
DataWorks中一个单表查询都要10秒钟,反正我们这边的接口全用不了了?
DataWorks中一个单表查询都要10秒钟,反正我们这边的接口全用不了了?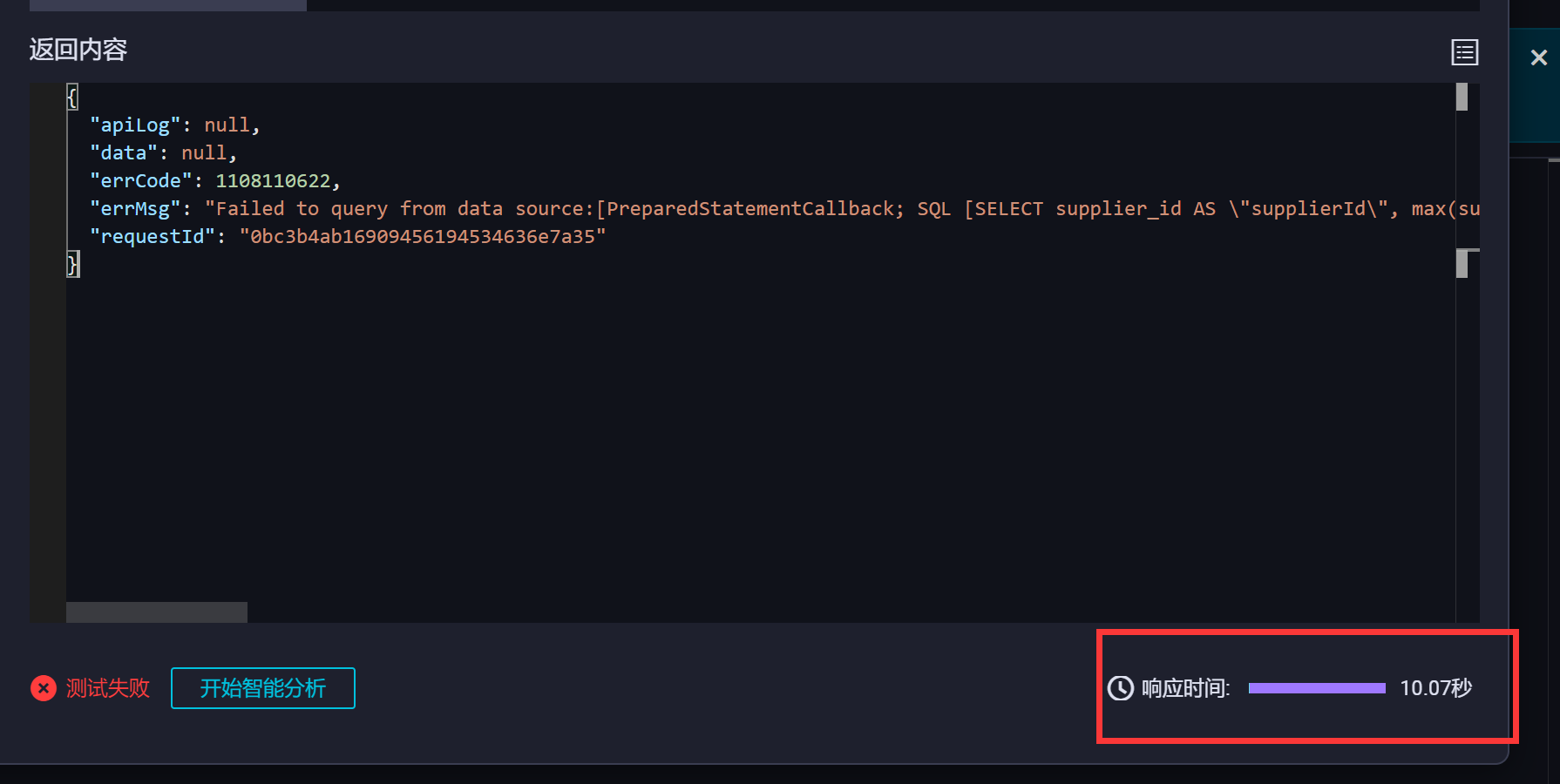
原句很简单的,就是sum的单表查询,平时都很快,今天所有的api接口全部超时,不是这一个,是所有api接口
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
如果DataWorks中单表查询需要10秒钟,很可能存在以下原因:
数据量过大。表中数据量特别大,会影响查询效率。
where条件不当。where条件定义不当,导致全表扫描。
缺少索引。查询中用到的条件字段没有建立索引。
网络延迟。DataWorks和数据源(如MySQL)之间的网络连接存在延迟。
硬件配置问题。DataWorks和数据库的服务器配置低,无法支撑大量的查询压力。
SQL优化不足。SQL语句本身存在缺陷,无法高效运行。
系统问题。DataWorks可能存在某些系统优化不足的地方。
针对上述可能的原因,可以采取的优化方案:
调整where条件,减少全表扫描;
在查询字段上建立合适的索引,在SQL中利用索引;
优化服务器配置,调高CPU、内存配置;
优化数据传输,尽量降低网络延迟;
调整SQL语句,采用最优的JOIN查询方式;
升级DataWorks版本,修正系统问题。
2023-08-09 20:54:38赞同 展开评论 -
集群炸了?原句在数据库直接执行耗时多久? 具体是哪个地域 哪个数据源类型哈?DataStudio数据开发查询就很慢
问了一下 holo加速是共享的,所以如果有人占用了太多的资源,就导致资源挤兑,如果您有holo 建议是自己创建holo外表 建holo数据源 生成api,skynet_accessid is null,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-08-08 20:48:04赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。