DataWorks调用了python写的udf,为什么有这个报错?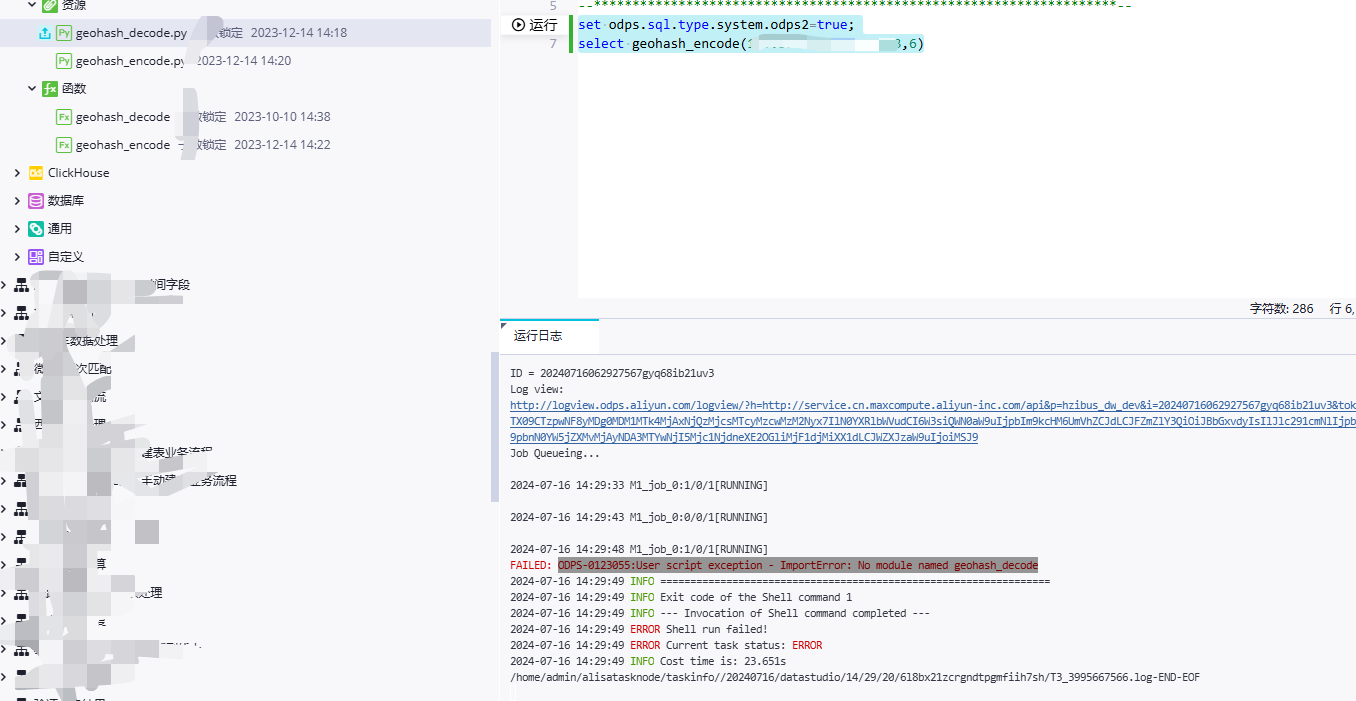
odps-0123055:User script exception - ImportError: No module named geohash_decode
就是调用了a函数,但是提示b函数不存在。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
确认您的UDF函数定义是否符合DataWorks的要求,例如是否有正确的返回类型声明。
确认函数体内的逻辑是否正确,例如变量作用域、数据类型转换等。
参考
确认资源类型(如Python脚本应为PY类型)和版本是最新的。
Python环境:如果使用非ASCII字符,确保代码在Python 2环境下兼容或考虑使用Python 3。
权限检查:确认调用UDF的用户有足够权限访问UDF及其依赖资源。
操作步骤:
使用list functions;确认UDF存在。
使用desc function ;检查UDF详细信息。
如有必要,使用desc resource ;检查资源类型。
检查用户权限,确保有访问权限。
在DataWorks中调用Python编写的用户定义函数(UDF)时遇到报错,可能由多种原因引起。以下是一些常见的问题及其解决方案:
环境配置问题:
确保DataWorks中配置了正确的Python环境。DataWorks可能支持特定的Python版本,如果你的UDF使用了不兼容的Python版本特性,可能会引发错误。
检查DataWorks是否支持你使用的Python库和依赖。有些库可能因为版权、安全或兼容性问题在DataWorks环境中不可用。
UDF代码问题:
检查UDF代码是否有语法错误或逻辑错误。
确保UDF函数的输入参数和返回类型与DataWorks的期望一致。
DataWorks调用Python写的UDF时出现报错,可能有以下几种原因:
Python环境问题:确保DataWorks使用的Python环境与您本地开发环境的Python版本一致。不同版本的Python可能存在语法差异或库的兼容性问题。
依赖库问题:检查您的Python UDF是否依赖于特定的第三方库。如果这些库没有正确安装在DataWorks环境中,可能会导致运行时错误。确保所有需要的库都已安装,并且版本兼容。
代码逻辑问题:检查您的Python UDF代码是否存在逻辑错误或语法错误。请确保代码能够正常运行,并且符合DataWorks的要求。
权限问题:确认DataWorks有足够的权限访问您的Python UDF文件和相关资源。如果权限不足,可能会导致无法加载或执行UDF。
输入输出格式问题:检查您的Python UDF是否正确处理了输入数据和返回结果。确保输入数据的格式与预期相符,并且UDF能够正确处理并返回期望的结果。
如果您能提供具体的错误信息或堆栈跟踪,我可以更准确地帮助您诊断问题并提供解决方案。
您在使用DataWorks的过程中遇到的问题是:当尝试运行一个Python UDF时,出现了错误消息"ODPS-0123055: User script exception - ImportError: No module named geohash_decode"。这表明您的Python环境无法找到名为geohash_decode的模块。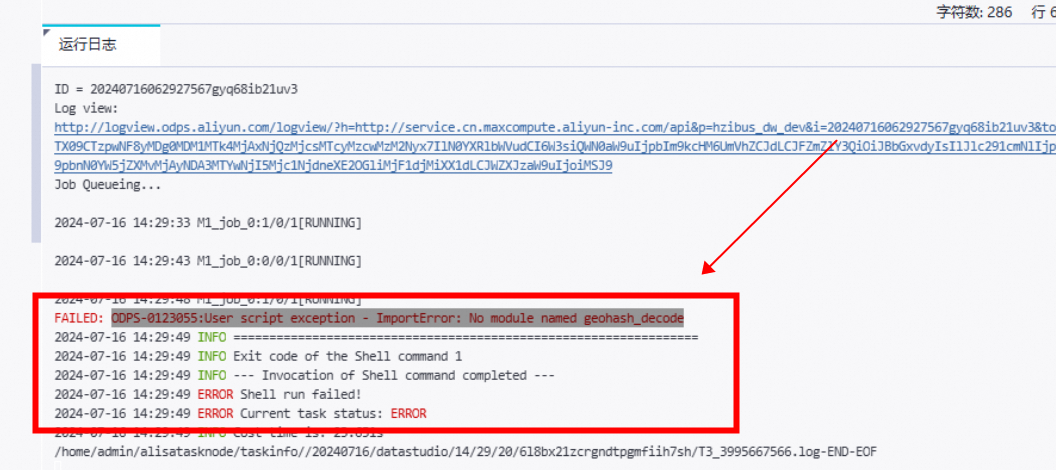
您可以按照以下步骤操作:
确认geohash_decode.py文件是否存在于正确的位置。通常情况下,Python UDF文件需要放在指定的目录下,以便DataWorks能够找到它们。
检查geohash_decode.py文件中是否有语法错误或者导入其他依赖项的问题。确保所有必要的库和模块都已经安装并且可以正常工作。
如果geohash_decode.py文件没有问题,那么可能是DataWorks的Python解释器路径设置不正确。请检查您的项目配置,确保Python解释器指向了正确的目录。
如果您是在本地开发环境中编写和测试代码,然后将其部署到生产环境,可能还需要将geohash_decode.py文件复制到生产环境中的相同位置。
要准确地解决您遇到的问题,需要具体的错误信息和上下文。不过,基于您提到的是DataWorks调用Python编写的UDF(User-Defined Function)时出现错误,我可以给出一些常见的问题及排查方法。
通常情况下,DataWorks在调用Python UDF时出现问题的原因可能包括但不限于以下几点:
Python环境问题:
UDF语法问题:
依赖库路径问题:
资源包问题:
权限问题:
日志和调试信息:
数据问题:
编码问题:
为了更进一步的帮助,请提供具体的错误信息或描述,这样我可以更好地分析问题所在并提供针对性的解决方案。如果您手头有具体的错误提示信息,请分享给我。
如果遇到错误消息 "No module named",这通常意味着Python解释器在执行UDF时找不到您尝试导入的模块。以下是一些可能的原因和解决方法:
import sys
sys.path.append("/path/to/your/module")
--py-files参数:.zip文件,并使用--py-files参数在提交PySpark作业时上传。No module named
没有找到这个模型,没有导包, 或者相关的依赖有问题,第三方依赖里面没有这个包,版本看看是不是有问题
ODPS-0123055:Script exception
模块:PROCESSOR。
严重等级:5。
触发条件:脚本异常。
处理方法:当遇到UDF报错时,请参考UDF常见问题中的类或依赖问题行排查处理。
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/sql-errors?spm=a2c4g.11186623.0.i57
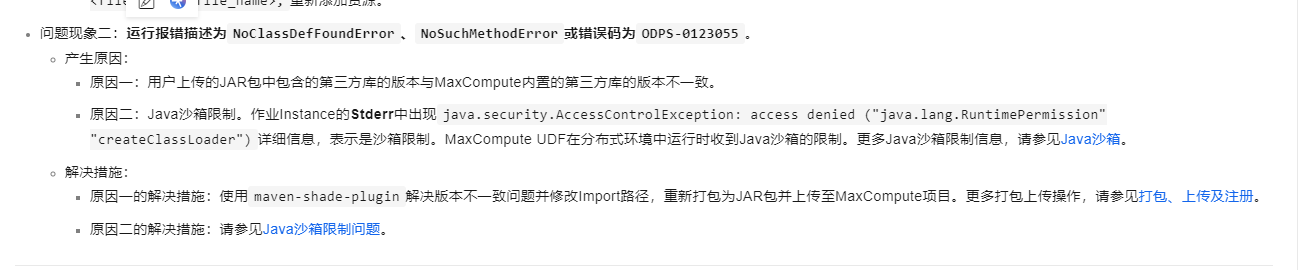
运行报错描述为NoClassDefFoundError、NoSuchMethodError或错误码为ODPS-0123055。
产生原因:
原因一:用户上传的JAR包中包含的第三方库的版本与MaxCompute内置的第三方库的版本不一致。
原因二:Java沙箱限制。作业Instance的Stderr中出现java.security.AccessControlException: access denied ("java.lang.RuntimePermission" "createClassLoader")详细信息,表示是沙箱限制。MaxCompute UDF在分布式环境中运行时收到Java沙箱的限制。更多Java沙箱限制信息,请参见Java沙箱。
解决措施:
原因一的解决措施:使用maven-shade-plugin解决版本不一致问题并修改Import路径,重新打包为JAR包并上传至MaxCompute项目。更多打包上传操作,请参见打包、上传及注册。
原因二的解决措施:请参见Java沙箱限制问题。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。