
三、从 Hadoop 加载数据
3.1 加载数据
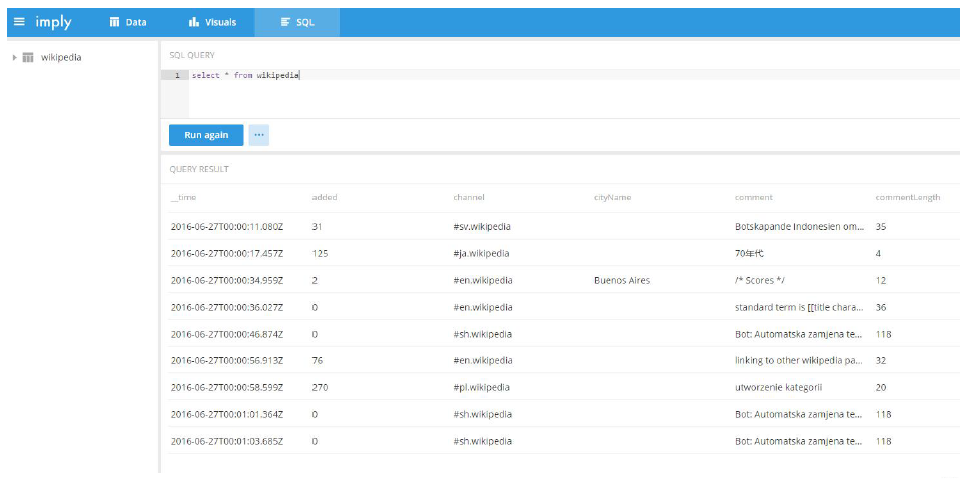
批量摄取维基百科样本数据,文件位于quickstart/wikipedia-2016-06-27-sampled.json。使用
quickstart/wikipedia-index-hadoop.json 摄取任务文件。
bin/post-index-task --file quickstart/wikipedia-index-hadoop.json
此命令将启动Druid Hadoop 摄取任务。
摄取任务完成后,数据将由历史节点加载,并可在一两分钟内进行查询。
3.2 查询数据
四、从 kafka 加载数据
4.1 准备kafka
启动kafka
[chris@hadoop102 kafka]$ bin/kafka-server-start.sh config/server.properties [chris@hadoop103 kafka]$ bin/kafka-server-start.sh config/server.properties [chris@hadoop104 kafka]$ bin/kafka-server-start.sh config/server.properties
创建wikipedia 主题
[chris@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 –topic wikipedia --partitions 1 --replication-factor 1 –create Created topic "wikipedia".
查看主题是否创建成功
[chris@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list __consumer_offsets first wikipedia
4.2 启动索引服务
我们将使用Druid 的Kafka 索引服务从我们新创建的维基百科主题中提取消息。要启动该服务,我们需要通过从Imply 目录运行以下命令向Druid 的overlord 提交supervisor spec。
[chris@hadoop102 imply-2.7.10]$ curl -XPOST -H'Content-Type: application/json' -d @quickstart/wikipedia-kafka-supervisor.json http://hadoop102:8090/druid/indexer/v1/supervisor
说明:
curl 是一个利用 URL 规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具。
- -X 为HTTP 数据包指定一个方法,比如PUT、DELETE。默认的方法是GET 6.4.3
- -H 为HTTP 数据包指定 Header 字段内容
- -d 为POST 数据包指定要向HTTP 服务器发送的数据并发送出去,如果的内容以符号@ 开头,其后的字符串将被解析为文件名,curl 命令会从这个文件中读取数据发送。
4.3 加载历史数据
启动kafka 生产者生产数据
[chris@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 – -topic wikipedia < /opt/module/imply-2.7.10/quickstart/wikipedia-2016-06-27-sampled.json
说明:
< 将文件作为命令输入
可在kafka 本地看到相应的数据生成
[chris@hadoop103 logs]$ pwd /opt/module/kafka/logs
将样本事件发布到Kafka 的wikipedia 主题,然后由Kafka 索引服务将其提取到Druid 中。你现在准备运行一些查询了!
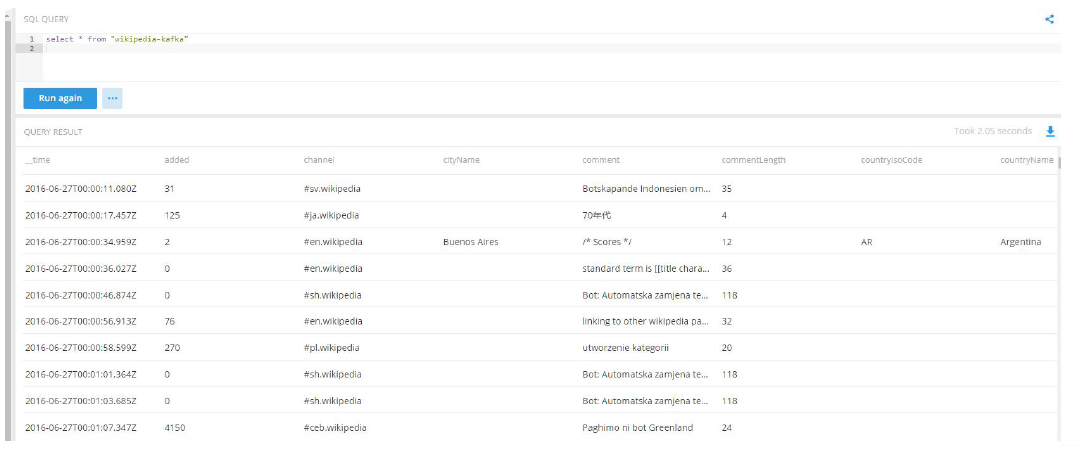
4.4 加载实时数据
下载一个帮助应用程序,该应用程序将解析维基媒体的IRC 提要中的event,并将这些event发布到我们之前设置的Kafka 的wikipedia 主题中。
[chris@hadoop102 imply-2.7.10]$ curl -O https://static.imply.io/quickstart/wikiticker-0.4.tar.gz
说明:
-O 在本地保存获取的数据时,使用它们在远程服务器上的文件名进行保存。
[chris@hadoop102 imply-2.7.10]$ tar -zxvf wikiticker-0.4.tar.gz [chris@hadoop102 imply-2.7.10]$ cd wikiticker-0.4
现在运行带有参数的wikiticker,指示它将输出写入我们的Kafka 主题:
[chris@hadoop102 wikiticker-0.4]$ bin/wikiticker -J-Dfile.encoding=UTF-8 -out kafka – topic Wikipedia
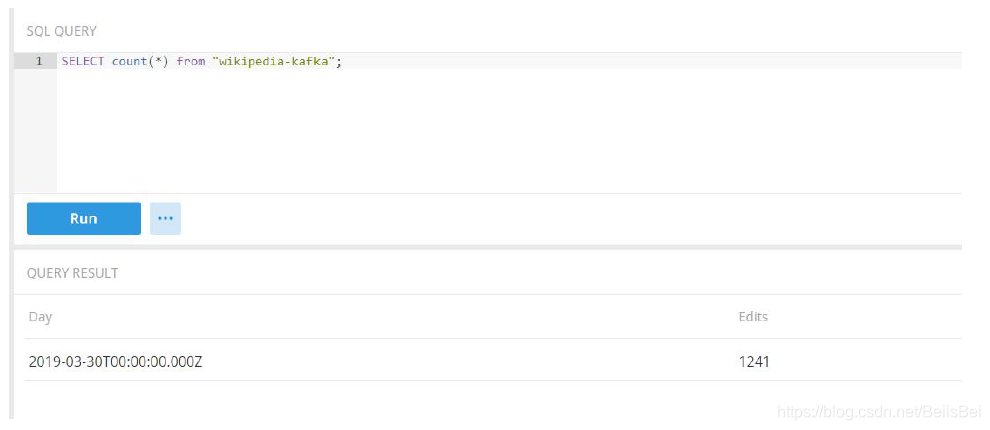
查询多次,对比结果的变化
4.5 加载自定义kafka 主题数据
可以通过编写自定义supervisor spec 来加载自己的数据集。要自定义受监督的Kafka 索引服务提取,可以将包含的quickstart/wikipedia-kafka-supervisor.json 规范复制到自己的文件中,根据需要进行编辑,并根据需要创建或关闭管理程序。没有必要自己重启Imply 或Druid 服务。



