
云原生大数据计算服务 MaxCompute 中,MaxCompute Migration Assis
已解决云原生大数据计算服务 MaxCompute 中,MaxCompute Migration Assist (MMA)是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
推荐回答
MMA目前主要面向Hadoop数据迁移的场景,支持Hive到MaxCompute迁移。MMA实现了Hive的 UDTF,通过Hive的分布式能力,实现Hive数据向MaxCompute的高并发传输。通过连接用户的Hive Metastore服务,抓取Hive Metadata,并利用这些数据生成用于创建MaxCompute表和分区的DDL语句以及用于迁移数据的HiveUDTF SQL。
以下是整个迁移链路的简要示意图,供参考:
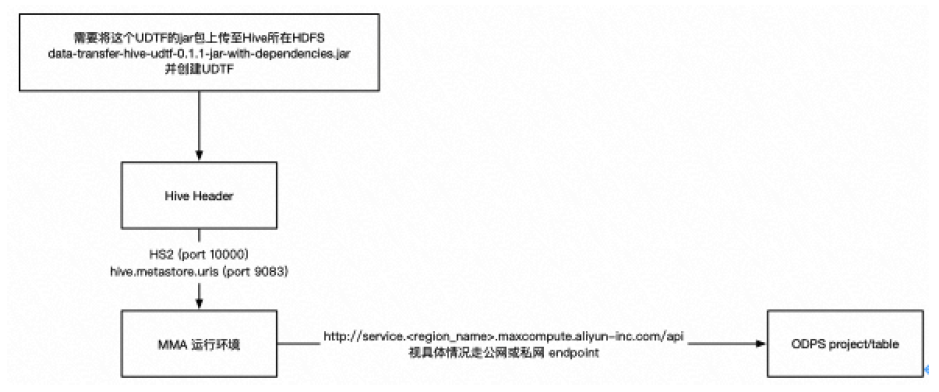
当用户通过 MMA client 向 MMA server 提交一个迁移 Job 后,MMA 首先会将该 Job 的配置记录在元数据中,并初始化其状态为 PENDING。
随后,MMA 调度器将会把这个 Job 状态置为 RUNNING,向 Hive 请求这张表的元数据,并开始调度执行。这个 Job 在 MMA 中会被拆分为若干 个 Task,每一个Task 负责表中的一部分数据的传输,每个 Task 又会拆分为若干个 Action 进行具体传输和验证。在逻辑结构上,每一个 Job 将会包含若干个 Task 组成的 DAG,而每一个 Task 又会包含若干个 Action 组成的 DAG。整体的流程大致如下:
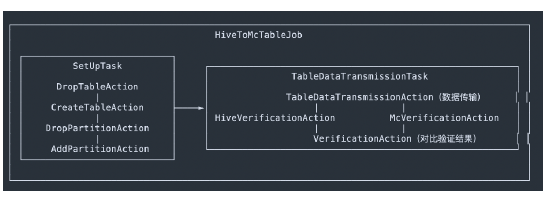
上图中数据传输的原理是利用Hive的分布式计算能力,实现了一个Hive UDTF,在Hive UDTF中实现了上传数据至MaxCompute的逻辑,并将一个数据迁移任务转化为一个或多个形如:
SELECT UDTF(*) FROM hive_db.hive_table;
的Hive SQL。在执行上述Hive SQL时,数据将被Hive读出并传入UDTF,UDTF会通过MaxCompute的 Tunnel SDK将数据写入MaxCompute。
当某一个Task的所有Action执行成功后,MMA会将这个Task负责的部分数据的迁移状态置为 SUCCEEDED。当该Job对应的所有Task都成功后,这张表的迁移结束。
当某一个Task的某一个Action执行失败,MMA会将这个Task负责的部分数据的迁移状态置为 FAILED,并生成另一个Task负责这部分数据,直到成功或达到重试次数上限。
当表中数据发生变化时(新增数据,新增分区,或已有分区数据变化),可以重新提交迁移任务,此时MMA会重新扫描Hive中元数据,发现数据变化,并迁移发生变化的表或分区。
以上内容摘自《企业级云原生白皮书项目实战》电子书,点击https://developer.aliyun.com/ebook/download/7774可下载完整版
2022-10-17 18:58:49赞同 展开评论


MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
