实践的工具,但是从理论到实践,总会遇到一些虚拟机相关问题,故障。所以还需要学习一些常用的JVM排障工具,和一些常见的调优手段。
-
发表了文章 2023-03-25
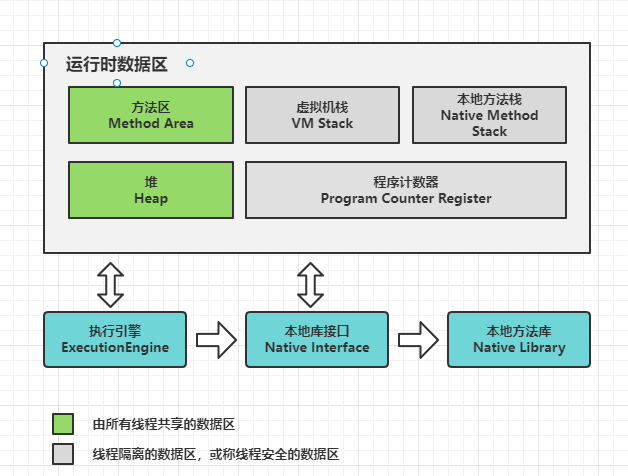
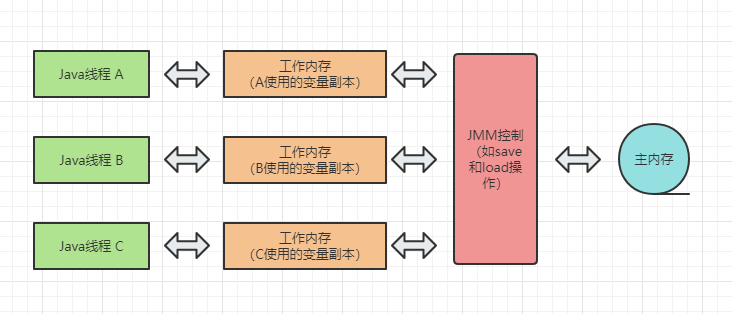
JVM学习.04. Java内存模型与线程模型
该篇内容主要介绍JVM如何实现多线程,多线程间由于共享和竞争数据而导致的一系列问题以及解决方案。
-
发表了文章 2023-03-24
JVM学习.03 类加载机制
从事Java开发工作的都知道,Java程序提交到JVM运行时,需要编译成Class文件,才能被JVM加载运行。那么这些Class文件进入到虚拟机后会发生什么?以及Class是如何被加载的?这些都是本文要讲解的部分。
-
发表了文章 2023-03-23
Redis获取数据转json,解决动态泛型传参
项目有两种角色需要不同的登录权限,将redis做为用户登录信息缓存数据库。码一个方法,希望能够根据传入不用用户实体类型来获取相应的数据。用户实体为:SessionEntity<User1>、SessionEntity<User2>。json使用FastJson。
-
发表了文章 2023-03-23
SpringMVC自定义注解验证登陆拦截
这里业务场景需要,所有的请求都需要登录验证。个别通用业务不需要登录拦截。注解方式替代原有的if判断。
-
发表了文章 2023-03-23
springmvc+redis实现简单消息队列
springmvc+redis实现简单消息队列
-
发表了文章 2023-03-23
java线上项目排查,Arthas简单上手
java线上项目排查,Arthas简单上手
-
发表了文章 2023-03-23
springboot集成swagger2出现404解决方案汇总
springboot集成swagger2出现404解决方案汇总
-
发表了文章 2023-03-23
Vue-cli打包线上Nginx访问,css样式无效解决
Vue-cli打包线上Nginx访问,css样式无效解决
-
发表了文章 2023-03-23
使用Aop+Redis+lua限流,优化高并发问题
应用层也是需要做限流操作的。这里简单结合Aop+redis+lua来实现。注:如果是需要接入层先流的话,建议还是要使用nginx自带的连接数限流模块和请求限流模块。
-
发表了文章 2023-03-21
JVM学习.02 内存分配和回收策略
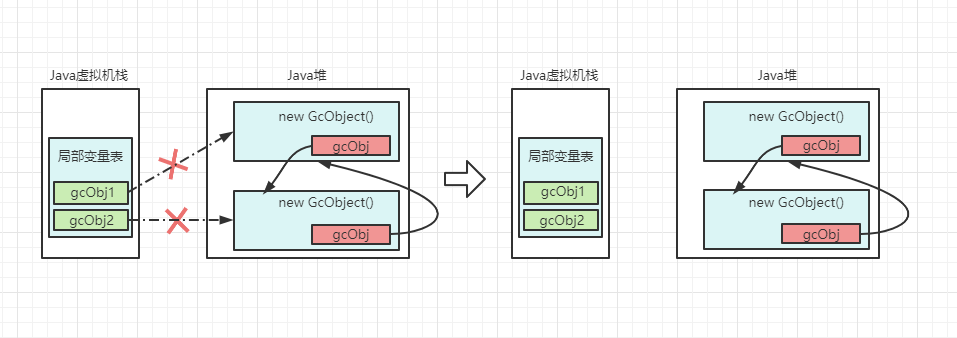
《JVM学习.01 内存模型》篇讲述了JVM的内存布局,其中每个区域是作用,以及创建实例对象的时候内存区域的工作流程。上文还讲到了关于对象存货后,会被回收清理的过程。今天这里就着重讲一下对象实例是如何被清理回收的,以及清理回收的几种算法。
-
发表了文章 2023-03-20
Linux小白基础环境搭建汇总
以Centos7为例。由于系统是新购买的,所以这里(未使用docker)进行了ssh端口修改,防火墙配置,磁盘挂载,创建用户,JDK,Mysql,Redis,Nginx等安装。
-
发表了文章 2023-03-20
@Data注解导致的StackOverflowError
Springboot项目中使用Lombok,实体采用@Data注解。运行过程中报Caused by: java.lang.StackOverflowError。
-
发表了文章 2023-03-20
Centos基础环境搭建--安装docker
Centos基础环境搭建--安装docker
-
发表了文章 2023-03-20
Centos基础环境--docker安装mysql8.0
Centos基础环境--docker安装mysql8.0
-
发表了文章 2023-03-20
Centos基础环境--docker安装Redis
Centos基础环境--docker安装Redis
-
发表了文章 2023-03-20
docker安装Mysql8.0的坑之lower_case_table_names
docker安装Mysql8.0的坑之lower_case_table_names
-
发表了文章 2023-03-20
Centos应用“Cannot allocate memory”的解决方案
Centos应用“Cannot allocate memory”的解决方案
-
发表了文章 2023-03-20
Linux单机MySQL数据库自动备份
Linux单机MySQL数据库自动备份
-
发表了文章 2023-03-20
XSS攻击及AntiSamy防御
跨站脚本攻击(Cross Site Scripting),因为跟样式css混淆,所以习惯缩写为xss。通过一些方法注入恶意指令代码到网页,使其加载并执行攻击者恶意的网页程序。
-
发表了文章 2023-03-19
Synchroinzed对Integer的问题
Synchroinzed对Integer的问题
-
 发表了文章
2025-01-25
发表了文章
2025-01-25
【JUC进阶】01. Synchroized实现原理
-
发表了文章
2023-07-12
【JUC基础】17. 并发编程常见问题
-
发表了文章
2023-06-13
【JUC基础】16. Fork Join
-
发表了文章
2023-06-06
【JUC基础】15. Future模式
-
发表了文章
2023-06-04
【JUC基础】14. ThreadLocal
-
发表了文章
2023-06-03
【JUC基础】13. 线程池(二)
-
发表了文章
2023-05-31
【JUC基础】12. 线程池(一)
-
发表了文章
2023-05-28
【JUC基础】11. 并发下的集合类
-
发表了文章
2023-05-25
【JUC基础】10. Atomic原子类
-
发表了文章
2023-05-22
【JUC基础】09. LockSupport
-
发表了文章
2023-05-18
【JUC基础】08. 三大工具类
-
发表了文章
2023-05-10
【JUC基础】06. 生产者和消费者问题
-
发表了文章
2023-05-10
【JUC基础】05. Synchronized和ReentrantLock
-
发表了文章
2023-05-09
【JUC基础】04. Lock锁
-
发表了文章
2023-05-09
【JUC基础】02. JUC思维导图
-
发表了文章
2023-05-01
【JUC基础】01. 初步认识JUC
-
发表了文章
2023-04-18
ChatGPT生成一篇文章:关于Docker
-
发表了文章
2023-04-12
【JUC基础】03. 几段代码看懂synchronized
-
发表了文章
2023-04-11
无聊小知识.04 以下代码会输出什么?
-
发表了文章
2023-04-09
无聊小知识.03 wait(),notify()虚假唤醒

-
 回答了问题
2023-04-01
回答了问题
2023-04-01
3.31世界备份日:你都在使用哪些备份方式?
个人数据一般都会采用云端备份。 项目数据除了采用云端备份外,一般还会单机热备份,以及异地冷备份。 目前我们ECS服务器都会保留最近一周的服务镜像,数据2天一次本机备份,1周一次异地服务器备份。赞2 踩0 评论0 -
回答了问题
2023-03-31
如何评价GPT-4?
GPT-4是GPT系列模型的最新版本,预计将比GPT-3更强大和更智能。GPT-4将使用更先进的算法和更大的数据集进行训练,预计会取得比GPT-3更好的成果。 如果GPT-4能够取得GPT-3的进展,那么它可能会在自然语言生成和理解方面有更出色的表现,甚至能够实现更复杂的任务,如在广泛范围内实现更高水平的语音识别、机器翻译、对话系统和智能搜索等。 但是,也需要注意到随着模型规模的增大,训练和部署GPT-4将会面临更多的技术和伦理挑战。例如,由于GPT-4将需要更多的计算资源和数据,其训练成本和能耗将更高。此外,由于GPT-4的语言生成能力可能会变得更加逼真,因此需要考虑如何应对可能带来的潜在伦理问题,例如信息误导和虚假新闻的扩散等。 总之,GPT-4可能会成为自然语言处理领域的一个里程碑,但也需要在技术和伦理方面进行更全面和深入的讨论和探索。赞2 踩0 评论1 -
回答了问题
2023-03-19
自建还是托管,你会如何选择?
首先各有优缺点。基于以下考虑: 1. 预算:自建服务器需要投入大量的资金和时间来购买和设置硬件、软件和网络。而托管服务器可能需要支付一个月度或年度费用,但不需要专门购买设备或维护设备,这意味着成本可能更低。 安全性:自建服务器需要您确定和执行所有安全措施,包括安装防病毒软件、防火墙等,这些需要专业的 IT 人员才能有效管理。而托管服务器通常由专业的 IT 团队管理,它们提供额外的安全保障。 可扩展性:自建服务器需要预测并调整硬件和带宽需求。而托管服务器通常提供灵活的扩容选项,因此它们通常更容易适应变化的需求。 人员支持:自建服务器需要耗费更多的时间、人力和技术,而托管服务器由专业的 IT 团队管理,可以提供更多支持,这意味着您的员工可以有更多精力投入到其他工作。 因此,根据业务需求和可行性,选择自建服务器还是托管服务器取决于特定情况。赞1 踩0 评论0 -
回答了问题
2023-03-19
开发者参与开源软件项目有哪些好处?
学习机会:开发者可以通过参与开源软件项目了解其内部运作,学习其他开发者的技能和实践,提高自己的技术和知识水平。 接触专业人士:与其他开发者和贡献者合作,可以很好地学习合作和沟通技能,并扩展自己的人际关系。 增强经验:参与开源软件项目可以提高经验和知识储备,包括代码开发,测试和错误修正。 赚取信誉:贡献者可以通过提交代码,为开源社区做出贡献,获得认可和信誉,并在自己的职业生涯中受益。提升个人品牌:参与开源软件项目可以提高个人品牌和知名度,使个人更加受欢迎和受尊重。共享资源:开源软件项目为开发者提供了一个共享资源和协作的平台,使开发者可以利用其他开发者的资源和工具,更好地完成自己的工作。促进创新:开源软件项目提供了一个促进创新的环境,鼓励开发者分享和交流新的思想和创意,创造出更好更强大的软件产业。赞9 踩0 评论0 -
回答了问题
2023-03-19
请问如果来自应用程序的流量突然激增,OSS 如何保证业务的可用性?
有以下几种方法可以保证 OSS 业务的可用性: 使用智能流控制:OSS 提供智能限流功能,可以根据流量状况动态调整限流策略,保障流量控制。 利用 CDN 缓存:OSS 可以与 CDN 配合使用,通过全球分布的 CDN 节点,加速数据的传输和访问,降低服务器负载。 多副本存储:OSS 会将数据自动复制到多个物理节点中,当某些节点出现故障时,可以自动切换到其他节点,确保数据的高可用性和可靠性。 自动扩容:当流量激增时,OSS 可以自动进行扩容,提升服务器的处理能力,保障业务的运行和响应速度。 及时监控:OSS 提供实时监控和报警功能,能够及时掌握业务状况,预警风险,做好应对措施,确保业务的稳定运行。赞0 踩0 评论0 -
回答了问题
2023-03-19
请问OSS的数据是如何组织的?
来自chatGpt的回答: OSS(阿里云对象存储服务)的数据是以对象(Object)为单位组织的。每个对象都有一个唯一的名称(Object Name)和键(Object Key),并且可以存储一定大小的数据(Object Data),最大支持单个对象的大小为48.8TB。同时,每个对象还可以包含一些元数据,例如文件大小、修改时间、ETag和内容类型等。这些元数据可以用来描述对象的特征和信息。 在OSS中,对象按照Bucket进行组织,一个Bucket可以存储多个对象,同时可以对对象进行上传、下载、复制、删除等操作。Bucket也可以设置存储类型,如标准存储、低频访问存储、归档存储等,以满足不同的存储需求。 总之,OSS的数据以对象为单位进行组织,通过Bucket进行管理和存储,并可以附加元数据进行描述和管理。赞0 踩0 评论0 -
回答了问题
2023-03-19
假设你是面试官,你会如何考核面试者的专业技能?
基础技能:如基本的实现原理是什么,如果扩展,项目中如何使用? 变通能力:例举特殊场景,应用所学技术如何设计,遇到问题如何处理等。 过往项目中,遇到并自己解决掉的最难的技术问题是什么?这里基本就可以知道以往项目所使用技能水平的深浅。 最后问一些学习计划,以及学习心得。考察的是自主学习能力和潜力。赞1 踩0 评论0 -
回答了问题
2023-03-15
乘风问答官3月排位赛开启!话题、问题双赛道,Apple Watch 3 等你赢!
重在参与赞0 踩0 评论0