
DataWorks数据开发emr hive节点报同样的错误,没有开启ranger之类的权限?
DataWorks数据开发emr hive节点报同样的错误,没有开启ranger之类的权限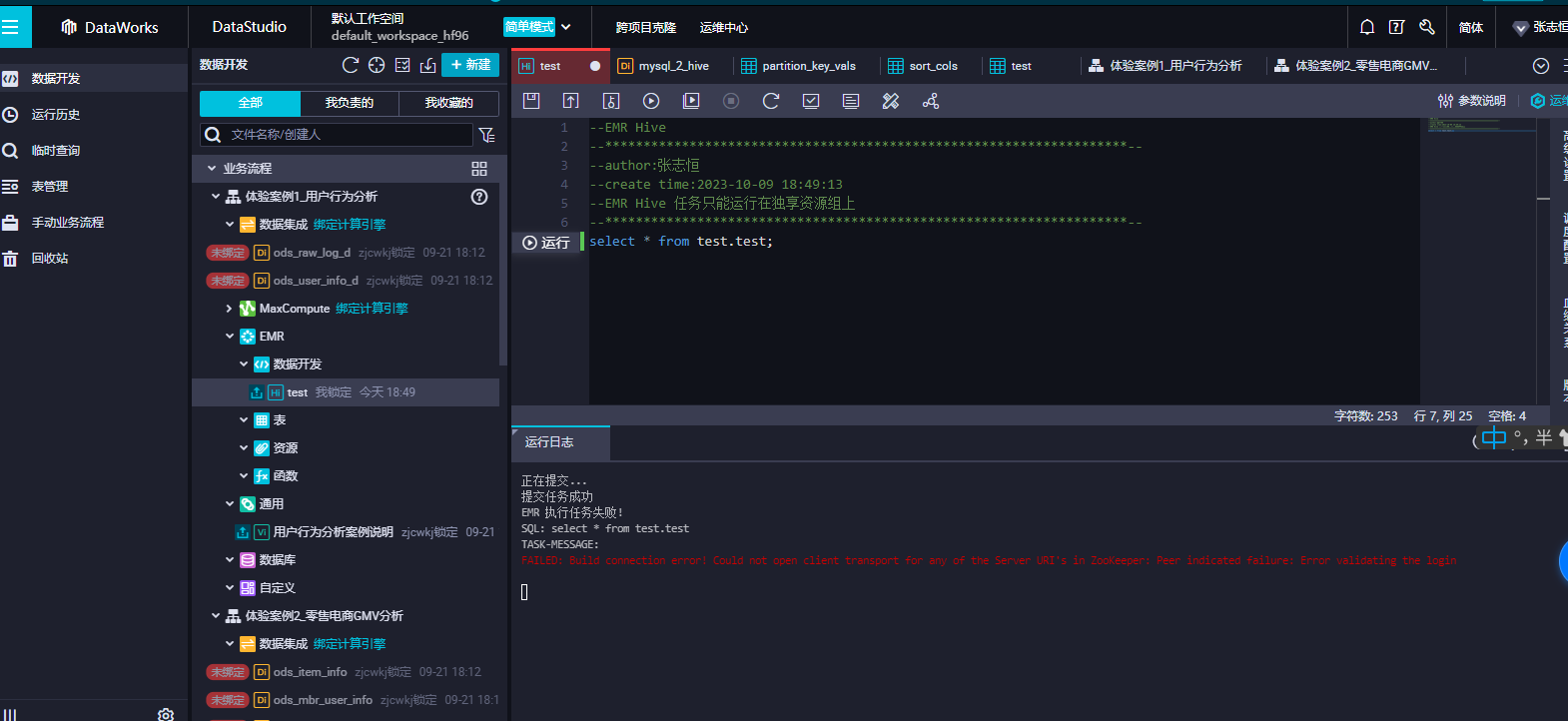
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
月移花影,暗香浮动
如果在DataWorks中遇到EMR Hive节点报错,即使没有开启Ranger之类的权限,也可能需要采取以下处理步骤:
1、检查错误信息:首先查看报错信息,以便更好地了解错误的原因和具体问题所在。错误信息通常会提供关键的提示和指导,以便您确定问题的根本原因。
2、检查数据源连接:确保在DataWorks中正确配置了与EMR Hive节点的数据源连接。检查连接参数是否正确,包括Hive服务的主节点地址、端口、数据库名称、用户名和密码等。确保数据源连接可以成功建立,并且可以访问到所需要的数据表。
3、检查数据表权限:即使没有开启Ranger之类的权限,也有可能导致访问数据表时的错误。确保当前用户有足够的权限来访问所需要的数据表。您可以尝试使用具有更高权限的用户登录DataWorks,以验证是否能够解决问题。
4、检查数据表结构:在访问数据表之前,确保了解表的结构和字段含义。查看表中是否存在特殊字符、数据类型是否正确,并了解是否存在必填字段。通过了解表结构,可以更好地处理和过滤数据,以避免潜在的错误。
5、检查代码逻辑:如果您在DataWorks中编写了自定义的SQL或脚本,检查代码逻辑是否正确。确保查询语句没有语法错误、表名和字段名没有拼写错误,并且逻辑上符合您的预期。
6、清除缓存:在某些情况下,清除DataWorks缓存并重新加载页面可能会解决一些未知的问题。尝试清除缓存后,重新启动DataWorks并再次尝试访问报错的数据表。总之,针对DataWorks EMR Hive节点报错的问题,首先要仔细检查错误信息,然后从数据源连接、数据表权限、表结构、代码逻辑等多个方面逐一排查问题所在。
2023-10-16 16:14:06赞同 展开评论 -
这个报错 基本是权限配置问题 看下emr是否有开启ldap,在dataworks绑定引擎的时候选择的访问账号是否有配置映射对应有权限的ldap账号
"DATAWORKS_SESSION_DISABLE": false 这个在高级设置中关闭一下 可以看到完整的日志,1. mongo reader增量同步:
实时场景:增量的标志是mongodb里的一个字段为createtime,每次导入的数据范围是业务时间00:00到业务时间23:59- {createtime :{$gte:ISODate("unknownT00:00:00.000+0800"),$lte:ISODate("unknownT23:59:59.999+0800")}}
注意: - 1.不支持时间戳
- 2.query 可结合调度参数同步使用
- 3.详情请参见MongoDB查询语法。,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
2023-10-15 23:13:25赞同 展开评论 - {createtime :{$gte:ISODate("unknownT00:00:00.000+0800"),$lte:ISODate("unknownT23:59:59.999+0800")}}
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
如果在 DataWorks 中使用 EMR Hive 节点进行数据开发时,出现“没有开启 Ranger 等权限”的错误,可能是因为 EMR 集群没有开启 Ranger 等权限控制功能,或者在 DataWorks 中配置的 Hive 节点没有获取到相应的权限。
为了解决这个问题,你可以尝试以下方法:- 确保 EMR 集群开启了 Ranger 等权限控制功能。如果没有开启,需要在 EMR 控制台中进行配置。
- 确保在 DataWorks 中配置的 Hive 节点获取到了相应的权限。可以在 DataWorks 控制台中查看 Hive 节点的权限信息,如果权限不足,需要进行相应的配置。
- 如果 EMR 集群开启了 Ranger 等权限控制功能,但是 DataWorks 中配置的 Hive 节点仍然无法获取到权限,可能是因为 DataWorks 的配置文件中没有正确设置 Ranger 等权限控制相关的参数。需要检查 DataWorks 的配置文件,确保设置正确。
2023-10-15 21:37:00赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。