
请问下 file_fdw 有办法逆序返回csv的数据么?csv里的数据是顺序的新增或更新记录,我想
请问下 file_fdw 有办法逆序返回csv的数据么?csv里的数据是顺序的新增或更新记录,我想用 insert into table select * from file_fdw ON CONFLICT DO NOTHING;这样就只保留最新的一条数据了。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
file_fdw并不支持按照逆序返回CSV的数据,因为CSV文件的数据是按照顺序排列的,无法直接按照逆序查询。 如果想保留最新的一条数据,可以在使用INSERT INTO语句的时候,加上ORDER BY语句,将数据按照时间戳或者其他字段的倒序排列,然后再加上LIMIT 1语句,只插入最新的一条数据。
2023-03-18 14:14:26赞同 展开评论 -
全栈JAVA领域创作者
file_fdw 是 PostgreSQL 的一个外部数据包装器,用于访问服务器文件系统中的数据文件或在服务器上执行程序并读取它们的输出。数据文件或程序输出必须是能够被 COPY FROM 读取的格式[3]。然而,根据提供的搜索结果,关于 file_fdw 是否能够直接逆序返回 CSV 数据的信息并不明确。
作为替代方案,您可以先将 CSV 文件的数据导入到一个临时表中,然后通过 SQL 查询对数据进行排序。首先,创建一个临时表,并将 CSV 文件的数据导入到该临时表中。接下来,执行以下 SQL 查询,以逆序方式将数据插入到目标表中:
sql Copy code INSERT INTO target_table SELECT * FROM temp_table ORDER BY your_timestamp_column DESC ON CONFLICT DO NOTHING; 这将确保仅保留最新的一条数据。当然,这种方法需要首先将 CSV 数据导入到临时表中,而不是直接使用 file_fdw。
2023-03-18 07:54:55赞同 展开评论 -
file_fdw可以逆序返回csv的数据。可以使用ORDER BY子句来指定逆序排序的列,例如:SELECT * FROM file_fdw ORDER BY column_name DESC。这将按照指定列的逆序顺序返回数据。然后,您可以使用INSERT INTO语句将最新的一条数据插入到表中,使用ON CONFLICT DO NOTHING来避免重复插入。
2023-03-17 08:40:30赞同 展开评论 -
发表文章、提出问题、分享经验、结交志同道合的朋友
你好,有两种方式可以实现这个需求。
一、使用file_fdw提供的options参数中的reverse选项

二、查询中使用Order by子句对数据进行逆序排序
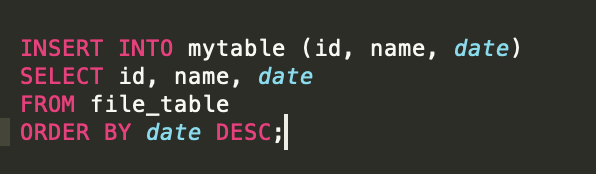 2023-03-16 22:59:24赞同 展开评论
2023-03-16 22:59:24赞同 展开评论 -
你看看这个, 可能修改一下读csv的部分可以支持你的需求
https://multicorn.org/foreign-data-wrappers/#filesystem-foreign-data-wrapper
此答案来自钉钉群“PG|POLARDB技术进阶"
2023-03-16 18:45:32赞同 展开评论


PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about