
请问大数据计算MaxCompute,这个是什么原因?
请问大数据计算MaxCompute,这个是什么原因?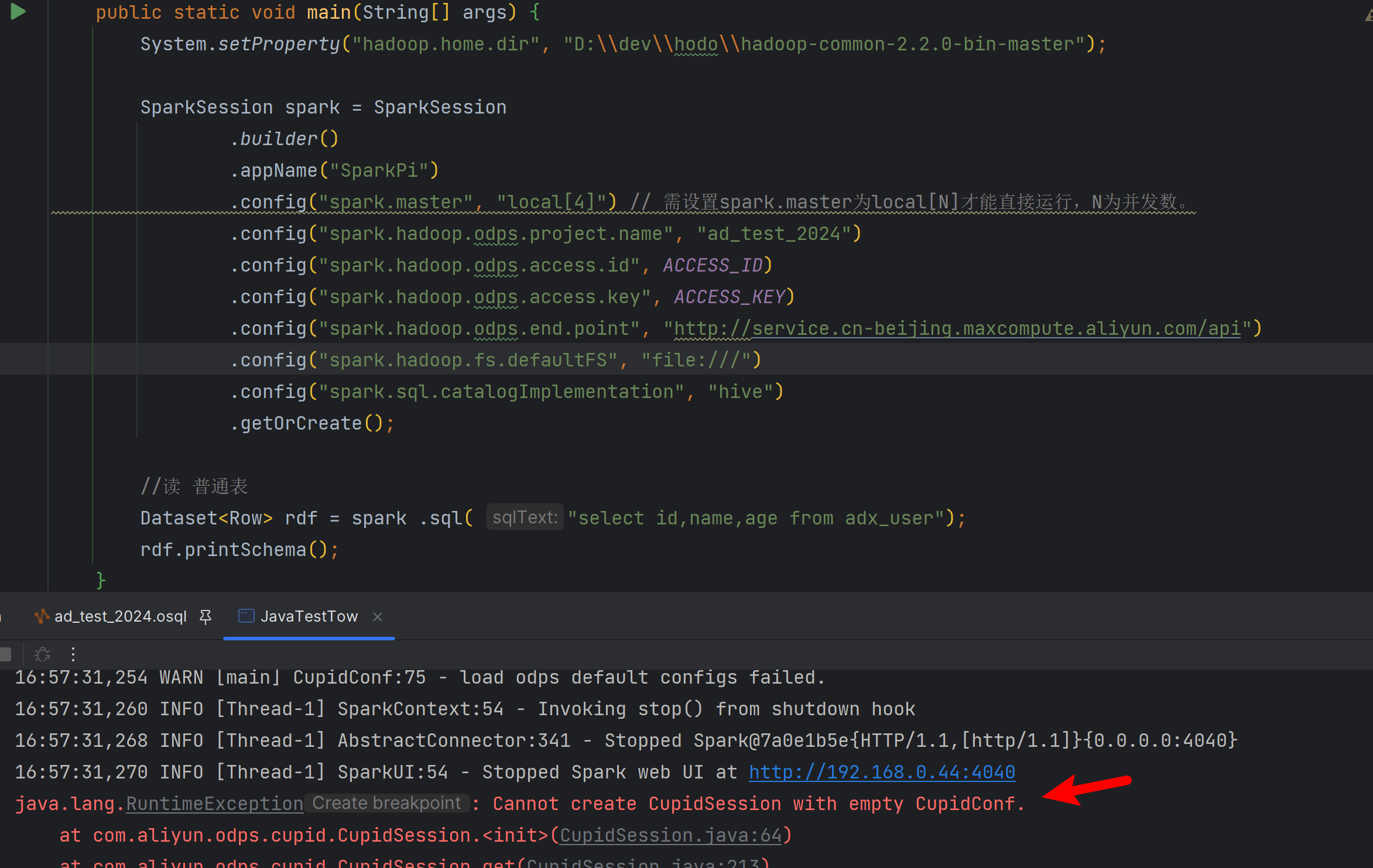
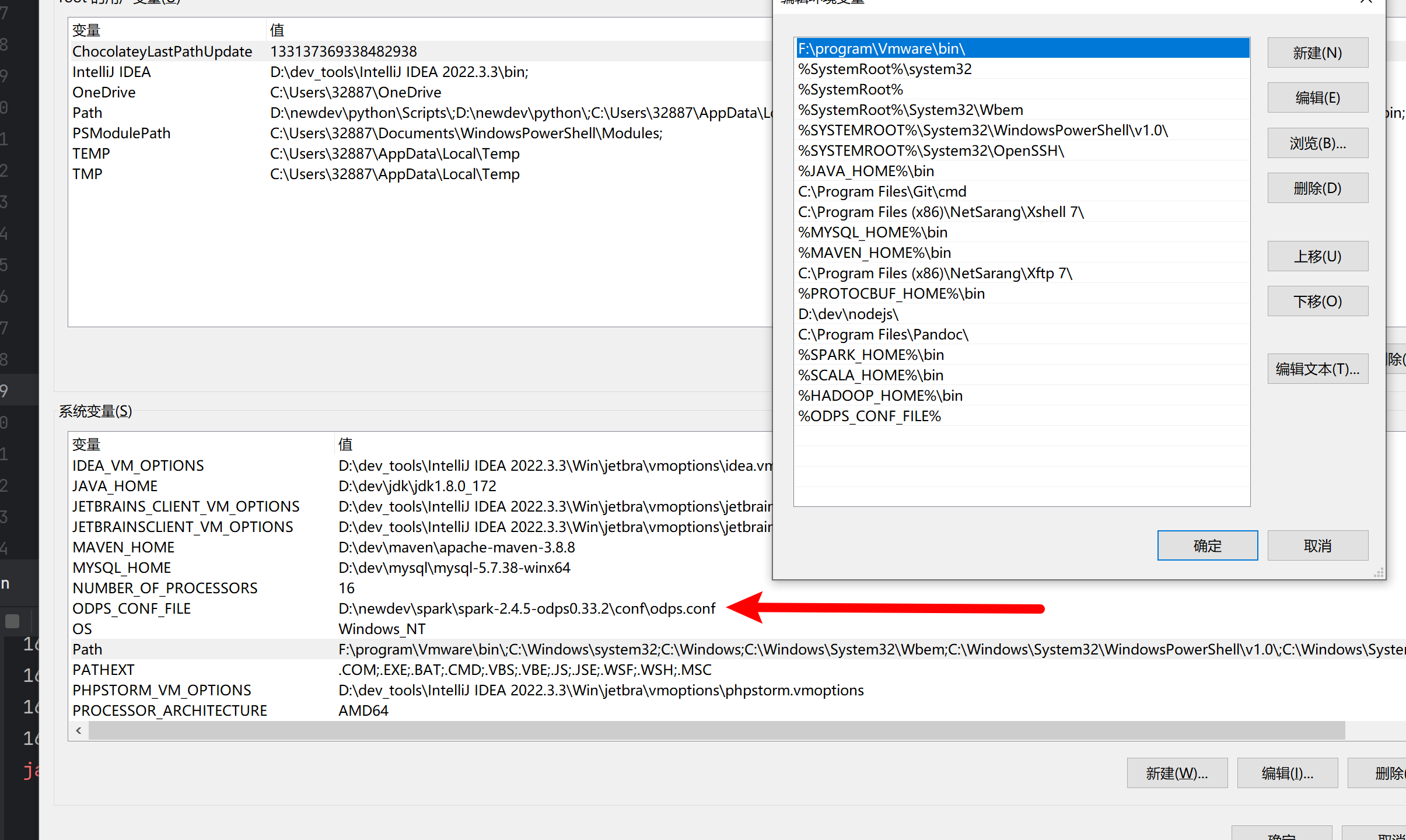
环境变量有配置这个文件地址。
展开
收起
1
条回答
 写回答
写回答
-

注意,如果使用spark 2.4.5及以上的版本,需要在代码中配置spark.sql.catalogImplementation=hive,不再需要在代码中配置spark.hadoop.odps.project.name,spark.hadoop.odps.access.id,spark.hadoop.odps.access.key,spark.hadoop.odps.end.point这几个参数
只要在代码的resources目录下(类加载器能加载的目录)创建一个名为odps.conf的文件,然后添加以下配置,注意在集群模式中需要将该文件删除:
odps.project.name=
odps.access.id=
odps.access.key=
odps.end.point= ,此回答整理自钉群“MaxCompute开发者社区2群”2024-01-31 07:52:20赞同 展开评论 打赏
问答地址:
开发者社区
>
大数据与机器学习
>
大数据计算 MaxCompute
>
问答
相关产品:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答

MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
热门讨论
热门文章
DataWorks从maxcomputer作业运维里面任务的logview点进去这个权限是在哪里开?
69
MaxCompute中执行SQL报错ODPS-0130071
23245
解析并获取大json,是否更推荐json_tuple()?
1174
请问大数据计算MaxCompute有主键这种说法么?
604
大数据计算MaxCompute中在生产环境中创建只能发布到运维中心,才能正式创建吗?
49
MaxCompute单元测试没有问题,通过本地运行却显示字段不存在,但是这个字段我是有的,有碰到吗?
2381
Maxcompute中如何处理expect equality expression (i.e., o
877
DataWorks中MaxCompute Writer不支持数据路由写入 这是什么意思?
25
MaxCompute上,1pb数据存储一个月大概多钱?
304
datawork实时同步有何区别?
22
展开全部
阿里巴巴飞天大数据平台MaxCompute(原名ODPS)全套攻略(持续更新20200109)
131415
阿里云开源离线同步工具DataX3.0介绍
102848
每个人都应该知道的25个大数据术语
42500
大数据环境下该如何优雅地设计数据分层
40227
盘古:阿里云飞天分布式存储系统设计深度解析
44354
odps是什么?
67570
美柚:最懂女性App背后的混合云架构与大数据服务
23672
MaxCompute执行作业慢的原因排查
24265
阿里云MaxCompute(大数据)公开数据集---带你玩转人工智能
24291
2017杭州云栖大会FAQ(持续更新中)
18449
展开全部





