
modelscope-funasr这几个参数是什么意思,如何调节?
modelscope-funasr这几个参数是什么意思,如何调节?batch_size_token=5000, batch_size_token_threshold_s=40, max_single_segment_time=6000。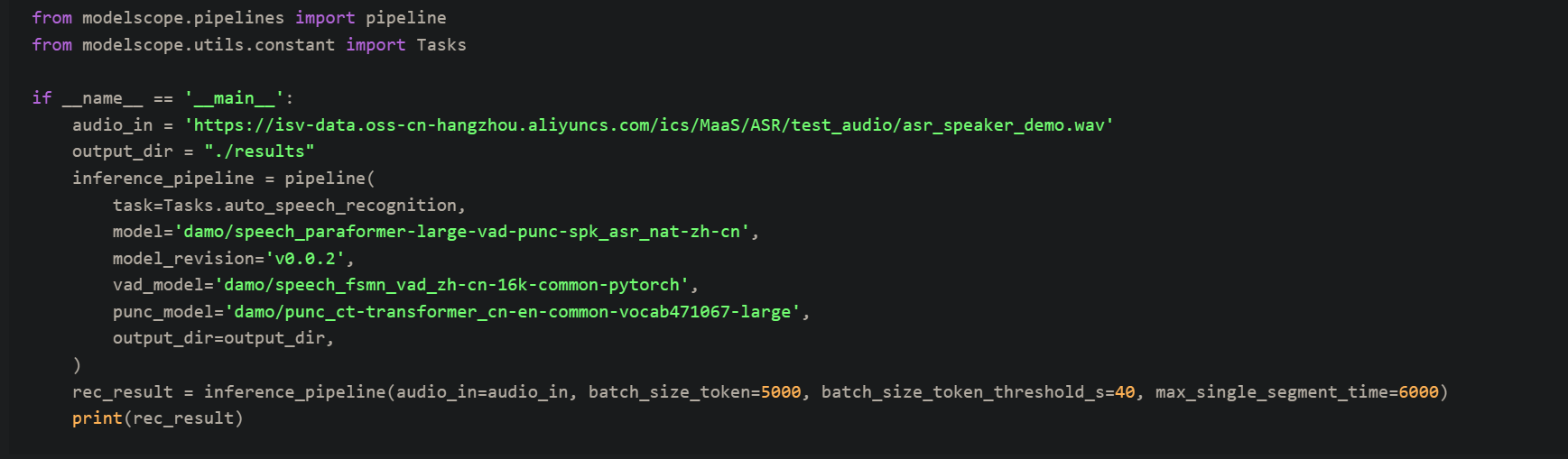
展开
收起
阿里云 AI 助理回答
在 modelscope-funasr 中,您提到的参数 batch_size_token、batch_size_token_threshold_s 和 max_single_segment_time 是与语音处理任务相关的配置参数。这些参数主要用于优化语音数据的分批处理和分割策略,以提高模型推理效率和性能。以下是每个参数的具体含义及调节建议:
1. batch_size_token=5000
含义:
- 该参数定义了单个批次中允许的最大 token 数量(即语音特征的帧数或文本长度)。
- 在语音处理任务中,token 通常对应于语音信号的时间帧或文本中的字符/子词单元。
调节方法:
- 增大值:如果您的硬件资源(如 GPU 内存)充足,可以适当增加
batch_size_token的值,从而提高批量处理能力,减少推理时间。 - 减小值:如果遇到内存不足或推理延迟过高的问题,可以降低该值,以减少单次处理的数据量。
- 注意事项:
- 过大的值可能导致显存溢出,尤其是在处理长语音时。
- 过小的值会降低批处理效率,增加推理时间。
2. batch_size_token_threshold_s=40
含义:
- 该参数表示当语音片段的时长超过指定秒数(40 秒)时,系统会强制将该片段拆分为多个批次进行处理。
- 它的作用是避免单个语音片段过长导致的内存占用过高或推理效率下降。
调节方法:
- 增大值:如果您需要处理较长的语音片段且硬件资源充足,可以适当增加该值,以减少不必要的分割操作。
- 减小值:如果硬件资源有限,或者需要更细粒度地控制语音片段的分割,可以降低该值。
- 注意事项:
- 如果设置得过大,可能会导致单个批次的计算压力过大,影响推理性能。
- 如果设置得过小,可能会导致过多的分割操作,增加额外的开销。
3. max_single_segment_time=6000
含义:
- 该参数定义了单个语音片段允许的最大时长(单位为毫秒,即 6000 毫秒 = 6 秒)。
- 当语音片段超过该时长时,系统会自动将其分割为多个片段进行处理。
调节方法:
- 增大值:如果需要处理较长的语音片段且硬件资源充足,可以适当增加该值,以减少分割次数。
- 减小值:如果硬件资源有限,或者需要更细粒度地控制语音片段的分割,可以降低该值。
- 注意事项:
- 过大的值可能导致单个片段的处理时间过长,影响实时性。
- 过小的值会导致过多的分割操作,增加额外的计算开销。
参数调节的综合建议
-
硬件资源评估:
- 根据您的硬件资源(如 GPU 显存大小、CPU 性能等),合理调整
batch_size_token和max_single_segment_time的值。 - 如果显存不足,优先降低
batch_size_token和max_single_segment_time。
- 根据您的硬件资源(如 GPU 显存大小、CPU 性能等),合理调整
-
任务需求匹配:
- 对于实时性要求较高的任务(如在线语音识别),建议将
max_single_segment_time设置为较小值(如 3000 毫秒),以确保低延迟。 - 对于离线任务(如批量语音处理),可以适当增大
batch_size_token和max_single_segment_time,以提高吞吐量。
- 对于实时性要求较高的任务(如在线语音识别),建议将
-
实验验证:
- 建议通过实验验证不同参数组合对推理性能的影响,找到最佳配置。
- 可以参考类似场景下的性能测试结果,结合实际任务需求进行调整。
示例配置
假设您正在使用 modelscope-funasr 处理一段较长的语音文件,并希望在保证推理效率的同时避免显存溢出,可以尝试以下配置:
batch_size_token = 4000 # 减少单批次的 token 数量,避免显存不足
batch_size_token_threshold_s = 30 # 将长语音片段分割为不超过 30 秒的批次
max_single_segment_time = 5000 # 单个语音片段最大时长为 5 秒
以上是对 modelscope-funasr 中相关参数的详细解释及调节建议。根据实际任务需求和硬件条件,您可以灵活调整这些参数以达到最佳性能。
有帮助
无帮助
AI 助理回答生成答案可能存在不准确,仅供参考
相关问答
相关文章
热门讨论
热门文章
展开全部
展开全部
还有其他疑问?
咨询AI助理