
DataWorks标准版本为什么不能绑定多个集群呢? 不能的话,就没有必要区分生产和开发了啊
问题1:DataWorks标准版本为什么不能绑定多个集群呢? 不能的话,就没有必要区分生产和开发了啊 问题2:dataworks可以把标准模式 改成简单模式么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
十年摸盘键,代码未曾试。 今日码示君,谁有上云事。
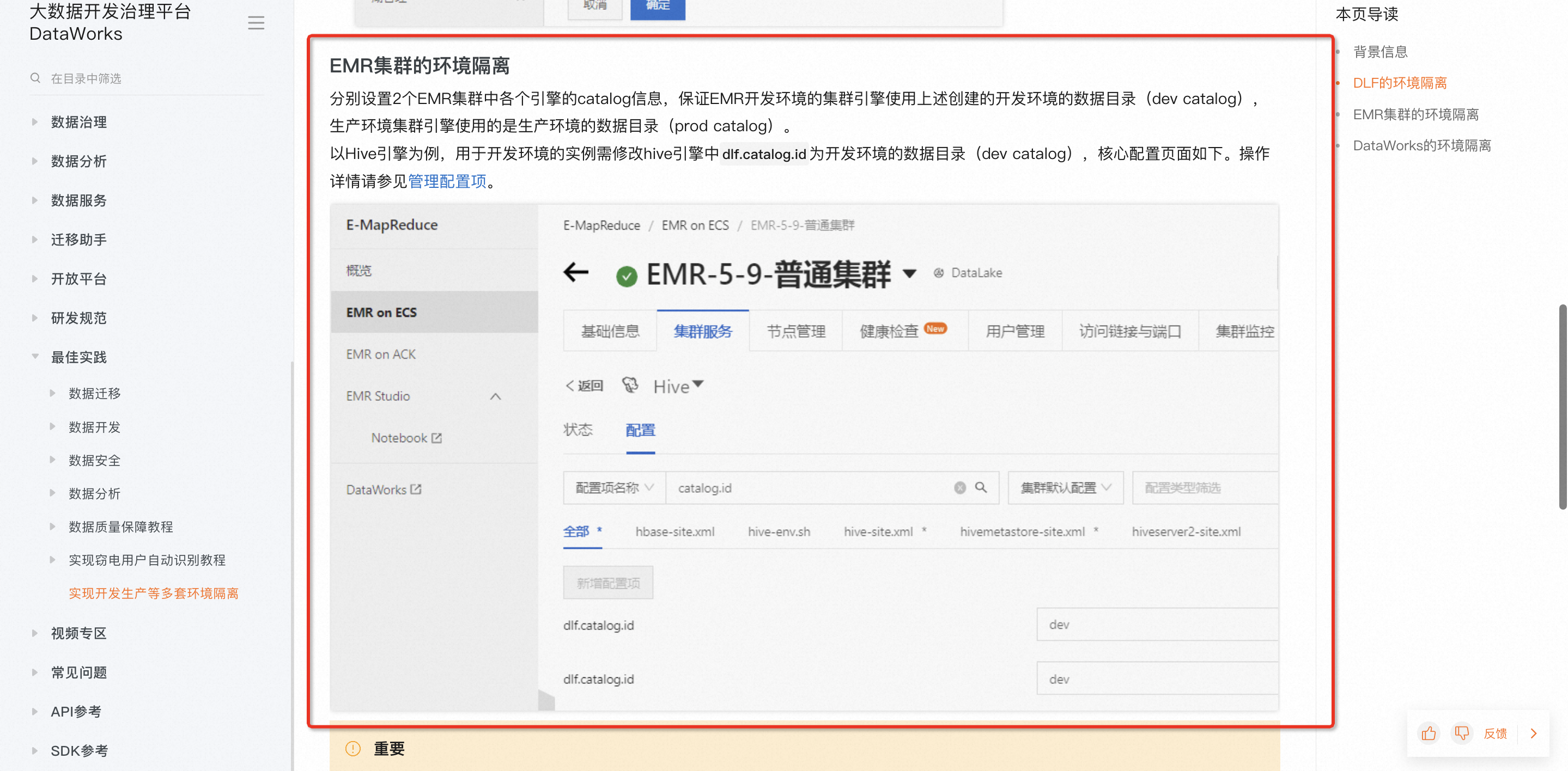
在DataWorks运行EMR(E-MapReduce)作业前,为避免作业运行出错,您需要先检查EMR的DataLake(新版数据湖)集群关键配置是否满足要求。其中,涉及的LDAP、Ranger白名单、安全策略等配置,均是为了在DataWorks运行EMR引擎任务时进行鉴权,在EMR集群认证DataWorks的身份。
集群版本必须大于等于3.41.0或5.7.0。若集群版本过低,则无法使用DataWorks相关功能。
DataWorks可以升级简单模式的工作空间为标准模式。
DataWorks提供简单模式和标准模式两种工作空间模式。 简单模式指一个DataWorks工作空间对应一个MaxCompute项目,无法设置开发环境和生产环境,只能进行简单的数据开发。标准模式指一个DataWorks工作空间对应两个MaxCompute项目,可以设置开发和生产环境,提升代码开发规范。两个模式还存在项目、用户和权限的不同。你可以通过学习官方文档或者是实操来加强认知。 https://help.aliyun.com/document_detail/85772.html
2023-05-21 14:11:41赞同 1 展开评论 -
回答1:可以绑定多个emr引擎 但是如果期望开发生产和隔离 建议是用简单模式 一个空间用做开发环境 一个空间用做生产环境 通过跨项目克隆来发布任务 有个案例可以参考一下 https://help.aliyun.com/document_detail/473053.html?spm=a2c4g.137670.0.0.33f88849Jy7UIJ
 回答2:这个不支持 可以新建一个简单模式的空间后 再绑定这个引擎,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-05-21 12:18:04赞同 展开评论
回答2:这个不支持 可以新建一个简单模式的空间后 再绑定这个引擎,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-05-21 12:18:04赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。