
如何实现dataworks分支节点的空跑属性?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 DataWorks 中,分支节点的空跑属性是指当分支节点的输入依赖没有发生变化时,该分支节点将不执行任何操作,直接将已有的输出结果传递给下游节点。这种空跑属性可以节省计算资源,提高数据集成或计算任务的执行效率。
要实现分支节点的空跑属性,可以按照以下步骤进行操作:
在 DataWorks 数据开发页面中,打开您要设置空跑属性的工作流,并找到需要设置空跑属性的分支节点。
在分支节点的属性面板中,找到 "高级属性" 选项卡,并将 "空跑属性" 设置为 "开启"。
设置完空跑属性后,需要重新发布该工作流才能生效。在重新发布工作流之前,您可以点击 "编排" 页面右上角的 "检查" 按钮,检查工作流的依赖关系和节点设置是否正确。
在DataWorks中,分支节点(Branch Node)是一种特殊类型的节点,用于根据条件选择不同的分支路径。要实现分支节点的空跑属性,即使条件为false时,也能让分支节点继续执行而无需中断流程,可以采取以下步骤:
创建一个决策节点(Decision Node):在分支节点前添加一个决策节点。决策节点用于设置条件,根据条件的结果来决定是否执行分支节点。
设置决策节点的条件:在决策节点的配置中,设置条件表达式以判断是否执行分支节点。如果希望分支节点始终执行,无论条件为true还是false,可以设置一个恒为真(例如1=1)的条件表达式。
连接决策节点和分支节点:将决策节点的“否”连接到分支节点。这样,无论条件是true还是false,决策节点都会继续执行,并将流程传递到分支节点,从而实现分支节点的空跑属性。
*考虑到某些分支节点的下游有两个节点,通常只有一个节点被选中,另外一个节点会被置为空跑,同时该空跑属性会不断向下传导至其子节点的情况,DataWorks新增了上游节点空跑属性不进行跨周期传导的调度特性。但如果下游分支节点中,某一个分支节点依赖自身的上一周期,同时上一周期节点未被选中,则该节点会永远空跑。例如,节点(我是左边)被置为空跑,则其下游节点也会被置为空跑。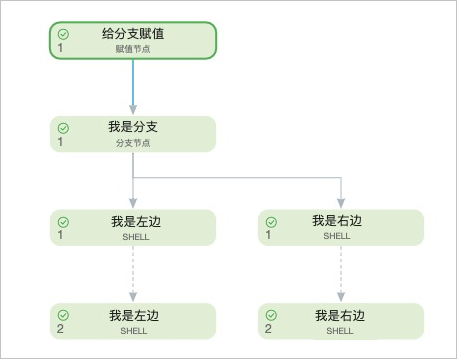
为了满足下一周期的节点是否运行由下一周期的分支节点决定,而不是上一周期的空跑属性来决定的需求,您可以进行以下操作:单击节点编辑页面右侧的调度配置。在时间属性区域,选中依赖上一周期。单击高级配置。选中上游节点空跑属性不进行跨周期传导,该任务将不被上一周期分支节点的空跑属性影响。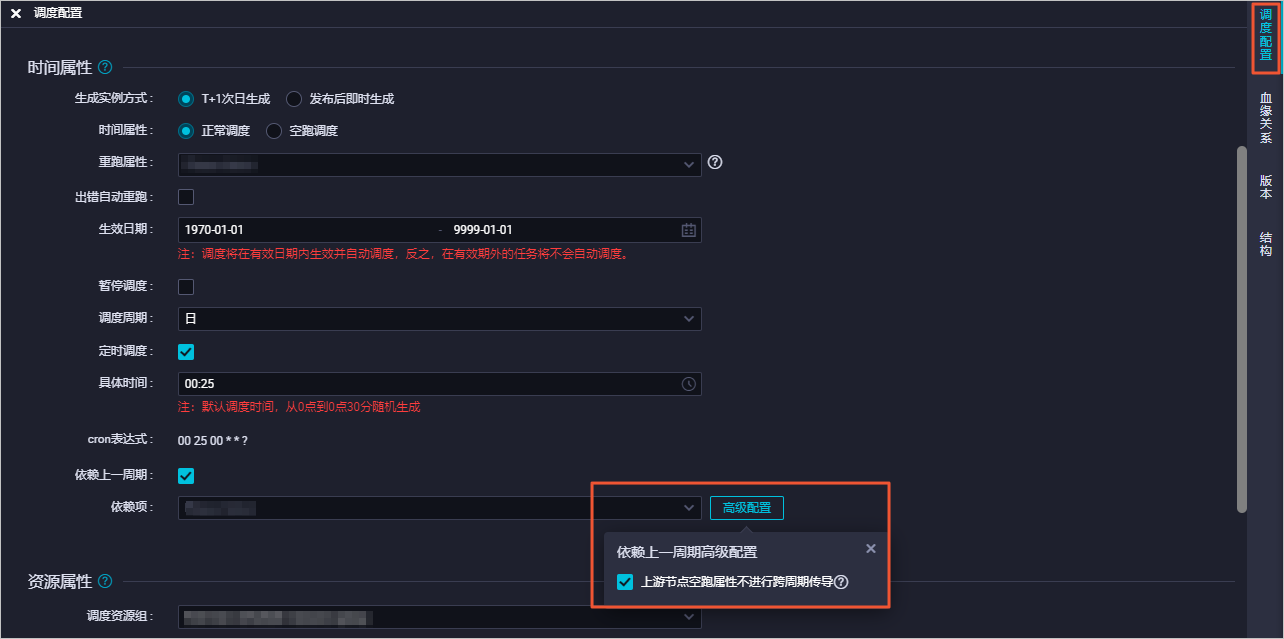
说明 普通节点上一周期的空跑属性不适用该选项,仅分支节点未被选中导致的空跑属性会被影响。
https://help.aliyun.com/document_detail/137551.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


