
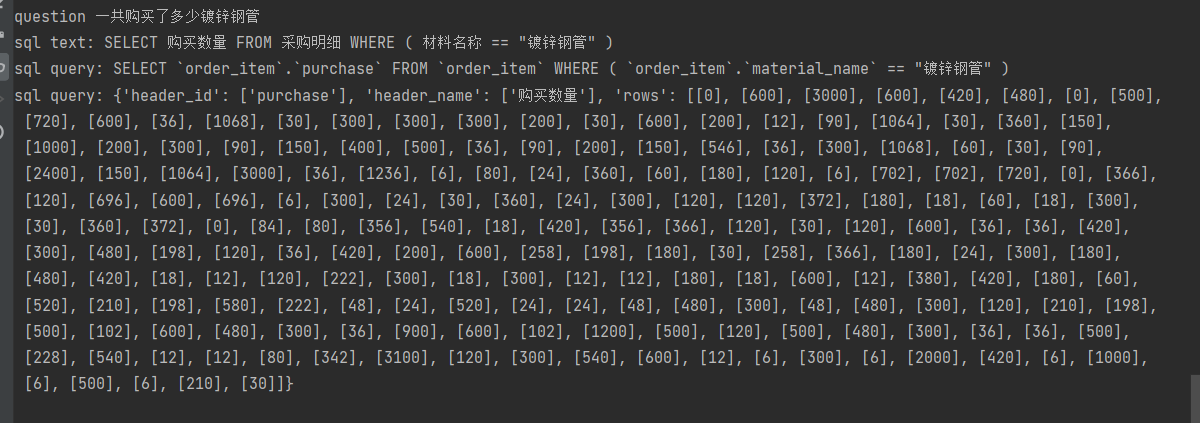
为什么我的运行的 'damo/nlp_convai_text2sql_pre连简单的sum都不行
model_id = 'damo/nlp_convai_text2sql_pretrain_cn'
model = Model.from_pretrained(model_id)
tokenizer = BertTokenizer(os.path.join(model.model_dir, ModelFile.VOCAB_FILE))
db = Database(tokenizer=tokenizer,
# table_file_path=os.path.join('/home/django/users.json'),
table_file_path='/home/django/order_item.json',
syn_dict_file_path=os.path.join(model.model_dir, 'synonym.txt'),
is_use_sqlite=True)
preprocessor = TableQuestionAnsweringPreprocessor(model_dir=model.model_dir, db=db)
pipelines = [
pipeline(
Tasks.table_question_answering,
model=model,
preprocessor=preprocessor,
db=db)
]
test_case = {
'utterance': [['我一共购买了多少镀锌钢管', 'material_item']]
}
for pipeline in pipelines:
historical_queries = None
for question, table_id in test_case['utterance']:
output_dict = pipeline({
'question': question,
'table_id': table_id,
'history_sql': historical_queries
})[OutputKeys.OUTPUT]
print('question', question)
print('sql text:', output_dict[OutputKeys.SQL_STRING])
print('sql query:', output_dict[OutputKeys.SQL_QUERY])
print('sql query:', output_dict[OutputKeys.QUERT_RESULT])
print()
historical_queries = output_dict[OutputKeys.HISTORY]
class Command(BaseCommand):
help = 'Generate JSON data for OrderItem'
def handle(self, *args, **options):
header_id = ['id', 'material_name', 'sku', 'purchase',
'unit',
'order_name',
'user',
'time']
header_name = ["编码", "材料名称", "规格", "购买数量", "单位", "材料单名称", "采购者", '时间']
header_types = ["text", "text", "text", "number", "text", "text", "text", "date"]
header_units = ["", "", "", "个", "", "", "", ""]
header_attribute = ["PRIMARY", "MODIFIER", "MODIFIER", "MODIFIER", "MODIFIER", "MODIFIER", "MODIFIER",
"MODIFIER"]
rows = []
order_items = OrderItem.objects.all()
for o in order_items:
rows.append([
str(o.id),
remove_special_chars(o.material.name),
remove_special_chars(o.material.sku),
o.buy_num,
remove_special_chars(o.material.unit),
# str(o.order.id),
remove_special_chars(o.order.name),
# str(o.order.created_by.id),
remove_special_chars(o.order.created_by.name),
o.order.created_time.date().isoformat(),
])
data = {
"table_id": "order_item",
"table_name": "采购明细",
"header_id": header_id,
"header_name": header_name,
"header_types": header_types,
"header_units": header_units,
"header_attribute": header_attribute,
"rows": rows
}
with open('order_item.json', 'w') as f:
json.dump(data, f, ensure_ascii=False)
self.stdout.write(json.dumps(data))
展开
收起
相关问答

热门讨论
热门文章
请问微调开元模型qwe1.5b 和 7b 分别支持数据集的上下文长度是多少个汉字/token?
437
如何提高qwen-7b-chat-int4的并行处理能力
965
如何下载llama模型到本地?
2005
modelscope-funasr的byte[] 8k 转16k 有什么好的方式吗?java?
30
modelscope-funasr离线中文语音识别C++版本,有对音频的长度做限制吗?
34
练的pth模型文件,怎么转成bin文件?
217
modelscope-funasrbash的finetune.sh命令下载训练模型显示错误,怎么办?
24
在modelscope-funasr如果是从web端使用麦克风录入,能实现吗?
23
modelscope-funasr这个问题怎么解决?
23
modelscope-funasr在finetune时报keyerror bpemodel是什么错?
22
展开全部
LLM 大模型学习必知必会系列(一):大模型基础知识篇
177
LLM 大模型学习必知必会系列(二):提示词工程-Prompt Engineering 以及实战闯关
143
检索增强生成(RAG)实践:基于LlamaIndex和Qwen1.5搭建智能问答系统
167
基于LangChain-Chatchat实现的本地知识库的问答应用-快速上手(检索增强生成(RAG)大模型)
177
RAG:AI大模型联合向量数据库和 Llama-index,助力检索增强生成技术
103
ModelScope X 昇腾910快速上手
192
DashVector&千问7B模型,打造极简RAG 之 基于专属知识的问答服务实践
235
AI智能写作工具
732
中文大模型评测
760
高通量基因测序在药物研发和靶向治疗中的应用(一)
740
展开全部


相关文章
相关电子书
更多

