汇编语言和本地代码
我们在之前的文章中探讨过,计算机 CPU 只能运行本地代码(机器语言)程序,用 C 语言等高级语言编写的代码,需要经过编译器编译后,转换为本地代码才能够被 CPU 解释执行。
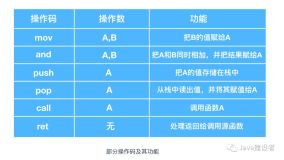
但是本地代码的可读性非常差,所以需要使用一种能够直接读懂的语言来替换本地代码,那就是在各本地代码中,附带上表示其功能的英文缩写,比如在加法运算的本地代码加上add(addition) 的缩写、在比较运算符的本地代码中加上cmp(compare)的缩写等,这些通过缩写来表示具体本地代码指令的标志称为 助记符,使用助记符的语言称为汇编语言。这样,通过阅读汇编语言,也能够了解本地代码的含义了。
不过,即使是使用汇编语言编写的源代码,最终也必须要转换为本地代码才能够运行,负责做这项工作的程序称为编译器,转换的这个过程称为汇编。在将源代码转换为本地代码这个功能方面,汇编器和编译器是同样的。
用汇编语言编写的源代码和本地代码是一一对应的。因而,本地代码也可以反过来转换成汇编语言编写的代码。把本地代码转换为汇编代码的这一过程称为反汇编,执行反汇编的程序称为反汇编程序。

哪怕是 C 语言编写的源代码,编译后也会转换成特定 CPU 用的本地代码。而将其反汇编的话,就可以得到汇编语言的源代码,并对其内容进行调查。不过,本地代码变成 C 语言源代码的反编译,要比本地代码转换成汇编代码的反汇编要困难,这是因为,C 语言代码和本地代码不是一一对应的关系。
通过编译器输出汇编语言的源代码
我们上面提到本地代码可以经过反汇编转换成为汇编代码,但是只有这一种转换方式吗?显然不是,C 语言编写的源代码也能够通过编译器编译称为汇编代码,下面就来尝试一下。
首先需要先做一些准备,需要先下载 Borland C++ 5.5 编译器,为了方便,我这边直接下载好了读者直接从我的百度网盘提取即可 (链接:https://pan.baidu.com/s/19LqVICpn5GcV88thD2AnlA 密码:hz1u)
下载完毕,需要进行配置,下面是配置说明 (https://wenku.baidu.com/view/22e2f418650e52ea551898ad.html),教程很完整跟着配置就可以,下面开始我们的编译过程
首先用 Windows 记事本等文本编辑器编写如下代码
// 返回两个参数值之和的函数 int AddNum(int a,int b){ return a + b; } // 调用 AddNum 函数的函数 void MyFunc(){ int c; c = AddNum(123,456); }
编写完成后将其文件名保存为 Sample4.c ,C 语言源文件的扩展名,通常用.c 来表示,上面程序是提供两个输入参数并返回它们之和。
在 Windows 操作系统下打开 命令提示符,切换到保存 Sample4.c 的文件夹下,然后在命令提示符中输入
bcc32 -c -S Sample4.c
bcc32 是启动 Borland C++ 的命令,-c 的选项是指仅进行编译而不进行链接,-S 选项被用来指定生成汇编语言的源代码
作为编译的结果,当前目录下会生成一个名为Sample4.asm 的汇编语言源代码。汇编语言源文件的扩展名,通常用.asm 来表示,下面就让我们用编辑器打开看一下 Sample4.asm 中的内容
.386p
ifdef ??versionif ??version GT 500H
.mmx
endif
endif
model flat
ifndef ??version
?debug macro
endm
endif
?debug S "Sample4.c"
?debug T "Sample4.c"
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_TEXT segment dword public use32 'CODE'
_AddNum proc near
?live1@0:
;
; int AddNum(int a,int b){
;
push ebp
mov ebp,esp
;
;
; return a + b;
;
@1:
mov eax,dword ptr [ebp+8]
add eax,dword ptr [ebp+12]
;
; }
;
@3:
@2:
pop ebp
ret
_AddNum endp
_MyFunc proc near
?live1@48:
;
; void MyFunc(){
;
push ebp
mov ebp,esp
;
; int c;
; c = AddNum(123,456);
;
@4:
push 456
push 123
call _AddNum
add esp,8
;
; }
;
@5:
pop ebp
ret
_MyFunc endp
_TEXT ends
public _AddNum
public _MyFunc
?debug D "Sample4.c" 20343 45835
end
这样,编译器就成功的把 C 语言转换成为了汇编代码了。
不会转换成本地代码的伪指令
第一次看到汇编代码的读者可能感觉起来比较难,不过实际上其实比较简单,而且可能比 C 语言还要简单,为了便于阅读汇编代码的源代码,需要注意几个要点
汇编语言的源代码,是由转换成本地代码的指令(后面讲述的操作码)和针对汇编器的伪指令构成的。伪指令负责把程序的构造以及汇编的方法指示给汇编器(转换程序)。不过伪指令是无法汇编转换成为本地代码的。下面是上面程序截取的伪指令
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
DGROUP group _BSS,_DATA
_AddNum proc near
_AddNum endp
_MyFunc proc near
_MyFunc endp
_TEXT ends
end
由伪指令 segment 和 ends 围起来的部分,是给构成程序的命令和数据的集合体上加一个名字而得到的,称为段定义。段定义的英文表达具有区域的意思,在这个程序中,段定义指的是命令和数据等程序的集合体的意思,一个程序由多个段定义构成。
上面代码的开始位置,定义了3个名称分别为 _TEXT、_DATA、_BSS 的段定义,_TEXT 是指定的段定义,_DATA 是被初始化(有初始值)的数据的段定义,_BSS 是尚未初始化的数据的段定义。这种定义的名称是由 Borland C++ 定义的,是由 Borland C++ 编译器自动分配的,所以程序段定义的顺序就成为了 _TEXT、_DATA、_BSS ,这样也确保了内存的连续性
_TEXT segment dword public use32 'CODE'
_TEXT ends
_DATA segment dword public use32 'DATA'
_DATA ends
_BSS segment dword public use32 'BSS'
_BSS ends
段定义( segment ) 是用来区分或者划分范围区域的意思。汇编语言的 segment 伪指令表示段定义的起始,ends 伪指令表示段定义的结束。段定义是一段连续的内存空间
而group 这个伪指令表示的是将 _BSS和_DATA 这两个段定义汇总名为 DGROUP 的组
DGROUP group _BSS,_DATA
围起_AddNum 和 _MyFun 的 _TEXT segment 和 _TEXT ends ,表示_AddNum 和 _MyFun 是属于 _TEXT 这一段定义的。
_TEXT segment dword public use32 'CODE'
_TEXT ends
因此,即使在源代码中指令和数据是混杂编写的,经过编译和汇编后,也会转换成为规整的本地代码。
_AddNum proc 和 _AddNum endp 围起来的部分,以及_MyFunc proc 和 _MyFunc endp 围起来的部分,分别表示 AddNum 函数和 MyFunc 函数的范围。
_AddNum proc near
_AddNum endp
_MyFunc proc near
MyFunc endp
编译后在函数名前附带上下划线 ,是 Borland C++ 的规定。在 C 语言中编写的 AddNum 函数,在内部是以 _AddNum 这个名称处理的。伪指令 proc 和 endp 围起来的部分,表示的是 过程(procedure) 的范围。在汇编语言中,这种相当于 C 语言的函数的形式称为过程。
末尾的 end 伪指令,表示的是源代码的结束。
</div>