
求大神解答!
DaemonSet方式的filebeat 收集 机器 项目应用LOG 到ELK,怎么ELK更好划分出项目维度index 1是项目名称,2是日志文件 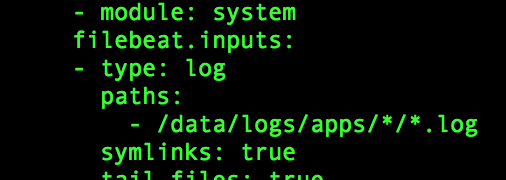
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要在使用DaemonSet方式部署的Filebeat收集机器上的项目应用日志,并将这些日志有效地划分到Elasticsearch中以项目维度的索引进行管理,你可以通过配置Filebeat的输入和输出部分来实现这一需求。以下是一个基于此需求的配置指导:
1. 配置Filebeat Input
首先,确保Filebeat能够正确地读取各个项目的日志文件。这通常涉及到在Filebeat的配置文件(如filebeat.yml)中定义多个输入,每个输入对应一个或一组特定的日志文件路径。你可以根据项目名称和日志文件的命名规则来动态生成索引名称。
例如,假设你的日志文件结构是按项目名和日期组织的,如下: - /var/log/projects/project1/logs/app.log - /var/log/projects/project2/logs/app.log
你可以在Filebeat配置中为每个项目设置输入,或者使用通配符匹配所有项目日志路径,并利用字段处理器(processors)动态设置索引名称。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/projects/*/*/*.log
fields:
project: "${path.basename}/${path.dirname}"
这里,${path.basename} 和 ${path.dirname} 是Filebeat内部变量,用于从路径中提取项目名称和进一步细分的信息。这个配置会自动识别项目目录并将其作为project字段添加到事件中。
2. 动态索引命名
接下来,你需要在Filebeat的Elasticsearch输出配置中,利用上面设置的project字段来动态生成索引名称。同时,可以考虑加入日期字段以保持索引的时序性。
output.elasticsearch:
hosts: ["your_elasticsearch_host:9200"]
index: "project-%{[fields.project]}-%{[agent.version]}-%{+yyyy.MM.dd}"
在这个配置中,project-%{[fields.project]}-%{[agent.version]}-%{+yyyy.MM.dd} 表示索引名称将会包含“project-”前缀、从日志文件路径解析出的项目名称、Filebeat版本号以及日期(年月日格式),这样既区分了不同项目,又保持了数据的时序性。
3. Elasticsearch模板与映射
为了更好地管理和查询这些索引,建议在Elasticsearch中预先创建一个索引模板,该模板可以根据项目名称自动应用到新创建的索引上。模板中可以定义字段映射、分析器等,以优化搜索性能和结果质量。
PUT _template/project_logs_template
{
"index_patterns": ["project-*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"_source": {
"enabled": true
},
"properties": {
"@timestamp": { "type": "date" },
"message": { "type": "text" },
"project": { "type": "keyword" }
// 其他字段映射...
}
}
}
通过上述步骤,你可以实现以项目维度有效划分和管理ELK中的日志索引,便于后续的分析和检索。