
四、使用Superset
1.登录Superset。
在浏览器地址栏中输入http://emr-header-1:18088,按回车,打开Superset登录界面,默认用户名和密码均为admin,请您登录后及时修改密码。

2.添加E-MapReduce Druid集群。
登录后默认为英文界面,可单击右上角的国旗图标选择合适的语言。接下来在上方菜单栏中依次选择数据源 > Druid 集群来添加一个E-MapReduce Druid集群。

配置好协调机(Coordinator)和代理机(Broker)的地址,注意E-MapReduce中默认端口均为相应的开源端口前加数字1,例如开源Broker 端口为8082,E-MapReduce中为18082。

3.刷新或者添加新数据源。
添加好E-MapReduce Druid集群之后,您可以单击数据源 > 扫描新的数据源,这时E-MapReduce Druid集群上的数据源(datasource)就可以自动被加载进来。
您也可以在界面上单击数据源 > Druid 数据源自定义新的数据源(其操作等同于写一个data source ingestion的json文件),步骤如下。
自定义数据源时需要填写必要的信息,然后保存。

保存之后单击左侧set,编辑该数据源,填写相应的维度列与指标列等信息。

4. 查询E-MapReduce Druid。
数据源添加成功后,单击数据源名称,进入查询页面进行查询。

5.(可选)将E-MapReduce Druid作为E-MapReduce Druid数据库使用。
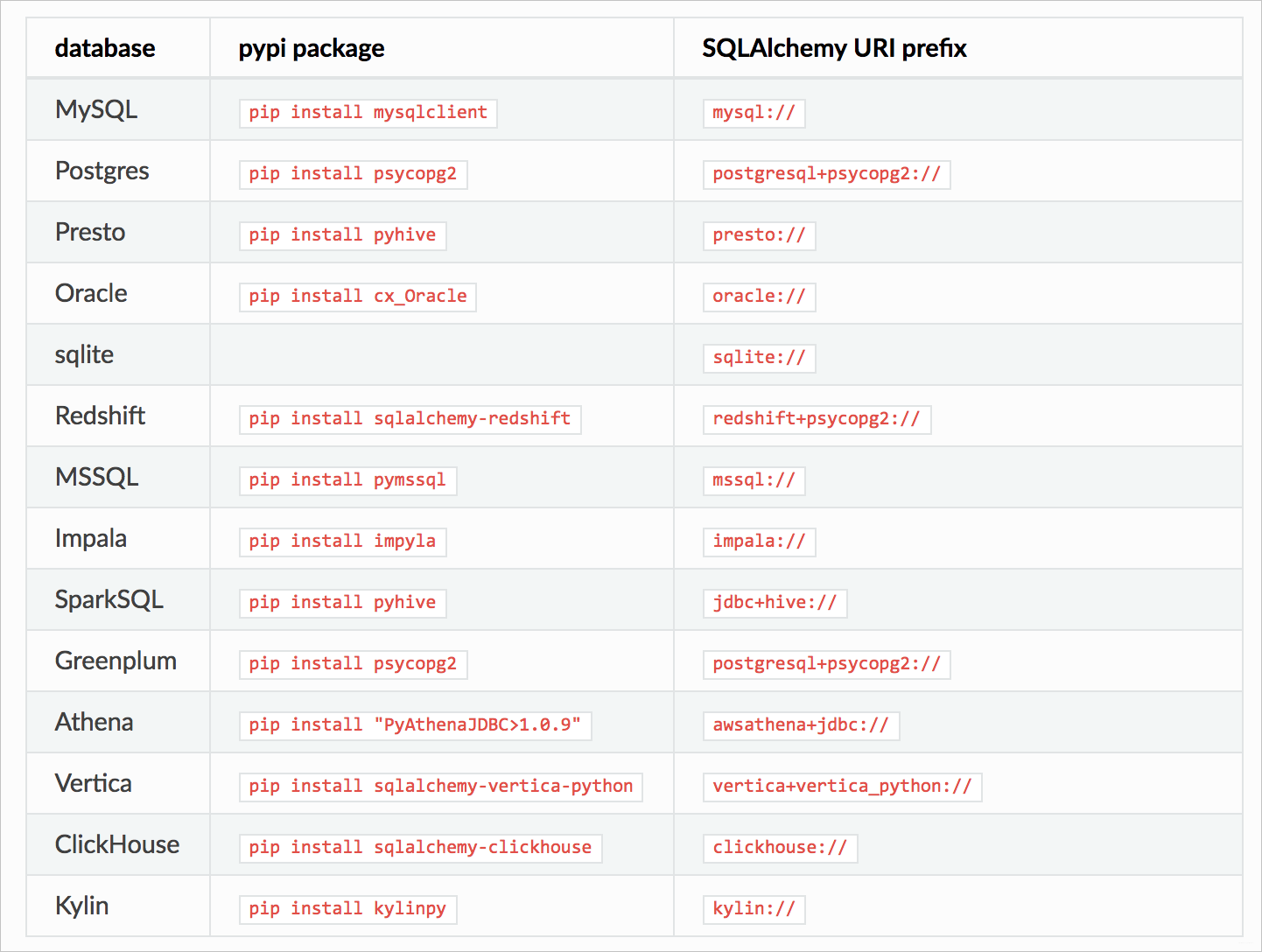
Superset提供了SQLAlchemy以多种方言支持各种各样的数据库,其支持的数据库类型如下表所示。、
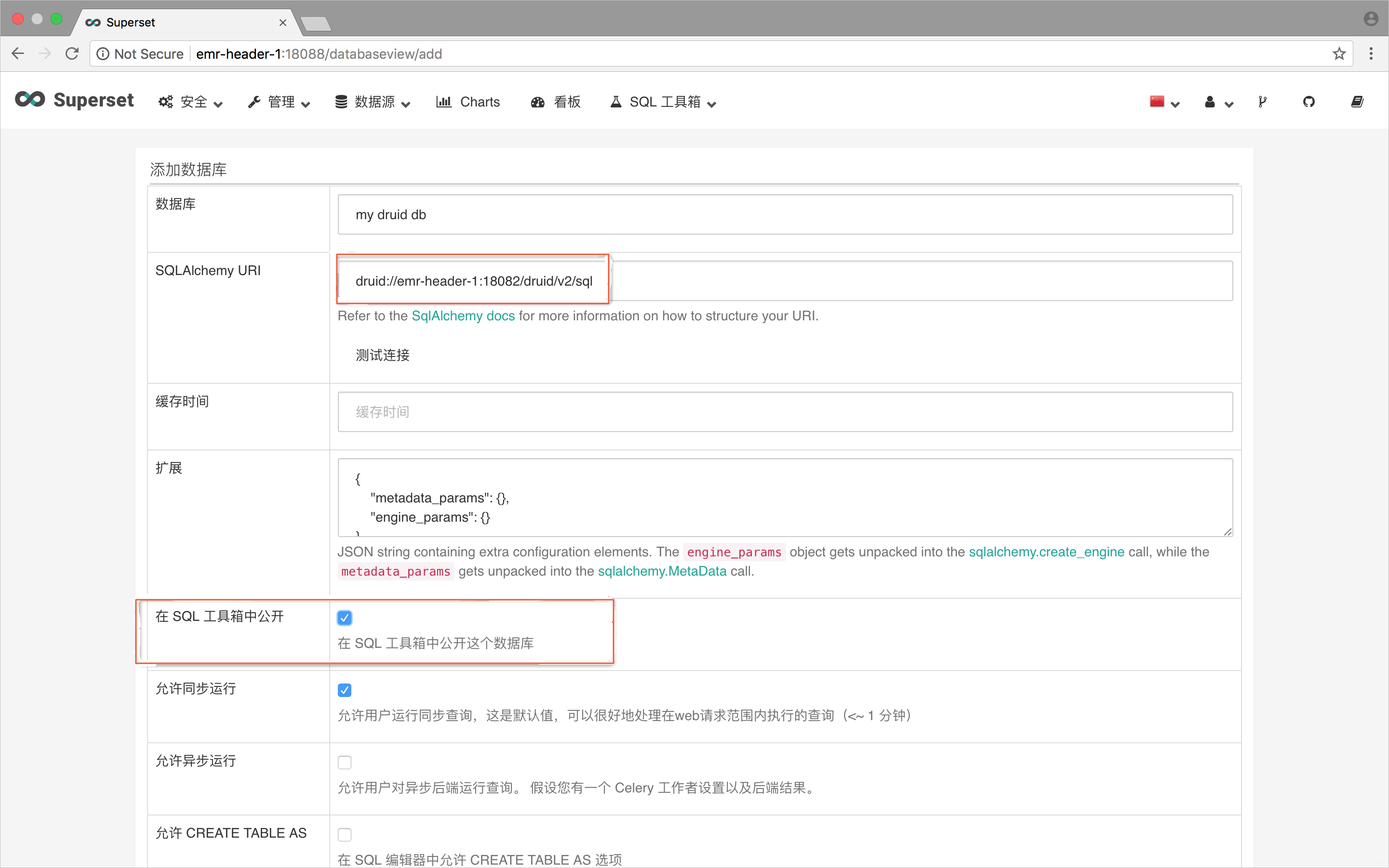
Superset亦支持该方式访问E-MapReduce Druid,E-MapReduce Druid对应的 SQLAlchemy URI为druid://emr-header-1:18082/druid/v2/sql,如下图所示,将E-MapReduce Druid作为一个数据库添加。
接下来就可以在SQL工具箱里用SQL进行查询了。

