
请教一下各位老师。我使用VGG16 提取图片特征码。 features = model.predict(x)。得到的算一个4维向量(矩阵)。 存储到elascsearch中保存出错。 BadRequestError(400, 'mapper_parsing_exception', 'Failed to parse object: expecting token of type [VALUE_NUMBER] but found [START_ARRAY]'),根据错误提示。我将矩阵降维
BadRequestError(400, 'mapper_parsing_exception', 'Failed to parse object: expecting token of type [VALUE_NUMBER] but found [START_ARRAY]'),根据错误提示。我将矩阵降维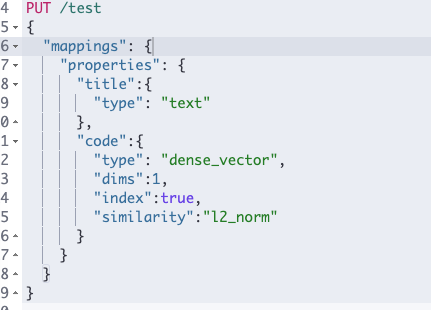 features = model.predict(x)features = features.flatten()elasticsearch.BadRequestError: BadRequestError(400, 'mapper_parsing_exception', 'failed to parse')
features = model.predict(x)features = features.flatten()elasticsearch.BadRequestError: BadRequestError(400, 'mapper_parsing_exception', 'failed to parse')
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,您在使用VGG16模型提取图片特征码后,尝试将特征向量存储到Elasticsearch中时遇到了mapper_parsing_exception错误。以下是针对该问题的详细分析和解决方案:
错误信息解析
错误提示表明,Elasticsearch在解析数据时,期望的是一个数值类型(VALUE_NUMBER),但实际接收到的是数组类型(START_ARRAY)。这说明Elasticsearch的字段映射与您存储的数据格式不匹配。
原因推测
model.predict(x)提取的特征是一个4维张量(矩阵),即使经过flatten()操作,它仍然是一个一维数组([float, float, ...])。在存储数据之前,确保目标索引的字段映射已正确配置为支持数组类型。例如:
PUT /your_index_name
{
"mappings": {
"properties": {
"features": {
"type": "dense_vector",
"dims": 4096 // 根据VGG16输出的特征维度设置
}
}
}
}
dense_vector类型来存储高维特征向量。dims参数需要与VGG16模型输出的特征维度一致(通常为4096)。在存储数据时,确保特征向量被转换为符合Elasticsearch要求的格式。例如:
import numpy as np
# 假设 features 是 VGG16 提取的特征向量
features = model.predict(x)
features = features.flatten().tolist() # 转换为 Python 列表
# 构造存储数据
document = {
"features": features
}
# 存储到 Elasticsearch
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts=["http://localhost:9200"])
es.index(index="your_index_name", body=document)
flatten()将多维数组展平为一维数组。tolist()将NumPy数组转换为Python列表,以确保兼容性。存储完成后,可以通过以下命令验证数据是否成功写入:
GET /your_index_name/_search
{
"query": {
"match_all": {}
}
}
字段映射不可更改
如果目标索引已经存在且字段映射不符合要求,则需要重新创建索引并迁移数据。Elasticsearch不允许直接修改现有字段的映射。
性能优化
对于大规模特征向量存储,建议启用dense_vector的近似最近邻搜索功能(如HNSW算法)以提高检索效率。
数据一致性
确保所有存储的特征向量维度一致,否则会导致解析错误。
通过上述步骤,您可以解决mapper_parsing_exception错误,并成功将VGG16提取的图片特征存储到Elasticsearch中。核心在于正确配置字段映射(dense_vector类型)以及调整数据格式以满足Elasticsearch的要求。
如果您仍有疑问,请提供更多上下文信息(如索引映射、存储代码等),以便进一步协助您解决问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。

