
DataWorks中CDH hive任务开发时任务能执行成功,请分析下原因及解决方案?
DataWorks中CDH hive任务开发时任务能执行成功,但发布后任务执行失败,报错日志:/bin/bash: /opt/taobao/tbdpapp/cdhwrapper/cdh.sh: 没有那个文件或目录 , ERROR Shell run failed!,请分析下原因及解决方案?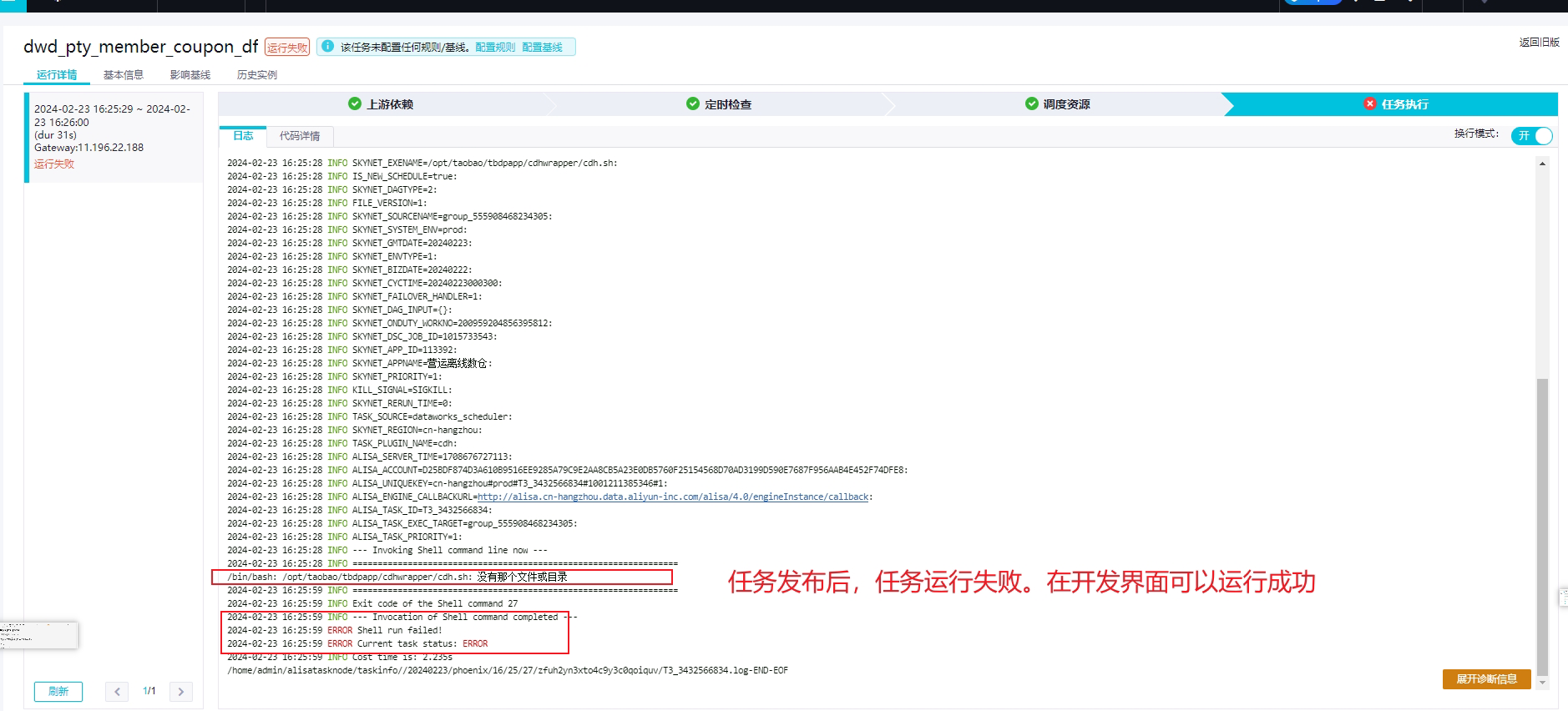
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
这个错误提示表示在执行任务时,系统找不到
/opt/taobao/tbdpapp/cdhwrapper/cdh.sh这个文件。可能的原因有:文件路径错误:请检查
/opt/taobao/tbdpapp/cdhwrapper/cdh.sh这个文件是否存在,以及文件路径是否正确。文件权限问题:请确保DataWorks有足够的权限访问该文件。可以尝试修改文件权限,例如使用
chmod命令:chmod 755 /opt/taobao/tbdpapp/cdhwrapper/cdh.sh环境变量问题:请检查是否设置了正确的环境变量,以便系统能够找到
cdh.sh文件。可以在脚本中添加以下内容来设置环境变量:export PATH=$PATH:/opt/taobao/tbdpapp/cdhwrapper脚本错误:请检查
cdh.sh脚本中是否存在错误,例如语法错误、逻辑错误等。
解决方案:
检查并修复文件路径错误。
修改文件权限,确保DataWorks有足够的权限访问该文件。
设置正确的环境变量。
检查并修复脚本错误。
2024-02-25 19:15:55赞同 展开评论 -
节点右侧调度配置中修改一下调度资源组 改成初始化成功的独享调度资源组

目前看使用了公共资源组 ,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2024-02-25 12:15:10赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。