
ModelScope中deepseek coder 6.7b量化为4bit 模型失败能测试下么?
ModelScope中,deepseek coder 6.7b量化为4bit 模型失败,能测试下是什么问题吗?其实最终目标是想实现deepseek 33b的部署,要不然不量化根本没办法部署。但是这个量化我试了很多种方法都不行。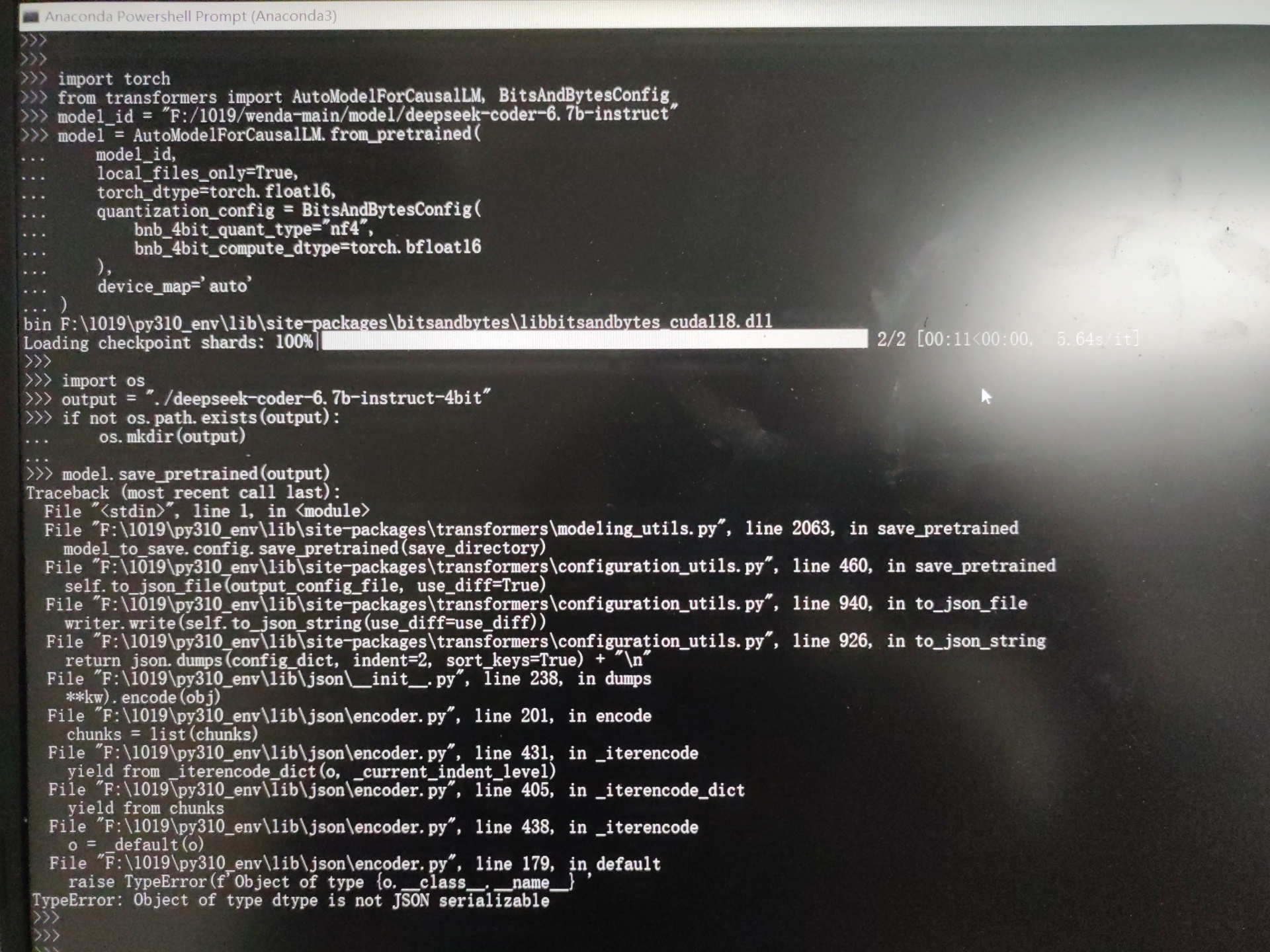 这是其中一种方法的量化代码。
这是其中一种方法的量化代码。
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
量化模型的过程可能会遇到各种困难和挑战,包括精度损失、不稳定性和内存溢出等。以下是一些建议,有助于您解决 deepseek coder 6.7b 量化为 4 bit 的问题:
- 更改超参数:尝试更改量化算法的超参数,以改善模型性能。这些参数可能会影响模型的精度和速度,所以要特别注意。
- 尝试不同的量化算法:使用其他量化算法,如 FPQuantizer、Post-training Quantization 等。每种算法都有其优点和缺点,因此请根据您的需求选择最合适的算法。
- 对模型进行正则化:量化模型可能会遇到过拟合问题。通过增加正则化,可以减小过拟合的可能性。
- 调整模型架构:重新设计模型架构以减轻量化的影响。例如,减少层数或改变激活函数,可以帮助模型更容易量化。
- 避免过度拟合:确保您有足够多的训练数据,以防止过度拟合。这可以通过增加样本数量或调整学习率来实现。
- 使用更多的计算资源:为了加快训练速度,可以使用更多的 GPU 或更大的集群来加速模型的训练和验证。
2023-11-29 13:24:25赞同 展开评论 -
对于DeepSeek Coder 6.7b模型的4位量化,首先需要明确的是,4位量化意味着我们将模型中的权重和激活值都量化为4位。这可能会导致模型的性能下降,因为信息损失了。因此,我们需要在量化过程中尽可能地减少信息损失。
以下是一些可能的解决方案:
选择合适的量化方法:有许多量化方法可以选择,如静态量化、动态量化等。不同的量化方法可能会有不同的效果。你可以尝试使用不同的量化方法,看哪种方法对你的模型最有效。
调整量化参数:量化方法通常有一些参数可以调整,如量化步长、量化范围等。你可以尝试调整这些参数,看是否能提高量化效果。
使用更复杂的量化方法:如果你的模型对量化非常敏感,你可能需要使用更复杂的量化方法,如量化感知训练(Quantization Aware Training)。这种方法可以在训练过程中学习量化的影响,从而减少量化带来的性能损失。
使用预训练的量化模型:有些预训练的量化模型可能已经经过了优化,可以直接用于部署。你可以尝试使用这些模型,看是否能满足你的需求。
对于DeepSeek 33b的部署,可能需要更多的硬件资源。你需要确保你的硬件设备支持33位的运算,并且有足够的内存来存储模型。此外,你可能还需要对模型进行一些优化,以减少模型的大小和计算复杂度。
2023-11-29 12:01:17赞同 展开评论 -
北京阿里云ACE会长
量化模型,你需要了解一些基本知识。量化是一种降低模型精度的技术,可以减少模型的大小和计算需求。在 ModelScope 中,你可以使用 swift 量化脚本来量化模型。
为了量化 DeepSeek Coder 6.7B 模型为 4bit,请按照以下步骤操作:- 确保你已经安装了必要的依赖项。在 ModelScope 中,量化依赖于 Swift AI 库。请确保你已经正确安装并配置了该库。
- 运行 swift 量化脚本。你应该已经有一个名为 quantize.swift 的脚本。运行此脚本时,请确保传递正确的模型 ID 和量化精度(在这种情况下为 4bit)。例如:
swift quantize.swift --model_id "/data/sft models/deepseek_coder_6.7b models/model 1 0 7/deepseek_coder_6.7b-chat-int4/v0-20231112-142116/checkpoint-60/model.pt" --bit_width 4
CopyCopy- 检查量化后的模型是否成功生成。在执行量化脚本后,你应该会在指定的输出目录中看到一个名为 quantized_model.pt 的文件。这是量化后的模型。
- 如果你遇到量化失败的问题,请检查以下几点:
- 确保你有足够的权限在 ModelScope 中执行量化脚本。
- 检查模型 ID 是否正确。
- 检查 quantize.swift 脚本中的模型加载部分,确保模型正确加载。
- 检查量化过程中的计算是否正确。你可能需要检查算术运算、张量形状和其他相关细节。
关于部署 DeepSeek 33B 模型,量化是关键。如果你无法成功量化模型,你可能无法在目标设备上部署它。
2023-11-22 10:28:31赞同 展开评论
