
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
从您提供的截图来看,这是一个机器学习模型训练的过程。以下是一些优化建议:
使用GPU加速:如果您的机器支持GPU加速,那么可以使用GPU来加速模型的训练过程。大多数深度学习框架都支持在GPU上进行训练。
数据集预处理:对于较大的数据集,可以进行数据集的预处理,如数据清洗、数据采样等,以减小模型训练的时间和内存消耗。
模型结构优化:尝试不同的模型结构或超参数组合,以找到最佳的模型结构,同时减少模型训练的时间和内存消耗。
批量训练:批量训练可以有效地利用计算资源,加快训练速度。您可以调整批量大小,以获得最佳的性能和准确性。
分布式训练:对于大规模数据集和复杂的模型,可以考虑使用分布式训练来加速训练过程。多台计算机可以并行训练模型,缩短训练时间。
内存管理:在训练过程中,适当地释放内存可以避免内存溢出和提高训练速度。您可以使用一些内存管理工具如TensorFlow Profiler来监控和优化内存使用。
希望这些建议能够帮助您优化模型训练过程。
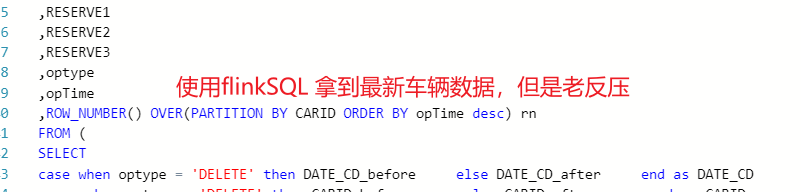
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



