
DataWorks中hello oss 自增 文件, 这里的同步格式要怎么填写?
DataWorks中hello oss 自增 文件, 这里的同步格式要怎么填写?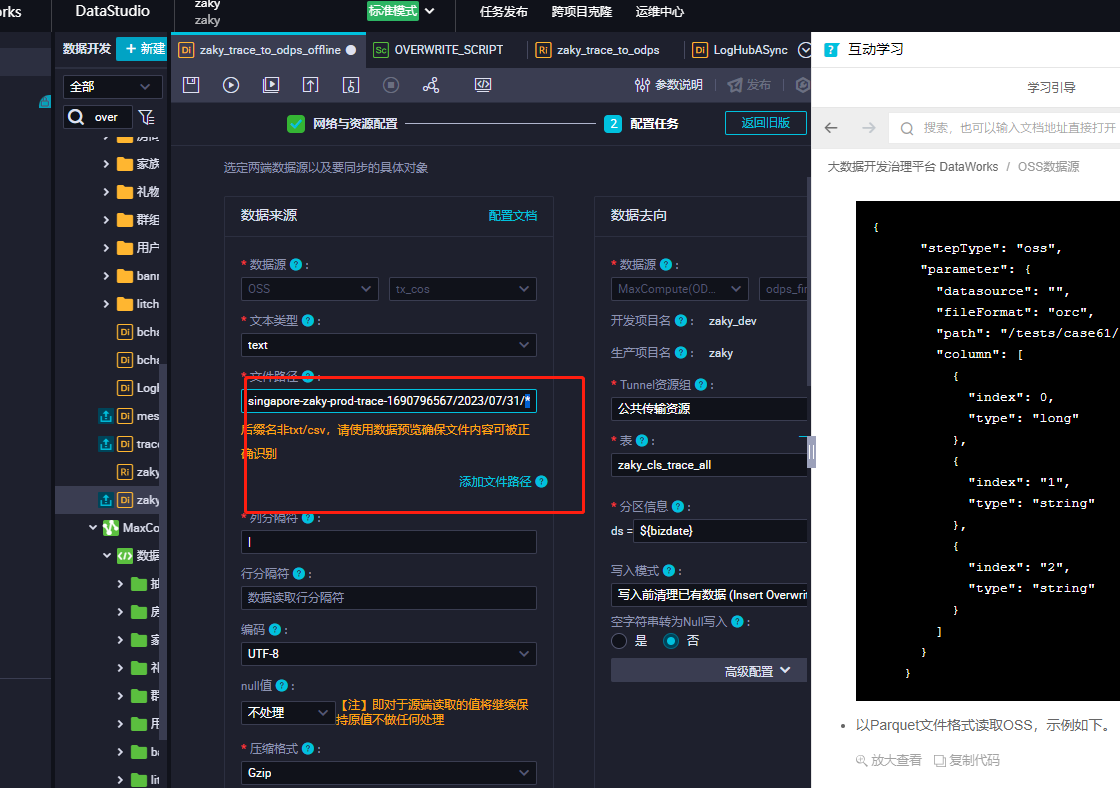
文件路径 --> /yyyy/mm/dd/{文件名:yyyymmddhhmiss-随机码}
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
可以根据您的需求选择适当的同步格式。同步格式决定了源数据和目标数据的转换方式。以下是一些常见的同步格式选项:
文本格式(Text):将源数据以文本形式同步到目标位置。这是最常见的同步格式,适用于文本文件和非结构化数据。
CSV格式:将源数据同步为逗号分隔的值(CSV)格式。CSV格式适用于结构化数据,每个字段使用逗号进行分隔。
JSON格式:将源数据同步为JavaScript对象表示法(JSON)格式。JSON格式适用于半结构化和非结构化数据。
Avro格式:将源数据同步为Apache Avro格式。Avro是一种二进制数据序列化格式,适用于高性能和复杂数据结构。
Parquet格式:将源数据同步为Apache Parquet格式。Parquet是一种列式存储格式,适用于大规模数据分析和查询。
根据您的具体需求和源数据的特点,选择适当的同步格式。在DataWorks中,您可以在"hello oss"节点的同步配置中找到同步格式选项,并选择适合您的数据类型的格式。
2023-08-09 23:01:07赞同 展开评论 -


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。