
Flink中维度join 这个值设置为 0 , 意味着维度join 这个状态会一直增大?,那我这个结
Flink中维度join 这个值设置为 0 , 意味着维度join 这个状态会一直增大?,那我这个结果表即是维表,有是事实表,这个值需要修改吗?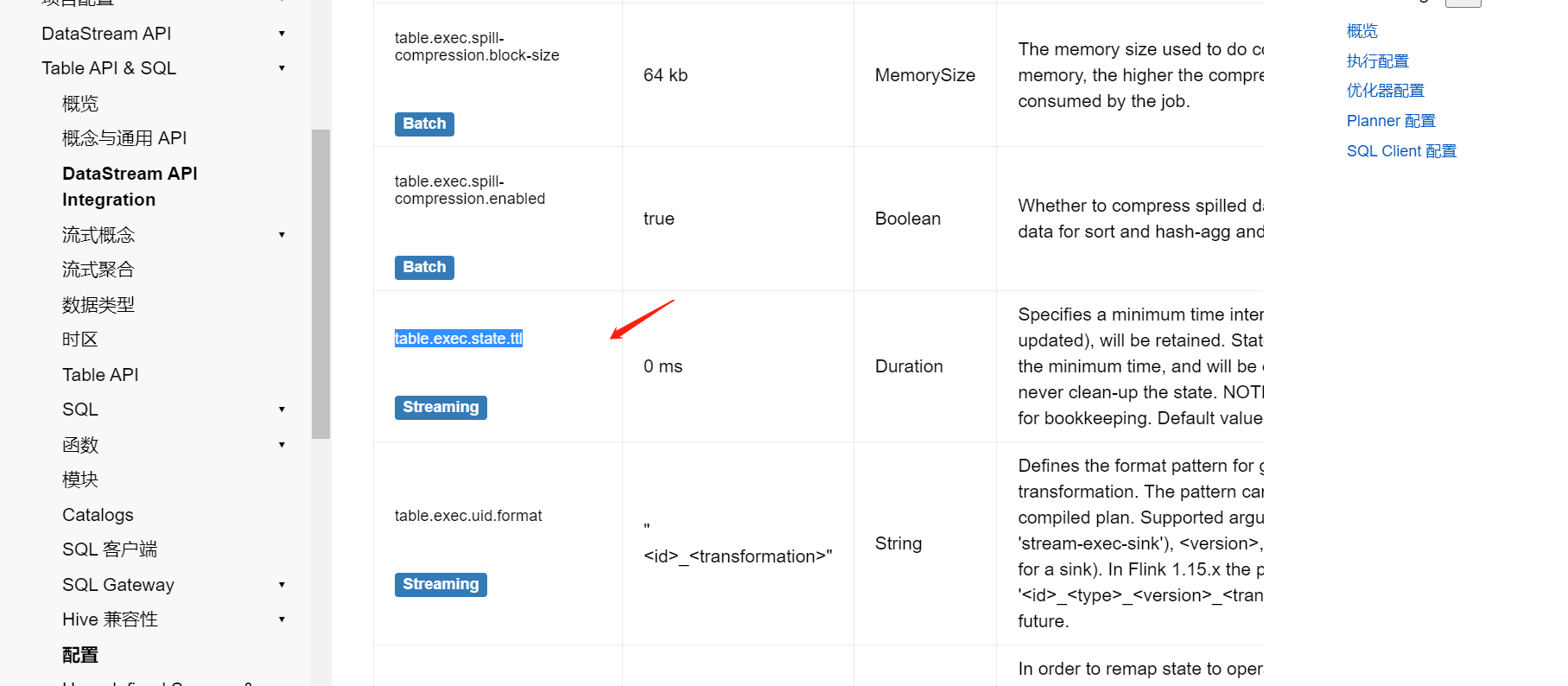
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink中,维度Join的状态管理是一个关键的性能优化点。您提到的“这个值”可能是指与状态管理相关的某些参数(例如缓存策略、TTL等)。如果将某个与状态清理或过期时间相关的值设置为0,可能会导致状态持续增长,从而引发内存压力和性能问题。以下是针对您问题的详细解答:
1. 维度Join状态持续增大的原因
在Flink中,维度Join的状态大小主要受以下因素影响: - 缓存策略:维表Join支持多种缓存策略(如None、LRU、ALL)。如果使用ALL缓存策略且未设置合理的TTL(Time-To-Live),则维表的所有数据会被加载到内存中,并且不会被清理。 - TTL设置:TTL用于控制缓存数据的有效期。如果TTL设置为0,意味着缓存数据永远不会过期,这会导致状态持续增大。 - 流式数据特性:如果源表的数据量非常大,且Join Key存在严重的数据倾斜,也会导致状态膨胀。
因此,如果您的维度Join状态持续增大,可能是由于缓存策略或TTL配置不当导致的。
2. 结果表既是维表又是事实表的情况
在您的场景中,结果表同时作为维表和事实表使用。这种设计需要特别注意以下几点: - 双重角色的影响: - 当结果表作为维表时,其数据会被频繁查询并可能被缓存。 - 当结果表作为事实表时,其数据会不断更新或追加。 - 如果未正确管理状态,可能会导致内存占用过高或性能下降。 - 是否需要修改配置: - 如果结果表的数据量较大且更新频繁,建议调整缓存策略和TTL参数,避免状态无限增长。 - 如果结果表的数据量较小且更新不频繁,可以考虑使用ALL缓存策略以提高查询性能。
3. 如何优化维度Join的状态管理
根据知识库中的信息,您可以采取以下措施来优化维度Join的状态管理:
(1)调整缓存策略
- None:无缓存,适用于对实时性要求极高的场景,但会增加维表查询的IO开销。
- LRU:缓存部分数据,适用于数据量较大且存在时间局部性的场景。
- ALL:缓存所有数据,适用于数据量较小且更新不频繁的场景。如果使用
ALL策略,务必设置合理的TTL。
(2)设置合理的TTL
- TTL决定了缓存数据的有效期。建议根据业务需求设置一个较短的TTL(例如几秒到几十秒),以定期清理过期数据。
- 如果TTL设置为
0,缓存数据将永远不会过期,可能导致状态持续增大。
(3)优化Join顺序
- 在多流Join场景中,优先连接数据量较小的流,最后连接数据量较大的流,以减少状态冗余。
(4)监控和调优内存
- 如果维表或Join节点一直处于
INITIALIZING状态,可能是由于维表过大导致的。建议增加对应节点的内存,或调整缓存策略以降低内存占用。
4. 具体建议
结合您的场景,以下是具体的建议: - 检查当前配置:确认是否使用了ALL缓存策略,以及TTL是否设置为0。如果是,请根据业务需求调整这些参数。 - 评估数据量和更新频率: - 如果结果表的数据量较大且更新频繁,建议使用LRU缓存策略,并设置合理的TTL。 - 如果结果表的数据量较小且更新不频繁,可以继续使用ALL缓存策略,但需确保设置了适当的TTL。 - 监控状态大小:通过Flink的Web UI或日志监控状态大小,及时发现潜在的内存问题。
5. 重要提醒
- 内存限制:使用
ALL缓存策略时,需注意节点内存大小,防止出现OOM(Out of Memory)问题。 - 数据倾斜:如果Join Key存在严重倾斜,建议使用
REPLICATED_SHUFFLE_HASH策略以解决性能瓶颈。 - 异步查询:对于高吞吐场景,可以开启异步查询模式(
table.exec.async-lookup.output-mode),以提高性能。
通过以上优化措施,您可以有效管理维度Join的状态大小,避免因状态持续增大而导致的性能问题。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。