
在modelscope-funasr为啥语音文件还有很长一段没有识别出来呢?是不是有什么参数要设置?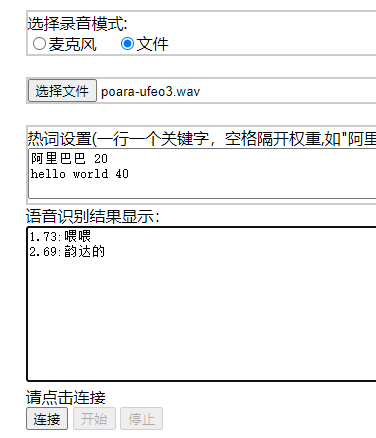

这个问题已修复,需要更新下html客户端代码
https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/sample/funasr_samples.tar.gz 此回答整理自钉群“modelscope-funasr社区交流”
在使用ModelScope FunASR进行语音识别时,如果没有文本输出,可能有以下几种原因:
网络问题:如果你的网络连接不稳定或者速度较慢,可能会导致识别过程长时间没有反应。你可以尝试更换网络环境或者提高网络速度。
服务器问题:如果FunASR的服务器出现故障或者过载,也可能导致识别无法进行。你可以尝试稍后再进行识别,或者联系FunASR的技术支持。
文件格式问题:如果你的录音文件格式不正确,可能会导致识别无法进行。你可以检查一下你的录音文件格式,确保它是正确的。
文件大小问题:如果你的录音文件过大,可能会导致识别过程耗时较长。你可以尝试将录音文件分割成较小的部分,然后分别进行识别。
模型问题:如果FunASR的模型存在问题,也可能导致识别无法进行。你可以尝试联系FunASR的技术支持,看看他们是否能提供帮助。
总的来说,如果你多次尝试都无法解决问题,我建议你联系FunASR的技术支持,看看他们是否能帮助你解决问题。

