文章目录
一、Apache Druid 部署
1.1 单机版
1.1.1 Jar 包下载
1.1.2 Druid 的安装部署
1.2 Docker 容器版
1.2.1 下载
1.2.2 配置 Docker 文件共享
1.2.3 启动
1.2.4 校验
Historical 容器
PostgreSQL 容器
1.3 Kubernetes 集群版
1.3.1 安装
1.3.2 校验
1.3.3 ZooKeeper 元数据
1.3.4 Broker 健康检查
1.3.5 Historical 缓存
1.3.6 Segment 文件
1.3.7 Coordinator 动态配置
1.3.8 Druid SQL 查询
二、配置
2.1 常用端口
2.2 rollup
2.3 selectStrategy
2.4 maxRowsPerSegment
2.5 druid.server.tier
2.6 tieredReplicants
2.7 Coordinator Rule 配置
一、Apache Druid 部署
1.1 单机版
1.1.1 Jar 包下载
从 https://imply.io/get-started 下载最新版本安装包
1.1.2 Druid 的安装部署
说明:imply 集成了Druid,提供了Druid 从部署到配置到各种可视化工具的完整的解决方案,
imply 有点类似Cloudera Manager。
1.解压
tar -zxvf imply-2.7.10.tar.gz -C /opt/module
目录说明如下:
bin/ - run scripts for included software.
conf/ - template configurations for a clustered setup.
conf-quickstart/* - configurations for the single-machine quickstart.
dist/ - all included software.
quickstart/ - files related to the single-machine quickstart.
2.修改配置文件
1)修改Druid 的ZK 配置
[chris@hadoop102 _common]$ pwd /opt/module/imply/conf/druid/_common [chris@hadoop102 _common]$ vi common.runtime.properties druid.zk.service.host=hadoop102:2181,hadoop103:2181,hadoop104:218 1
2)修改启动命令参数,使其不校验不启动内置ZK
[chris@hadoop102 supervise]$ pwd /opt/module/imply/conf/supervise :verify bin/verify-java #:verify bin/verify-default-ports #:verify bin/verify-version-check :kill-timeout 10 #!p10 zk bin/run-zk conf-quickstart
3.启动
1)启动zookeeper
2)启动imply
[chris@hadoop102 imply]$ bin/supervise -c conf/supervise/quickstart.conf
说明:每启动一个服务均会打印出一条日志。可以通过/opt/module/imply-2.7.10/var/sv/查看服务启动时的日志信息
3)查看端口号9095 的启动情况
[chris@hadoop102 ~]$ netstat -anp | grep 9095 tcp 0 0 :::9095 :::* LISTEN 3930/imply-ui-linux tcp 0 0 ::ffff:192.168.1.102:9095 ::ffff:192.168.1.1:52567 ESTABLISHED 3930/imply-ui-linux tcp 0 0 ::ffff:192.168.1.102:9095 ::ffff:192.168.1.1:52568 ESTABLISHED 3930/imply-ui-linux
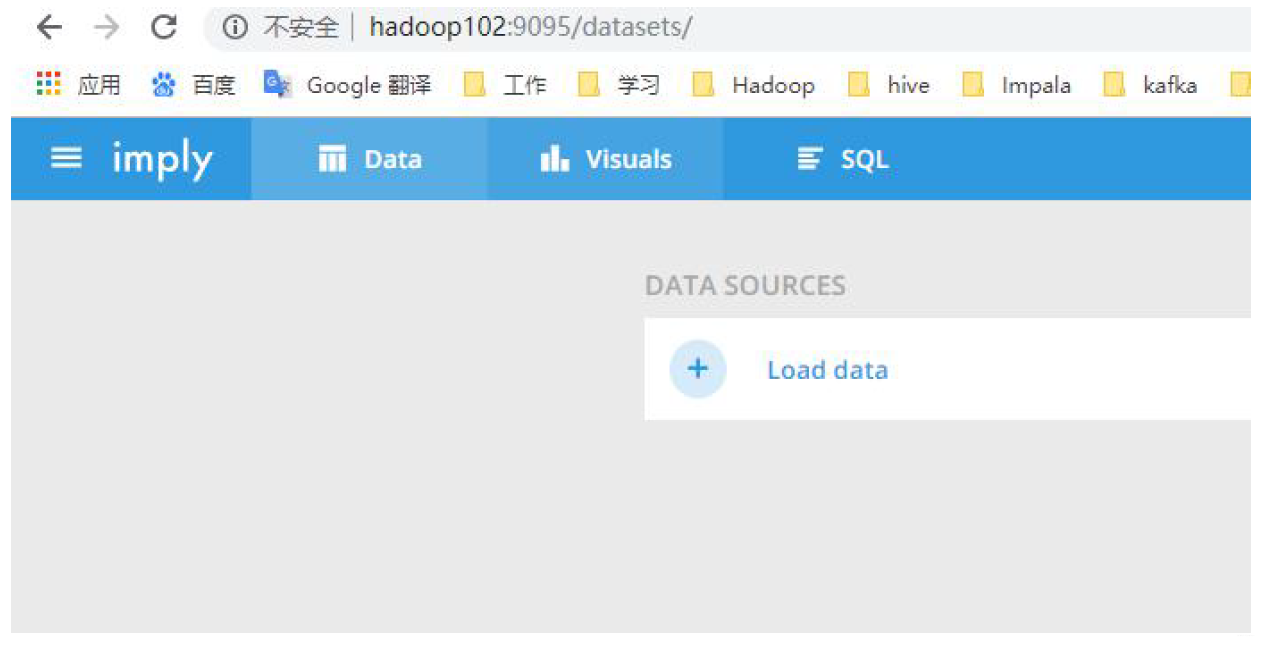
4.登录hadoop102:9095 查看
5.停止服务
按Ctrl + c 中断监督进程, 如果想中断服务后进行干净的启动, 请删除
/opt/module/imply-2.7.10/var/目录。
1.2 Docker 容器版
1.2.1 下载
# 搜索 Docker Hub $ docker search druid # 下载最新版本的镜像 $ docker pull apache/druid:0.19.0 # 检查镜像是否下载成功 $ docker image list
1.2.2 配置 Docker 文件共享
打开配置面板,进入 File Sharing 配置页面,增加 ${the path of your source code}/distribution/docker/storage 路径,随后点击 Apply & Restart 按钮,应用并重启
1.2.3 启动
$ git clone https://github.com/apache/druid.git $ cd druid $ docker-compose -f distribution/docker/docker-compose.yml up # 同理,也可以使用 start/stop 命令启停容器 $ docker-compose -f distribution/docker/docker-compose.yml stop $ docker-compose -f distribution/docker/docker-compose.yml start # 或者使用 down 命令移除容器 $ docker-compose -f distribution/docker/docker-compose.yml down
1.2.4 校验
Historical 容器
$ docker exec -it historical sh $ ls /opt/data/ indexing-logs segments $ ls /opt/data/segments/ intermediate_pushes wikipedia $ ls /opt/data/segments/wikipedia/ 2016-06-27T00:00:00.000Z_2016-06-28T00:00:00.000Z $ ls /opt/data/segments/wikipedia/2016-06-27T00\:00\:00.000Z_2016-06-28T00\:00\:00.000Z/ 2020-06-04T07:11:42.714Z $ ls /opt/data/segments/wikipedia/2016-06-27T00\:00\:00.000Z_2016-06-28T00\:00\:00.000Z/2020-06-04T07\:11\:42.714Z/0/ index.zip $ ls -lh
total 8M
-rw-r--r-- 1 druid druid 5.9M Jun 4 07:49 00000.smoosh -rw-r--r-- 1 druid druid 29 Jun 4 07:49 factory.json -rw-r--r-- 1 druid druid 1.7M Jun 4 07:14 index.zip -rw-r--r-- 1 druid druid 707 Jun 4 07:49 meta.smoosh -rw-r--r-- 1 druid druid 4 Jun 4 07:49 version.bin $ cat factory.json
{"type":"mMapSegmentFactory"}
$ xxd version.bin
00000000: 0000 0009 ....
$ cat meta.smoosh
v1,2147483647,1 __time,0,0,1106 channel,0,145739,153122 cityName,0,153122,195592 comment,0,195592,1598156 count,0,1106,2063 countryIsoCode,0,1598156,1614170 countryName,0,1614170,1630859 diffUrl,0,1630859,4224103 flags,0,4224103,4252873 index.drd,0,6162513,6163275 isAnonymous,0,4252873,4262876 isMinor,0,4262876,4282592 isNew,0,4282592,4290896 isRobot,0,4290896,4298796 isUnpatrolled,0,4298796,4307345 metadata.drd,0,6163275,6163925 namespace,0,4307345,4342089 page,0,4342089,5710071 regionIsoCode,0,5710071,5730339 regionName,0,5730339,5759351 sum_added,0,2063,37356 sum_commentLength,0,37356,66244 sum_deleted,0,66244,81170 sum_delta,0,81170,126275 sum_deltaBucket,0,126275,145739 user,0,5759351,6162513
其中,index.drd 包含该 Segment 覆盖的时间范围、指定的 Bitmap 种类(concise / roaring),以及包含的列和维度;而 metadata.drd 包含是否 Rollup、哪些聚合函数、查询的粒度,时间戳字段信息,以及可用于存储任意 Key-Value 数据的 Map 结构(例如 Kafka Firehose 用来存储 offset 信息)。更多细节详见 org.apache.druid.segment.IndexIO.V9IndexLoader#load
PostgreSQL 容器 $ docker exec -it postgres bash $ psql -U druid -d druid $ \l
List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+-------+----------+------------+------------+------------------- druid | druid | UTF8 | en_US.utf8 | en_US.utf8 | postgres | druid | UTF8 | en_US.utf8 | en_US.utf8 | template0 | druid | UTF8 | en_US.utf8 | en_US.utf8 | =c/druid + | | | | | druid=CTc/druid template1 | druid | UTF8 | en_US.utf8 | en_US.utf8 | =c/druid + | | | | | druid=CTc/druid (4 rows)
$ \c druid
You are now connected to database "druid" as user "druid".
$ \dt
List of relations Schema | Name | Type | Owner --------+-----------------------+-------+------- public | druid_audit | table | druid public | druid_config | table | druid public | druid_datasource | table | druid public | druid_pendingsegments | table | druid public | druid_rules | table | druid public | druid_segments | table | druid public | druid_supervisors | table | druid public | druid_tasklocks | table | druid public | druid_tasklogs | table | druid public | druid_tasks | table | druid (10 rows)
> select id, datasource, created_date, start, "end", partitioned, version, used from public.druid_segments;
wikipedia_2016-06-27T00:00:00.000Z_2016-06-28T00:00:00.000Z_2020-06-04T07:11:42.714Z | wikipedia | 2020-06-04T07:14:50.619Z | 2016-06-27T00:00:00.000Z | 2016-06-28T00:00:00.000Z | t | 2020-06-04T07:11:42.714Z | t