《MySQL死锁分析的两个工具》中,举了一个强制类型转换导致死锁的例子,有朋友询问是不是类型转换都不能命中索引,花1分钟细说一下。
第一类:“列类型”与“where值类型”不符,不能命中索引,会导致全表扫描(full table scan)。
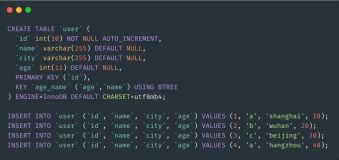
数据准备:
create table t1 (
cell varchar(3) primary key
)engine=innodb default charset=utf8;
insert into t1(cell) values ('111'),('222'),('333');
(1)cell属性为varchar类型;
(2)cell为主键,即聚簇索引(clustered index);
(3)t1插入3条测试数据;
测试语句:
explain select from t1 where cell=111;
explain select from t1 where cell='111';
(1)第一个语句,where后的值类型是整数(与表cell类型不符);
(2)第二个语句,where后的值类型是字符串(与表cell类型一致);
测试结果:
(1)强制类型转换,不能命中索引,需要全表扫描,即3条记录;
(2)类型相同,命中索引,1条记录;
第二类:相join的两个表的字符编码不同,不能命中索引,会导致笛卡尔积的循环计算(nested loop)。
数据准备:
create table t2 (
cell varchar(3) primary key
)engine=innodb default charset=latin1;
insert into t2(cell) values ('111'),('222'),('333'),('444'),('555'),('666');
create table t3 (
cell varchar(3) primary key
)engine=innodb default charset=utf8;
insert into t3(cell) values ('111'),('222'),('333'),('444'),('555'),('666');
(1)t2和t1字符集不同,插入6条测试数据;
(2)t3和t1字符集相同,也插入6条测试数据;
(3)除此之外,t1,t2,t3表结构完全相同;
测试语句:
explain select from t1,t2 where t1.cell=t2.cell;
explain select from t1,t3 where t1.cell=t3.cell;
(1)第一个join,连表t1和t2(字符集不同),关联属性是cell;
(2)第一个join,连表t1和t3(字符集相同),关联属性是cell;
测试结果
(1)t1和t2字符集不同,存储空间不同;
(2)t1和t2相join时,遍历了t1的所有记录3条,t1的每一条记录又要遍历t2的所有记录6条,实际进行了笛卡尔积循环计算(nested loop),索引无效;
(3)t1和t3相join时,遍历了t1的所有记录3条,t1的每一条记录使用t3索引,即扫描1行记录;
画外音:图片请放大。
总结
两类隐蔽的不能利用索引的case:
(1)表列类型,与where值类型,不一致;
(2)join表的字符编码不同;
画外音:本文测试于MySQL5.6。作业
create table t1 (
cell varchar(3) primary key
)engine=innodb default charset=utf8;
insert into t1(cell) values ('111'),('222'),('333');
create table t2 (
cell char(3) primary key
)engine=innodb default charset=utf8;
insert into t2(cell) values ('111'),('222'),('333'),('444'),('555'),('666');
create table t3 (
cell int primary key
)engine=innodb default charset=utf8;
insert into t3(cell) values (111),(222),(333),(444),(555),(666);
(1)t1, t2, t3的cell类型不同:分别是varchar(3), char(3), int;
(2)编码类型相同,均为utf8;
请问:t1与t2,t1与t3的join查询,能命中索引吗?
explain select from t1,t2 where t1.cell=t2.cell;
explain select from t1,t3 where t1.cell=t3.cell;
动动手,“实际结果”与“你以为的”,未必相同。
希望这1分钟大家有收获,有思考,求帮转。
本文转自“架构师之路”公众号,58沈剑提供。