本文作为上篇主要介绍内存对齐的理论基础,后续的下篇将侧重于 C++ 语言层面的实践,敬请期待!
TL;DR
- 处理器以若干字节的块而不是单字节的粒度访问内存,因此对于未对齐的内存需要额外的访存及计算开销,导致性能更差。
- 原子操作和矢量运算指令要求内存地址必须是对齐的,否则可能导致程序死循环和数据错误。
- 编译器通过 padding 自动对结构中的字段进行对齐,用以向后兼容以及提高效率。
- 内存对齐在某种意义上扩大了可使用的地址空间范围,甚至影响计算机系统的物理设计。
- 内存对齐使得处理器能够更好地利用 cache,包括减少 cache line 访问,以及避免多核一致性问题引发的 cache miss。
作为 C++ 程序员,总是免不了直接与内存打交道,尤其是开发数据库、嵌入式系统、设备驱动这类较为底层的软件时,经常会遇到需要进行内存对齐的情况,这对于 C++ 来说并非难事。不过在进入语言层面之前,我们最好追本溯源,从计算机的底层机制出发,先弄明白内存到底为什么需要对齐?
内存访问的粒度
内存之所以有“对齐”的概念,本质上源于程序员(或者说高级编程语言)和处理器看待内存访问的粒度不同。在程序员眼中,内存基本上等同于“字节的数组”,一般用来逐字节访问,也就是说编程时内存访问的粒度是字节(bitfield、位运算除外)。比如在 C++ 中,我们往往用 char* 或 uint8_t* 来操作裸的内存。

然而对于计算机的处理器来说,内存并非以字节为单位来读写,而是以二的幂次字节的 chunk 形式进行访问,例如 2、4、8、16 甚至 32 个字节。

我们通过一个例子来看不同的访存粒度如何影响处理器的操作。假设现在需要从地址 0 处读四字节到寄存器,然后再从地址 1 处读四字节到同一个寄存器。
- 如果处理器的访存粒度为 1 字节(也就是程序员眼中的模型),那么从地址 0 处和从地址 1 处开始读一样,都需要 4 次访存。
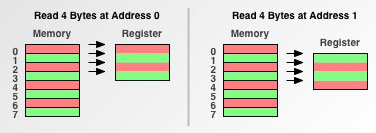
- 如果访存粒度为 2 字节(如 68000 处理器),那么显然从地址 0 处开始读需只要 2 次访存,相比之前少了一半的访存次数,而由于每次访存操作的开销是固定的,因此这里的性能相比之前提升了一倍。然而,对于从地址 1 处开始读的情况,由于该地址和处理器访存的边界不匹配(不是 2 的倍数),导致处理器需要进行 3 次访存操作(0-1, 2-3, 4-5),最后只取其中 1-4 的部分。因此,这种未对齐的地址就会导致处理器的额外开销。

- 如果访存粒度为 4 字节(如 68030 或 PowerPC 601),从对齐的地址开始读 4 字节仅需 1 次访存,而未对齐的地址则会导致两倍的访存次数。
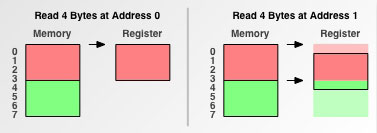
由此我们不难理解,访存粒度所带来的内存对齐问题会给程序带来不可小觑的影响。事实上,如果使用了未对齐的内存,轻则会使得程序性能变差、卡死,重则引发操作系统崩溃,甚至悄悄引发程序数据错误,最终导致不可预期的结果。下面逐一来阐述。
性能
为了深入理解处理器如何处理未对齐的内存,我们仔细来看一下上面的例子中 4 字节访存粒度的处理器从地址 1 处读取 4 字节时究竟发生了什么:
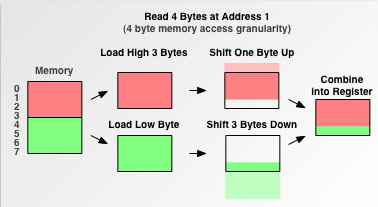
如图所示,处理器首先需要读取未对齐内存的高位部分所在的内存块,并通过位移操作去掉不要的 1 个字节;然后,再读取低位部分,同样位移掉不要的 3 个字节;最后,通过或运算将两部分内存合并起来,存入寄存器中。可以看到,除了额外的一次访存,未对齐内存还会带来更多的计算开销。
有些早期的处理器干脆不支持未对齐的内存。例如,前文提到的 2 字节粒度处理器 68000 就没有处理未对齐地址的元件,当遇到这样的地址时,它会直接抛出一个异常。如果操作系统未能处理好这种异常,就只能重启机器。
后来的处理器虽然取消了这种限制,能够为你处理好未对齐的内存,但显然这会导致额外的开销。PowerPC 针对未对齐的 32 位整数访问提供了专门的硬件支持,以尽可能减少性能损耗。但另一方面,对于未对齐的 64 位浮点数访问,现代的 PowerPC 会抛出一个异常并交由操作系统进行对齐操作。尽管如此,在软件层进行内存对齐还是比在硬件层处理慢得多。
总而言之,未对齐内存带来的性能损耗终归是无法避免的。如果你想知道究竟会差多少,这里有一个测试可以参考。
原子性
所有的现代处理器都提供原子操作指令,顾名思义,这种指令是不可分割的,即不能被抢占,这对于并发程序的同步至关重要。而要实现这一点的,传递给原子指令的地址必须至少是 4 字节对齐的,这是因为原子指令和虚拟内存之间存在一种微妙的关联。
如前所述,一个未对齐的地址至少需要两次访存操作,那么如果要访问的数据跨越了两个虚存页呢?考虑第一个页在内存中而第二个页不在的情况,当原子指令访存到一半时发生了缺页中断,此时处理器转而执行内存页换入换出的代码,于是该指令的原子性也就被破坏了。为了避免这种情况,最简单的办法就是要求地址必须是对齐的。
然而不幸的是,当遇到原子变量存储到一个未对齐的地址时,PowerPC 并不会抛出异常,而是表现出总是存储失败。由于多数原子操作的代码被写成失败时循环重试的形式,这就会导致程序陷入死循环。
矢量运算(Altivec)
Altivec is all about speed.
我们已经知道,未对齐的内存会拖慢处理器的速度,这自然与矢量运算的初衷相悖。因此,Altivec 被简单地设计成不支持未对齐的内存访问。由于 Altivec 指令一次使用 16 字节的内存块,所以传递给 Altivec 的所有地址都必须是 16 字节对齐的。类似原子指令,如果你一定要传给它未对齐的地址,它同样也不会抛出异常,而只是简单地忽略未对齐的部分并继续在错误的地址上执行运算。这意味着你的程序会默默地导致内存被破坏,然而返回错误的结果。这样做换来的好处是不需要对地址做截断等操作,从而节省了一两条指令。
实际上 Altivec 是可以处理未对齐内存的,只是需要更多工作,详见 Altivec Programming Environments Manual.
结构对齐
考虑这样一个简单的结构:
struct Struct {
char a;
long b;
char c;
};这个结构的大小是多少字节?有人可能会回答 6 字节,毕竟 1 + 4 + 1 = 6,类似这样:
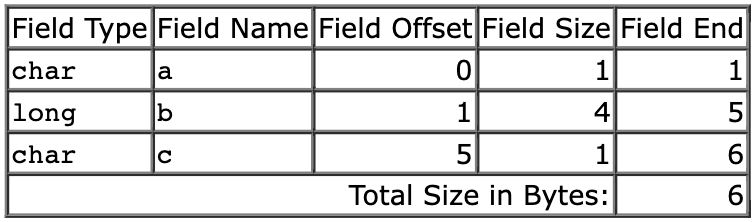
然而,如果你问编译器 sizeof(Struct) 是多少,大概率得到的答案大于 6,也许是 8 甚至 24 字节。以 8 字节为例,则 Struct 的内存布局是这样的:
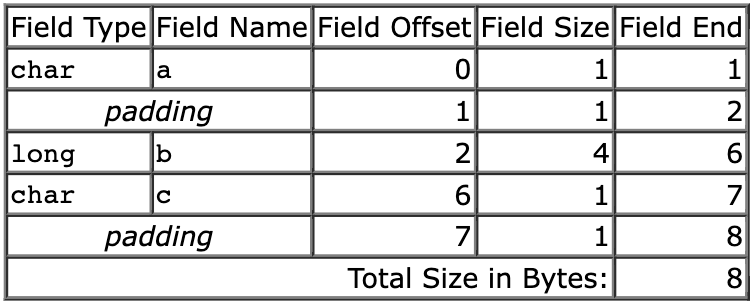
可以看到,编译器通过增加未使用的 padding 空间实现字段的内存对齐,从而使得 b 和 c 处于偶数地址上。这样做有两个原因:
- 向后兼容:例如对于 2 字节粒度的处理器,如果
Struct中的字段未经对齐,则会引发硬件异常; - 效率:晶体管比内存更宝贵,对齐虽会浪费一些内存,但能减轻处理器的额外负担,本质上是空间换时间。
地址空间范围
如果内存地址均为 4 字节对齐的,则所有地址的最低 2 bits 始终为 0(例如在 32 位机器上),那么每次地址递增时,实际上是在递增 bit 2,而不是 bit 0。这就意味着理论上我们可以访问 4 倍的内存地址空间,省下来的 2 bits 可以代表 4 个不同的状态,或者用于标志之类的东西。
这甚至会影响计算机系统的物理设计。如果地址总线需要少 2 bits,CPU 上的引脚可以少 2 个,同时 CPU 上的走线也可以少 2 个。
Cache
内存对齐还与 cache 有着紧密的联系。
如前所示,现代的处理器不会逐字节访问内存,而是通常以 64 字节的块(称为 cache line)获取内存。当你读取一个特定的内存位置时,整个 cache line 会先从主内存提取到 cache 中,在这之后从同一 cache line 中访问其他值是很快的。而内存是否对齐决定了一个操作会触及一个还是两个 cache line,显然访问一个 cache line 会比访问两个快得多。
此外,在多核机器上,通常 L1 cache 是 per-core 的,由此带来了一致性的问题:当一个核修改其缓存中的值时,其他核就不能再使用旧值,导致该内存位置在所有 cache 中失效。又由于 cache 在 cache line 的粒度上运行,因此整个 cache line 会在所有 cache 中失效,进而引发其他核下次访问相关数据时的 cache miss。
在这种情况下,将需要高频并发访问的数据按 cache line 大小对齐或许是比较好的做法。一方面,对于小于 64 字节的数据可以做到只触及一个 cache line;另一方面,相当于独占了整个 cache line,避免其他数据可能修改同一 cache line 导致其他核 cache miss 的开销。
关于 cache 还有一些很有意思的实验,感兴趣的读者可以参考这篇文章。
References
- https://stackoverflow.com/questions/381244/purpose-of-memory-alignment
- https://web.archive.org/web/20080607055623/http://www.ibm.com/developerworks/library/pa-dalign/
- http://igoro.com/archive/gallery-of-processor-cache-effects/
