
DataWorks中pyodps3设置了输出参数,如果我想把这个参数传给赋值节点,这个该怎么去调用?
DataWorks中pyodps3设置了输出参数,如果我想把这个参数传给赋值节点,这个该怎么去调用呢?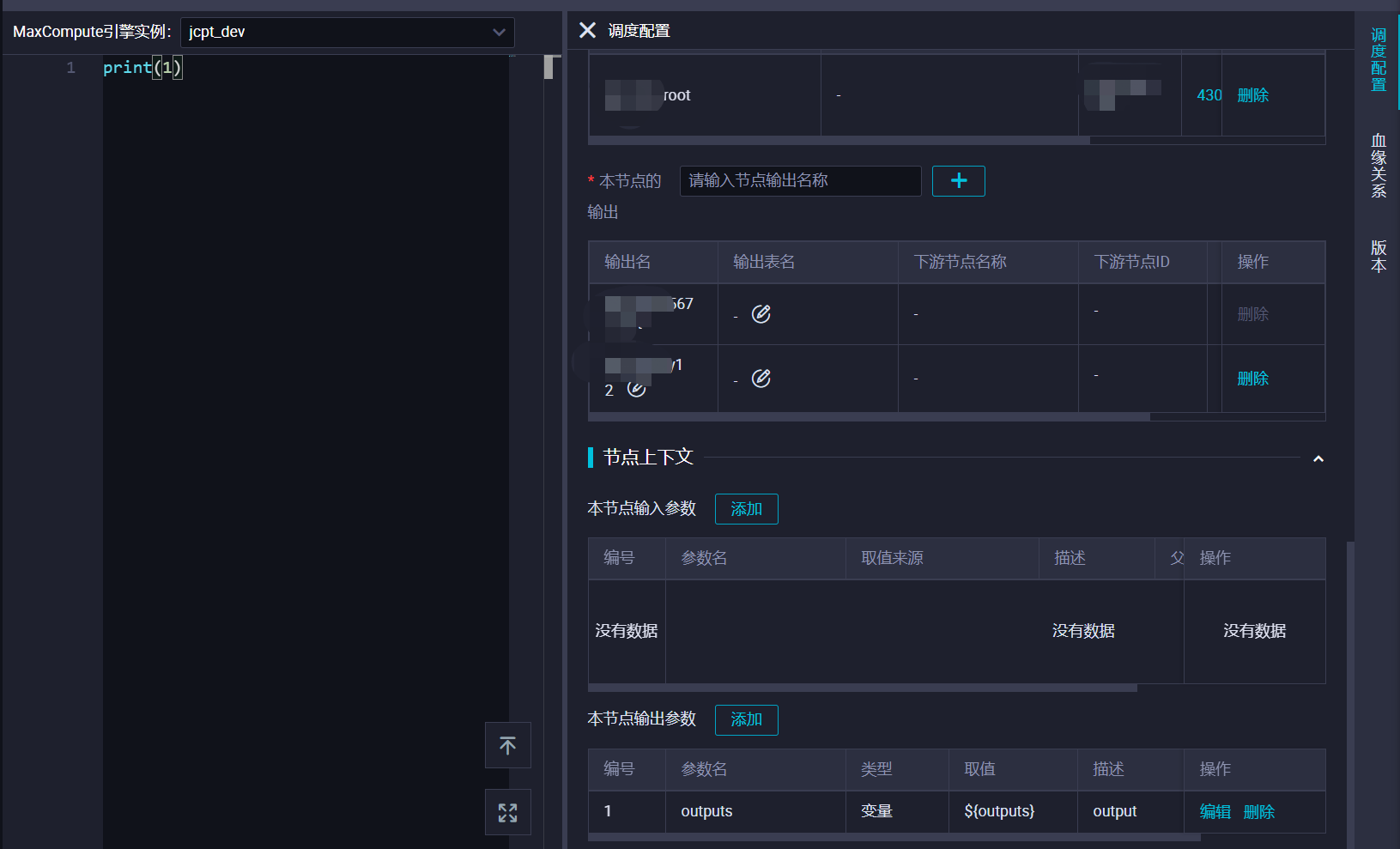
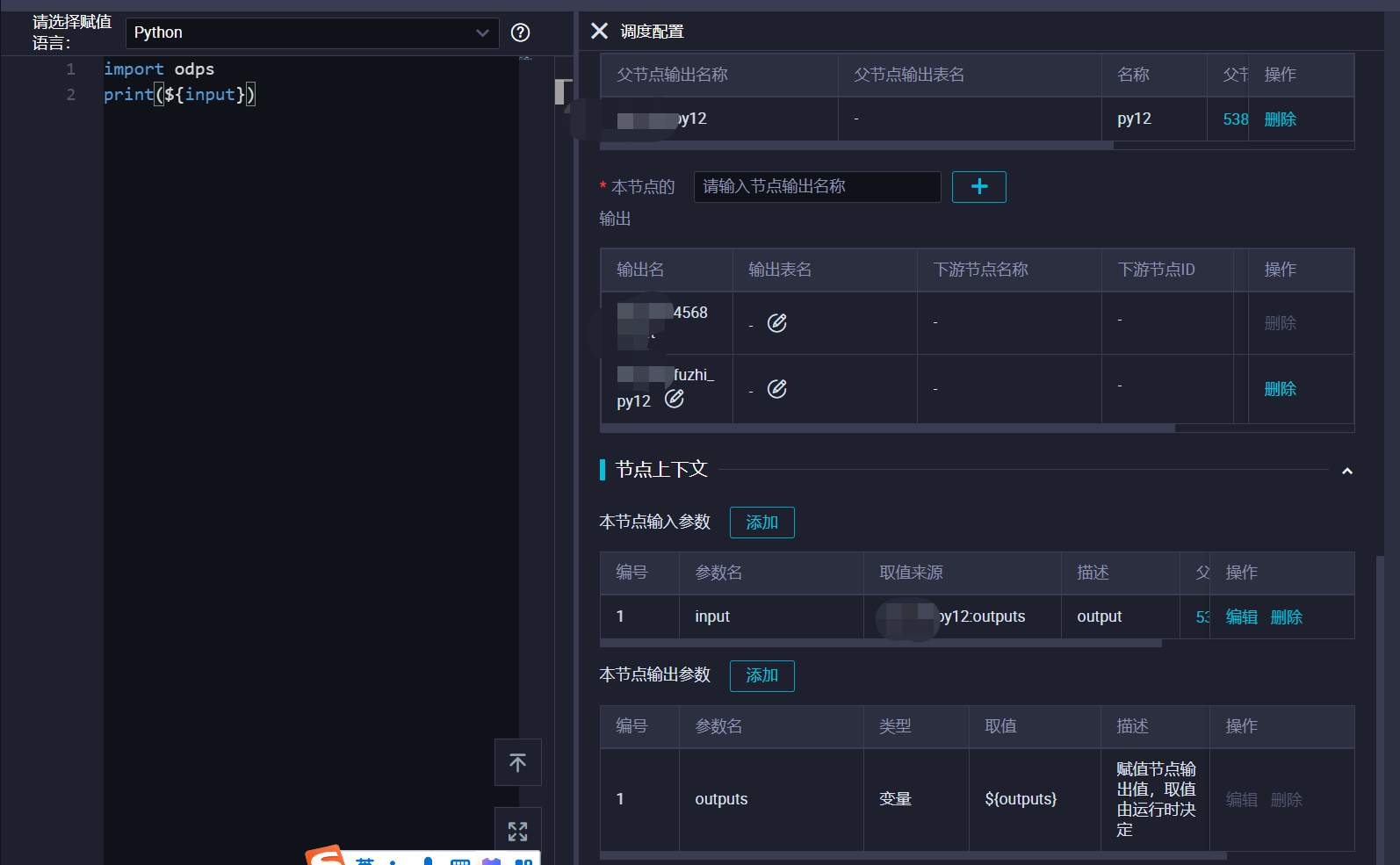
赋值节点可以接受上游节点的参数输出吗?文档无法解决当前问题
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
DataWorks中如果Python UDF有输出参数,并需要把这个参数传递给下游节点或赋值节点使用,可以通过以下方式调用:
在Python代码中使用op.set_outputs()函数定义输出参数:
python
Copy
import pyodps引入op
from pyodps.df import DataFrame
def my_udf(df):
处理逻辑
result = ...
定义输出参数res
op = pyodps.task.get_sample_python_operator()
op.set_outputs(res=result)if name == 'main':
my_udf()
在DataWorks任务配置中,将Python节点的输出链接到下游节点:
下游节点可以使用${python.res}引用Python输出参数res2023-08-10 17:06:36赞同 展开评论 -
可以看下使用者部分 https://help.aliyun.com/zh/dataworks/user-guide/configure-input-and-output-parameters?spm=a2c4g.11186623.0.i1#3e62dc7026onl:~:text=%E6%97%A0-,%E4%B8%8B%E6%B8%B8,-%E8%8A%82%E7%82%B9%E4%BD%BF%E7%94%A8%E8%BE%93%E5%85%A5 不过为啥是传递给赋值节点,赋值节点有节点上下文 输入参数 是哪里阻塞了吗,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
2023-08-07 21:08:42赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。