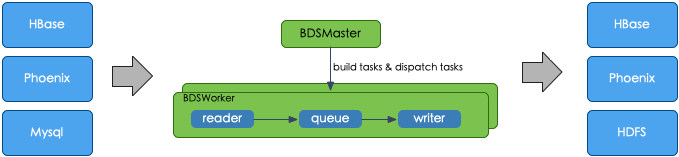
一、数据迁移方案
数据迁移,更多的场景是外部的数据源如何将数据写入到HBase
1.数据库RDBMS
1)sqoop 2)kettle ETL工具 3)其他方式 **写程序 **导出文件加载
2.数据文件(log)
1)flume:实时数据收集,将数据的数据插入到HBase source,channel,sink 2)MapReduce input file -> mr -> hbase table 3)completebulkload(常用) input file -> mr -> hfile -> completebulkload -> hbase table
二、数据迁移实施
(1)通过importtsv命令
通过importtsv命令,将文件直接导入到HBase
importtsv -Dimporttsv.columns=a,b,c <tablename> <inputdir>
准备数据:stu.tsv
0001 henry 20 city-1 0002 cherry 30 city-2 0003 alex 29 city-3
将数据放在HDFS上
bin/hdfs dfs -put /opt/datas/stu.tsv /user/caizhengjie/datas
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.9.3.jar \ importtsv \ -Dimporttsv.columns=HBASE_ROW_KEY,info:username,info:age,info:address \ stutsv \ hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/stu.tsv
运行结果:
hbase(main):004:0> scan 'stutsv' ROW COLUMN+CELL 0001 column=info:address, timestamp=1605020174889, value=city-1 0001 column=info:age, timestamp=1605020174889, value=20 0001 column=info:username, timestamp=1605020174889, value=henry 0002 column=info:address, timestamp=1605020174889, value=city-2 0002 column=info:age, timestamp=1605020174889, value=30 0002 column=info:username, timestamp=1605020174889, value=cherry 0003 column=info:address, timestamp=1605020174889, value=city-3 0003 column=info:age, timestamp=1605020174889, value=29 0003 column=info:username, timestamp=1605020174889, value=alex
(2)通过importtsv命令+completebulkload
importtsv -Dimporttsv.bulk.output=/path/for/output
通过此命令,我们可以将外部的数据文件直接生成一个HFfile文件,然后通过completebulkload直接加载到HBase数据表中
执行流程:
log文件 -> HFfile文件 ->HBase table表中
第一步:
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.9.3.jar \ importtsv \ -Dimporttsv.columns=HBASE_ROW_KEY,info:username,info:age,info:address \ -Dimporttsv.bulk.output=hdfs://bigdata-pro-m01:9000/user/caizhengjie/hfoutput \ stutsv \ hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/stu.tsv
这时在HDFS上会生成HFfile文件,会放在hfoutput里面
第二步:
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.9.3.jar completebulkload \ hdfs://bigdata-pro-m01:9000/user/caizhengjie/hfoutput \ stutsv
这时HDFS上的HFfile文件会写入到HBase中
运行结果:
hbase(main):003:0> scan 'stutsv' ROW COLUMN+CELL 0001 column=info:address, timestamp=1605091109579, value=city-1 0001 column=info:age, timestamp=1605091109579, value=20 0001 column=info:username, timestamp=1605091109579, value=henry 0002 column=info:address, timestamp=1605091109579, value=city-2 0002 column=info:age, timestamp=1605091109579, value=30 0002 column=info:username, timestamp=1605091109579, value=cherry 0003 column=info:address, timestamp=1605091109579, value=city-3 0003 column=info:age, timestamp=1605091109579, value=29 0003 column=info:username, timestamp=1605091109579, value=alex 3 row(s) in 0.1060 seconds
(3)不同文件中数据分割符的处理
在实际业务中,我们的数据不可能都是tab键分割开来的,也会出现csv格式的文件,那么我们会根据不同的业务场景,对不同文件中数据分割符做处理。
'-Dimporttsv.separator=|'
准备数据:按照逗号分隔的数据
0001,henry,20,city-1 0002,cherry,30,city-2 0003,alex,28,city-3 0004,lili,35,city-4 0005,jack,18,city-5
将数据上传到HDFS
bin/hdfs dfs -put /opt/datas/stu.csv /user/caizhengjie/datas
第一步:生成HFfile文件
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.9.3.jar \ importtsv \ -Dimporttsv.columns=HBASE_ROW_KEY,info:username,info:age,info:address \ -Dimporttsv.bulk.output=hdfs://bigdata-pro-m01:9000/user/caizhengjie/hfcsv \ -Dimporttsv.separator=, \ stutsv \ hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/stu.csv
HFfile文件会放在HDFS的/user/caizhengjie/hfcsv目录下
第二步:加载数据,将HFfile文件写入到HBase中
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.9.3.jar completebulkload \ hdfs://bigdata-pro-m01:9000/user/caizhengjie/hfcsv \ stutsv
运行结果:
hbase(main):007:0> scan 'stutsv' ROW COLUMN+CELL 0001 column=info:address, timestamp=1605096866374, value=city-1 0001 column=info:age, timestamp=1605096866374, value=20 0001 column=info:username, timestamp=1605096866374, value=henry 0002 column=info:address, timestamp=1605096866374, value=city-2 0002 column=info:age, timestamp=1605096866374, value=30 0002 column=info:username, timestamp=1605096866374, value=cherry 0003 column=info:address, timestamp=1605096866374, value=city-3 0003 column=info:age, timestamp=1605096866374, value=28 0003 column=info:username, timestamp=1605096866374, value=alex 0004 column=info:address, timestamp=1605096866374, value=city-4 0004 column=info:age, timestamp=1605096866374, value=35 0004 column=info:username, timestamp=1605096866374, value=lili 0005 column=info:address, timestamp=1605096866374, value=city-5 0005 column=info:age, timestamp=1605096866374, value=18 0005 column=info:username, timestamp=1605096866374, value=jack
(4)自定义MR程序生成HFfile文件(企业常用的方案)
第一步:编写MR数据迁移程序
log文件 -> HFfile文件
package com.kfk.hbase; /** * @author : 蔡政洁 * @email :caizhengjie888@icloud.com * @date : 2020/11/10 * @time : 3:31 下午 */ public class HBaseConstant { public static String HBASE_TABLE = "stu"; public static String HBASE_CF_INFO = "info"; }
package com.kfk.hbase; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.*; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @author : 蔡政洁 * @email :caizhengjie888@icloud.com * @date : 2020/10/9 * @time : 7:07 下午 */ public class HBaseMRHF extends Configured implements Tool { /** * map * TODO */ public static class MyMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put>{ // rowkey,username,age,addres // 0001,henry,20,city-1 String[] COLUMN = new String[]{ "rowkey","username","age","addres" }; // ImmutableBytesWritable为KEYOUT输出的Key的类型, Put为VALUEOUT输出的Value的类型 ImmutableBytesWritable rowkey = new ImmutableBytesWritable(); @Override public void map(LongWritable key, Text lines, Context context) throws IOException, InterruptedException { // 将每一行数据按逗号分开,放入数组中 String[] values = lines.toString().split(","); // set rowkey rowkey.set(Bytes.toBytes(values[0])); Put put = new Put(rowkey.get()); for (int index = 1;index < values.length;index++){ put.addImmutable(Bytes.toBytes(HBaseConstant.HBASE_CF_INFO),Bytes.toBytes(COLUMN[index]),Bytes.toBytes(values[index])); } context.write(rowkey,put); } } /** * run * @param args * @return * @throws IOException * @throws ClassNotFoundException * @throws InterruptedException */ public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1) get conf Configuration configuration = this.getConf(); // 2) create job Job job = Job.getInstance(configuration,this.getClass().getSimpleName()); job.setJarByClass(this.getClass()); // 3.1) input,指定job的输入 Path path = new Path(args[0]); FileInputFormat.addInputPath(job,path); // 3.2) map,指定job的mapper和输出的类型 job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); // 3.4) output,指定job的输出 Path outpath = new Path(args[1]); FileOutputFormat.setOutputPath(job,outpath); TableName tableName = TableName.valueOf("stu"); // 创建一个链接 Connection connection = ConnectionFactory.createConnection(); // 获取数据表 Table table = connection.getTable(tableName); RegionLocator regionLocator = connection.getRegionLocator(tableName); HFileOutputFormat2.configureIncrementalLoad(job,table,regionLocator); // 4) commit,执行job boolean isSuccess = job.waitForCompletion(true); // 如果正常执行返回0,否则返回1 return (isSuccess) ? 0 : 1; } public static void main(String[] args) { // 添加输入,输入参数 // args = new String[]{ // "hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/stu.csv", // "hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/hfcsv-output" // }; Configuration configuration = HBaseConfiguration.create(); try { // 判断输出的文件存不存在,如果存在就将它删除 Path fileOutPath = new Path(args[1]); FileSystem fileSystem = FileSystem.get(configuration); if (fileSystem.exists(fileOutPath)){ fileSystem.delete(fileOutPath,true); } // 调用run方法 int status = ToolRunner.run(configuration,new HBaseMRHF(),args); // 退出程序 System.exit(status); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } } }
打包并上传至服务器
第二步:生成HFfile文件
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar /opt/jars/hbase_mrhf.jar \ hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/stu.csv hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/hfcsv-output
第三步:加载数据,将HFfile文件写入到HBase中
export HADOOP_HOME=/opt/modules/hadoop export HBASE_HOME=/opt/modules/hbase HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \ ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-1.2.0-cdh5.9.3.jar completebulkload \ hdfs://bigdata-pro-m01:9000/user/caizhengjie/datas/hfcsv-output \ stutsv
运行结果:
hbase(main):007:0> scan 'stutsv' ROW COLUMN+CELL 0001 column=info:addres, timestamp=1605149649495, value=city-1 0001 column=info:age, timestamp=1605149649495, value=20 0001 column=info:username, timestamp=1605149649495, value=henry 0002 column=info:addres, timestamp=1605149649495, value=city-2 0002 column=info:age, timestamp=1605149649495, value=30 0002 column=info:username, timestamp=1605149649495, value=cherry 0003 column=info:addres, timestamp=1605149649495, value=city-3 0003 column=info:age, timestamp=1605149649495, value=28 0003 column=info:username, timestamp=1605149649495, value=alex 0004 column=info:addres, timestamp=1605149649495, value=city-4 0004 column=info:age, timestamp=1605149649495, value=35 0004 column=info:username, timestamp=1605149649495, value=lili 0005 column=info:addres, timestamp=1605149649495, value=city-5 0005 column=info:age, timestamp=1605149649495, value=18 0005 column=info:username, timestamp=1605149649495, value=jack 5 row(s) in 0.3760 seconds