
DataWorks中转pandas之后 乱码 并且多了个b 这块是咋回事呀?
DataWorks中转pandas之后 乱码 并且多了个b 这块是咋回事呀?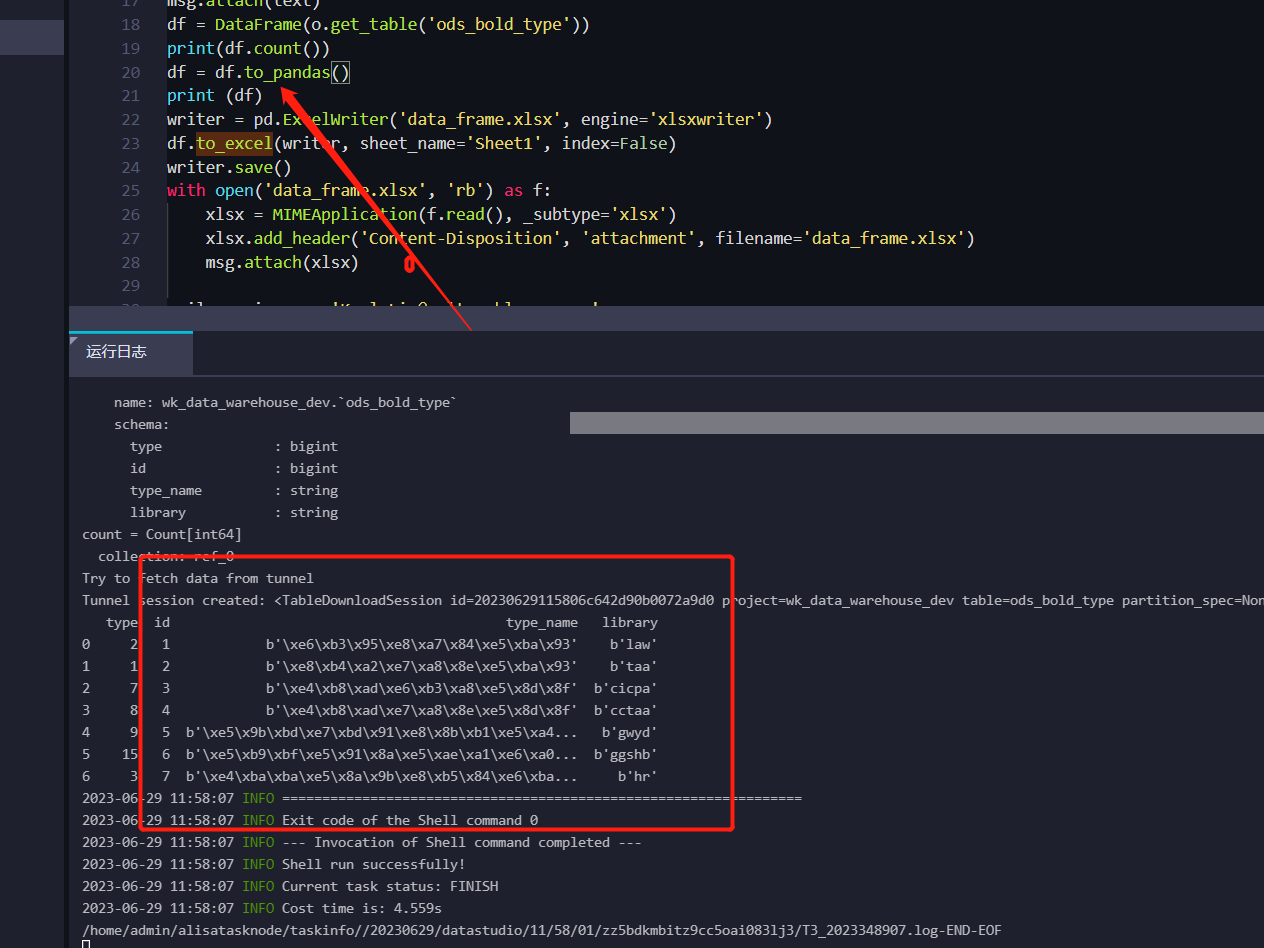
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
当在 DataWorks 中使用 Pandas 进行数据转换时,出现乱码和多个 'b' 字符的情况可能是由于字符编码的不一致导致的。以下是一些可能的原因和解决方法:
字符编码问题:请确认源数据和目标数据的字符编码是否一致。如果源数据是 UTF-8 编码,而目标数据使用其他编码(如 GBK),则可能会导致乱码。尝试将源数据和目标数据的字符编码设置为一致的值。
数据类型转换:在将数据从 DataWorks 转换到 Pandas 过程中,确保将数据正确地转换为 Pandas 支持的数据类型。如果数据类型不匹配,可能会导致异常字符或乱码的出现。
编码转换:如果数据已经被错误地编码,可以尝试使用 Python 的
decode方法进行编码转换。例如,对于字符串s,可以使用s.decode('utf-8')将其从 UTF-8 解码为 Unicode。特殊字符处理:某些特殊字符(如非 ASCII 字符)可能无法被正确显示。你可以尝试使用合适的字符编码或字符集来正确处理这些特殊字符。
确保源数据没有变化:检查在数据传输过程中是否有任何对数据进行修改或处理的操作,这可能会导致数据内容发生变化,进而导致乱码或额外的字符出现。
如果以上方法无法解决问题,建议提供更具体的情况和示例数据,以便更准确地分析和解决问题。你也可以参考 Pandas 的官方文档或社区进行进一步的研究和咨询。
2023-07-31 21:43:28赞同 展开评论 -
北京阿里云ACE会长
在DataWorks中将数据转换为Pandas DataFrame时出现乱码和多了个'b'的问题,可能是由于数据字符集的不一致导致的。
具体来说,如果源数据使用的字符集与Pandas默认字符集不一致,就会导致数据转换时出现乱码和多余字符的情况。在这种情况下,可以尝试通过以下方法来解决问题:
指定字符集:在将数据转换为Pandas DataFrame时,可以通过指定字符集的方式来解决乱码问题。例如,可以使用Python的chardet库来自动检测源数据的字符集,并将其转换为Pandas DataFrame所支持的字符集。
转换字符集:如果源数据的字符集与Pandas DataFrame不一致,也可以尝试将源数据的字符集转换为Pandas DataFrame所支持的字符集,以避免乱码和多余字符的问题。例如,可以使用Python的iconv库来进行字符集转换。
2023-07-31 21:27:14赞同 展开评论 -
全栈JAVA领域创作者
您好,这个问题可能是由于文件编码格式不正确导致的。您可以尝试使用记事本打开CSV文件,另存为设置编码为utf-8,然后重新读取文件设置encoding=’utf-8’就好了。此外,如果您使用的是DataWorks中的pandas转换工具,可能需要在转换时指定编码格式。
2023-07-03 07:46:06赞同 展开评论 -
当在使用DataWorks转换数据为Pandas的DataFrame时,遇到乱码和多了个"b"的问题,可能是由于数据的编码格式不匹配导致的。
Pandas默认使用UTF-8编码进行读取数据,如果数据的编码格式与UTF-8不一致,就会出现乱码。解决方法是在read_csv函数中指定正确的编码格式,例如使用encoding='gb18030'来读取gb18030编码的数据。
至于多了个"b"的问题,可能是因为数据在读取时被当作字节字符串(bytes)处理,而不是普通字符串。这通常发生在数据源中存在字节字符串时,Pandas会以字节字符串的形式读取数据。可以尝试在读取数据后使用.str.decode('utf-8')方法将字节字符串转换为普通字符串。
以下是一个示例代码,展示如何在读取数据时解决乱码和多了个"b"的问题:
import pandas as pd df = pd.read_csv('your_data.csv', encoding='gb18030') df['column_name'] = df['column_name'].str.decode('utf-8') # 进行其他数据处理操作如果问题仍然存在,可能是由于其他原因引起的。
2023-07-02 19:34:51赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。