
2
条回答
 写回答
写回答
-

请参考此图片:
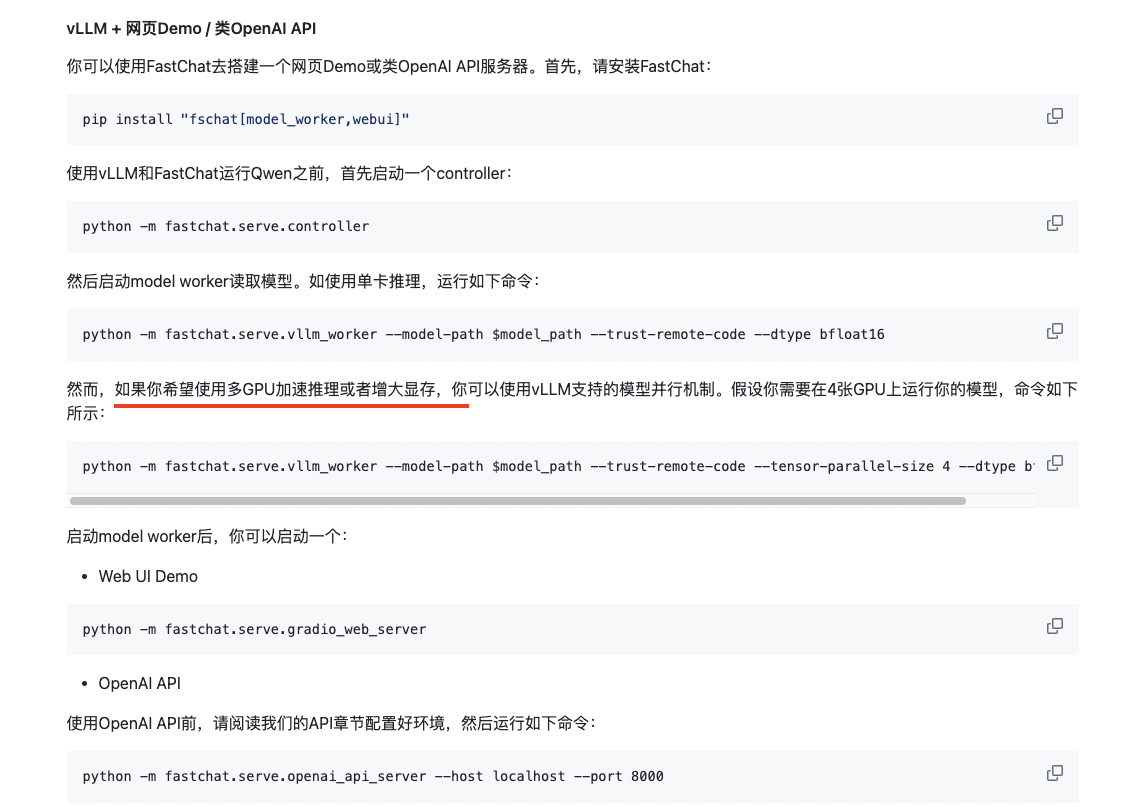 https://github.com/QwenLM/Qwen/blob/main/README_CN.md 此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”2023-12-18 22:01:48赞同 展开评论 打赏
https://github.com/QwenLM/Qwen/blob/main/README_CN.md 此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”2023-12-18 22:01:48赞同 展开评论 打赏 -

在ModelScope中配置使用72B参数量的模型并利用两块显卡进行训练,通常需要在代码中设置以下内容:
- 选择和加载模型:
根据ModelScope提供的API或库,选择和加载72B参数量的模型。 设置设备:
使用深度学习框架(如PyTorch或TensorFlow)的API来指定使用多块GPU。以下是一个使用PyTorch的示例:import torch # 设置CUDA设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 检查可用的GPU数量 num_gpus = torch.cuda.device_count() assert num_gpus >= 2, "至少需要两块GPU" # 将模型移动到第一块GPU上 model = model.to(device)数据并行化:
使用深度学习框架的并行化功能将模型和数据分布在多块GPU上。以下是一个使用PyTorch的数据并行化的示例:import torch.nn.parallel # 创建数据并行化容器 if num_gpus > 1: model = torch.nn.DataParallel(model) # 开始训练 for epoch in range(num_epochs): for batch in dataloader: inputs, targets = batch inputs, targets = inputs.to(device), targets.to(device) # 前向传播和反向传播 outputs = model(inputs) loss = criterion(outputs, targets) optimizer.zero_grad() loss.backward() optimizer.step()
以上代码只是一个基本的示例,实际的配置可能会根据您使用的模型、框架和任务的具体要求有所不同。在实际操作中,您需要参考ModelScope提供的文档和示例代码,以及深度学习框架的官方文档来完成具体的配置。
确保您的系统和硬件环境支持同时使用两块GPU,并且已经正确安装了所需的驱动程序和库。如果在配置过程中遇到问题,可以联系ModelScope的官方支持获取帮助。
2023-12-18 17:17:00赞同 展开评论 打赏 - 选择和加载模型:

相关问答
热门讨论
热门文章
ModelScope中,模型下载默认路径在哪个路径?
9440
服务器上onnxruntime-gpu 调用结束,如何释放显存
5112
com/action/joingroup?code=v1是什么意思
6922
我希望通过damo-YOLO训练1500*1500的图片
8531
请问在 ModelScope 上的模型断网使用报这个错误啥原因了?
2134
如何下载modelscope模型?
1255
在ModelScope中,请问模型下载到本地的具体方法?
1527
ModelScope中我尝试使用这个模型搭建了一个推理服务,然后报错了怎么办?
3405
streamlit 生成链接无法访问,gradio只生成内网,无法生成公网
2604
在ModelScope中,下载模型时的ssl问题怎么解决?!
363
展开全部




