modelscope-funasr的SenseVoiceLarge模型在哪里啊?
这个模型现在开源的只有small版的没有Large版的所以没有下载的地方
并不是所有的模型都会开源的!
回答不易请采纳
访问 ModelScope 平台:打开浏览器,访问 ModelScope 的官方网站。
搜索模型:在搜索框中输入 "FunASR" 或 "SenseVoiceLarge" 来查找相关模型。
查看模型详情:在模型的详情页面,你可以查看模型的描述、性能指标、使用示例和文档。
下载或使用模型:根据页面上的指示,你可以下载模型到本地使用,或者直接在云端使用模型提供的服务。
集成到应用中:根据提供的API文档和示例代码,将模型集成到你的应用程序中。
若要寻找或了解更多关于SenseVoiceLarge模型的详情,建议直接访问阿里云的ModelScope(魔搭社区)官方网站,通过搜索关键词“SenseVoice”或“大型语音模型”来查找相关的模型。ModelScope平台汇聚了多种预训练模型,包括但不限于语音、自然语言处理等领域,因此有可能能找到符合您需求的SenseVoiceLarge模型或相似功能的大型语音处理模型[3]。
相关链接
https://www.aliyun.com/solution/tech-solution/fc-for-ai-server
访问魔塔社区的官方网站或其在 Hugging Face 的页面,查看是否有关于 SenseVoiceLarge 模型的信息。
https://gitee.com/zhyqieqie/SenseVoice
https://www.modelscope.cn/search?page=1&search=SenseVoice&spm=a2c6h.13066369.question.5.548f6bc6IHD3XV&type=default
SenseVoiceLarge模型可以在modelscope和huggingface的仓库中找到。
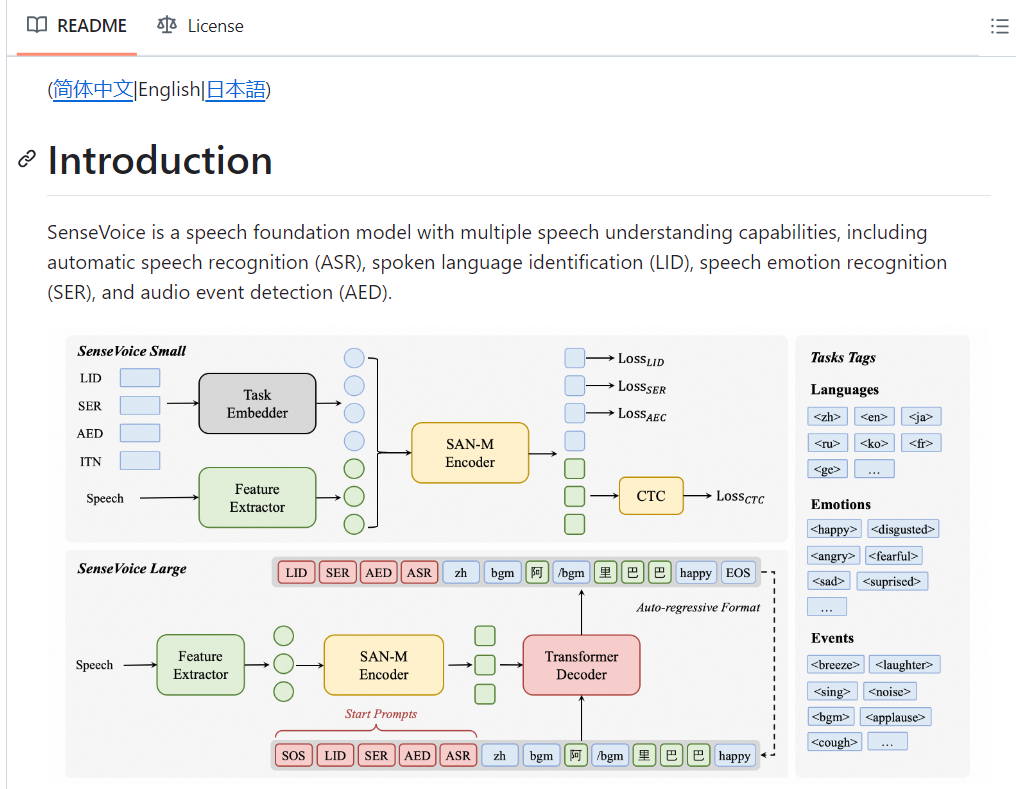
SenseVoice是一系列具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种识别(LID)、语音情感识别(SER)以及声学事件分类(AEC)或声学事件检测(AED)。这些模型在多个任务测试集上进行了benchmark,并提供了体验模型所需的环境安装与推理方式。
具体到SenseVoiceLarge模型,虽然直接提及的资料较少,但根据SenseVoice系列的一般信息,可以推测该模型同样遵循上述功能和特性。对于希望深入了解或使用SenseVoiceLarge模型的用户,建议直接访问相关的GitHub仓库以获取最新的模型文件、文档和示例代码。
modelscope-funasr的SenseVoiceLarge模型目前尚未开源。
根据现有信息,SenseVoiceLarge是一个支持超过50种语言的高精度自动语音识别(ASR)模型。该模型在设计上旨在提供更加精准的语音理解能力,并且能够适应多种应用场景的需求。尽管其技术细节和部分功能已经通过相关文献和报告对外公开,但完整的模型代码和预训练权重并未发布给公众。
官方渠道:建议首先关注modelscope-funasr项目的官方仓库(如GitHub或Gitee等),以及阿里云开发者社区等官方平台,以获取最新的开源信息和模型更新。
社区交流:参与modelscope-funasr的社区交流,如钉钉群、微信群等,与其他开发者分享和讨论关于SenseVoiceLarge模型的最新动态和获取途径。
第三方资源:虽然不是官方渠道,但一些第三方平台或开发者可能会分享他们自己的SenseVoiceLarge模型实现或变体。然而,这些资源的可靠性和准确性需要谨慎评估。
ModelScope-FUNASR的SenseVoiceLarge模型是针对语音合成任务设计的一个大型模型。然而具体的获取渠道需要根据ModelScope平台或FUNASR项目提供的官方信息来确定。ModelScope是一个提供模型服务的平台,类似于模型的“淘宝”,用户可以在上面找到各种模型服务,包括但不限于语音合成。而FUNASR是阿里巴巴达摩院推出的一个开源自动语音识别工具包。如果您希望使用SenseVoiceLarge模型,建议访问ModelScope平台或者查看与FUNASR相关的开源项目页面,以获取最新的模型资源和使用指南。请确保遵循平台的使用条款及开源许可协议。
ModelScope-FunASR 是由达摩院开发的语音识别框架,它提供了多种预训练模型以适应不同的应用场景。提到的 "SenseVoiceLarge" 模型并不直接对应于 ModelScope-FunASR 中的官方命名,这可能是指某个特定配置或者是一个自定义的模型名称。
如果你正在寻找一个大型的、高质量的语音识别模型,并且这个模型被称为 "SenseVoiceLarge",那么你可能需要检查以下几点来找到该模型:
文档和资源:查阅 ModelScope-FunASR 的官方文档或 GitHub 仓库,看是否有提及到名为 "SenseVoiceLarge" 或者类似的大型模型。通常,官方文档会列出所有可用的预训练模型及其下载链接。
社区和论坛:在相关的开发者社区或论坛中询问,有时候其他开发者可能会分享他们自己训练的模型或者是知道如何获取这样的模型。
联系支持:如果上述途径都找不到,你可以尝试联系 ModelScope-FunASR 的支持团队或开发者,询问是否有一个叫做 "SenseVoiceLarge" 的模型存在以及如何获取它。
自定义训练:如果没有现成的 "SenseVoiceLarge" 模型,你可能需要根据自己的需求使用 FunASR 框架自行训练一个大型模型。这通常需要大量的标注数据、计算资源以及时间。
商汤科技产品:由于 "Sense" 前缀也与商汤科技(SenseTime)相关联,所以有可能是混淆了两个不同公司的产品。如果你是在查找商汤科技的产品,请访问他们的官方网站或联系其技术支持获取相关信息。
请确保你所指的 "SenseVoiceLarge" 确实存在于 ModelScope-FunASR 的上下文中。如果是误称或是来自另一个项目的模型,请提供更多的背景信息以便更准确地帮助你。如果有具体的链接或来源可以参考,那将更有助于定位正确的模型。