串的定义:
串是由零个或多个任意字符组成的序列。
我们通常这样定义:s = “a1,a2,a3…,an”
s代表串的名字,用双引号括起来的是串的值。其中串含有字符的数目称为串的长度。当然串可以为空,那么,就是不含有任何字符。
还有要注意的是,由 一个或者多个空格组成的串称为空格串。
还有就是有关子串和主串的概念。我们这样加以区分:串中任意连续的字符组成的子序列称为该串的子串。包含子串的串称为主串。很好理解。
我们来举个例子
我们来随便写几个串:
a = “1,2,3” b=“4,5,6” c=“1,2” d=“6”
我们这里讲,a是c的主串,c是a的子串;同理,b是d的主串,d是b的子串。
就是这样,这些定义的东西总是极其无聊的。就像我们初次感知数学时,知道一些算术,我们开始可能会觉得无聊,没神魔卵用,但事实上,算术已经融入生活的方方面面,成为必不可少的一部分。因此我们在数据结构学到这些枯燥而乏味的东西,要有耐心,我也这样告诉自己。
串的存储结构:
1)串的顺序存储结构
有些计算机采用的字编址方式,即数组元素的分量占4个字节。由此产生紧缩和非紧缩存储区别。
紧缩存储: 一个字的存储单元中存放4个字符;
特点: 节省空间,需要二次寻址,牺牲了CPU时间。
非紧缩存储: 一个字的存储单元中只存放1个字符。
特点: 寻址快,浪费空间,存储密度低。
2)串的链表存储结构
与顺序存储结构类似也有紧缩和非紧缩存储结构的区别。插入、删除操作效率高;存储空间的利用率低;
对于紧缩存储 存储利用率是 50% (data 域4个字节,指针域也4个字节);
对于非紧缩存储 存储利用率是20% (8个字节只存放一个字符)。
3)堆存储结构
串的顺序存储和链表存储各有利弊,在实际应用中常采用一种动态存储结构,称其为堆结构。定义一个很大的连续空间和相应的指针结构。指针用来指示串在堆中的位置;
例如,设有 a=‘BEI’,b=‘ JING’,c=‘’,d=‘SHANGHAI’;
这很专业,也很让人懵逼。因为涉及计算机存储的东西。我们来尽量说明白。
总之串有三种存储结构
定长顺序存储:实际上就是用普通数组(又称静态数组)存储。例如 C 语言使用普通数据存储字符串的代码为 char a[20] = “data.biancheng.net”;
堆分配存储:用动态数组存储字符串;
块链存储:用链表存储字符串;
这样讲就明白了许多了吧
三种存储结构的代码解释
1:定长的顺序存储:
char str[6] = jgdabc";
2:堆分配存储:
char * s = (char*)malloc(5*sizeof(char)); 此行代码创建了一个动态数组 s,通过使用 malloc 申请了 5 个 char 类型大小的堆存储空间。 strcpy(s, "jgdabc");//将字符串"jgdabc"复制给s
3:块链存储:
我们来看一些图

可以看到,每个节点存储的数据元素个数可以不一样
单链表限制了每个节点只能有一个指针,但没有限制数据域存储元素的个数
我们来看代码
下面展示一些 内联代码片。
typedef struct Link { char s[100]; //数据域可存放 100 个数据 struct Link * next; //代表指针域,指向直接后继元素 }link; link * initLink(link * head, char * str) { int length = strlen(str); //根据字符串的长度,计算出链表中使用节点的个数 int num = length/linkNum; if (length%linkNum) { num++; } //创建并初始化首元节点 head = (link*)malloc(sizeof(link)); head->next = NULL; link *temp = head; //初始化链表 for (int i = 0; i<num; i++) { int j = 0; for (; j<100; j++) { if (i*100+ j < length) { temp->a[j] = str[i*l00+ j]; } else temp->a[j] = '#'; } if (i*100 + j < length) { link * newlink = (link*)malloc(sizeof(link)); newlink->next = NULL; temp->next = newlink; temp = newlink; } } return head; } ........ ........ int main() { link * head = NULL; head = initLink(head, "jgdabc"); }
我们初学c语言时对串的操作常用的就是第一种方法
数据结构里对串最有趣的操作就是模式匹配了。
好的,开始总结。
两种,BF和KMP算法
1:BF模式匹配
到了no picture you say a j8 环节
第一次匹配

第二次匹配

第三次匹配

第四次匹配

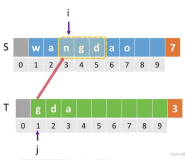
ok,过程很容易看明白,我们把B就叫做源串,把A叫做目标串。
我们来看代码:
#include <stdio.h> #include <string.h> //这里要分清主串和子串 int mate(char * B,char *A){ int i=0,j=0; while (i<strlen(B) && j<strlen(A)) { if (B[i]==A[j]) { i++; j++; }else{ i=i-j+1; j=0; } } //跳出循环有两种可能,i=strlen(B)说明已经遍历完主串,匹配失败;j=strlen(A),说明子串遍历完成,在主串中成功匹配 if (j==strlen(A)) { return i-strlen(A)+1; } //运行到此,为i==strlen(B)的情况 return 0; } int main() { int number=mate("jgdabejgdabc", "jgdabc"); printf("%d",number); return 0; }
或者这样
#include<stdio.h> int main() { char s[20]; char p[5]; printf("Please input the source string:"); scanf("%s",s); printf("Please input the goal string:"); scanf("%s",p); printf("The result of finding is:%d\n",Find(s,p)); } int Find(char*s,char*p) { int j=0,i=0,k=0; int r=-1; while(r==-1&&s[i]!='\0') { while(p[j]==s[i]&&p[j]!='\0') { i++; j++; } if(p[j]=='\0') { r=k; } else { j=0; k++; i=k; } } return r; }
我们来分析BM算法的时间复杂度,最好的情况就是一次就匹配成功,时间复杂度为O(n),n为B串的长度。最坏的情况就是在A串的末尾才能匹配完。那么时间复杂度为O(m*n),其中m为A串的长度。可见,其实BM算法的效率比较低。
2:KMP算法

可以看到,第六个字符是不匹配的,我们叫他坏字符

可以分析到最长可匹配后缀字符串

我们进行一个移动

匹配到坏字符

分析最长可匹配字符串

移动

按照此方法进行下去
我们来看代码
#include<stdio.h> #include<string.h> #include<stdlib.h> FILE *fin=fopen("test.in","r"); FILE *fout=fopen("test.out","w"); char s1[200],s2[200]; int next[200]; int max(int a,int b) { if(a>b) return a; return b; } void getnext() { memset(next,0,sizeof(next)); int i=-1,j=0; next[0]=-1; while(j<strlen(s2)) { if(i==-1||s2[i]==s2[j]){ i++; j++; next[j]=i; } else i=next[i]; } } int KMP() { int i=0,j=0,len1=strlen(s1),len2=strlen(s2); while((i<len1)&&(j<len2)) { if(j==-1||s1[i]==s2[j]) {j++;i++;} else j=next[j]; } if(j==len2) return i-len2; else return -1; } int index_KMP() { int i=0,j=0,len1=strlen(s1),len2=strlen(s2),re=0; while(i<len1&&j<len2) { if(j==-1||s1[i]==s2[j]) {i++;j++;} else j=next[j]; re=max(re,j); } return re; } int main() { fscanf(fin,"%s",s1); for(int i=1;i<=3;i++) { fscanf(fin,"%s",s2); getnext(); fprintf(fout,"%d %d\n",KMP(),index_KMP()); } return 0; }
我的数据结构书上并没有多讲KMP这种复杂的算法。
关于KMP实现的基本原理和解答,大家点击这里KMP模式匹配,另一位大佬的讲解
数据结构很多东西偏于算法,c语言是偏向底层的东西。
c语言版的数据结构更是让你如痴如醉。有些东西很难,但我们需要学习的还是得去专研

![正则表达式深度解析:使用带 [ ] 的字符类](https://ucc.alicdn.com/z3pojg2spmpe4_20240407_ef612d68d58e425c914c3961d9778232.png?x-oss-process=image/resize,h_160,m_lfit)