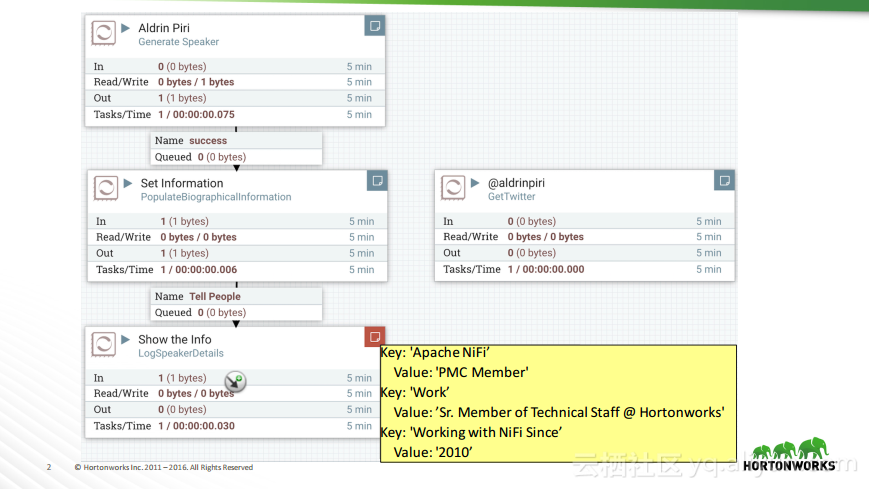
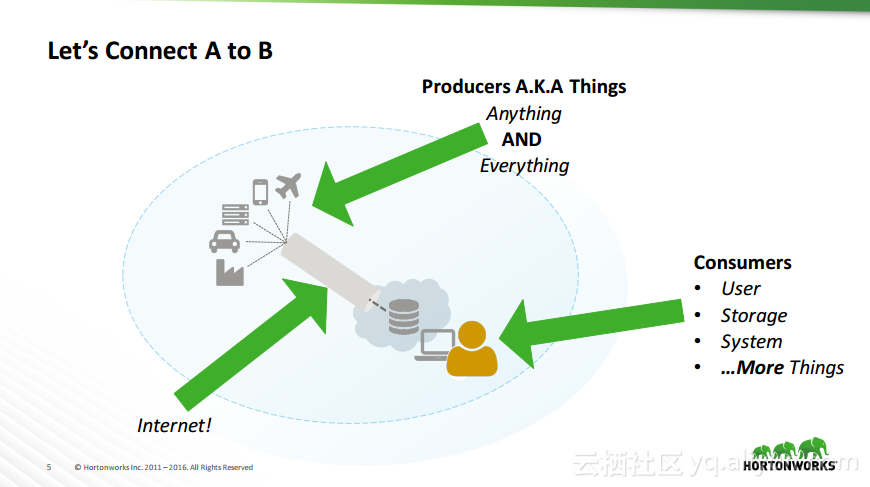
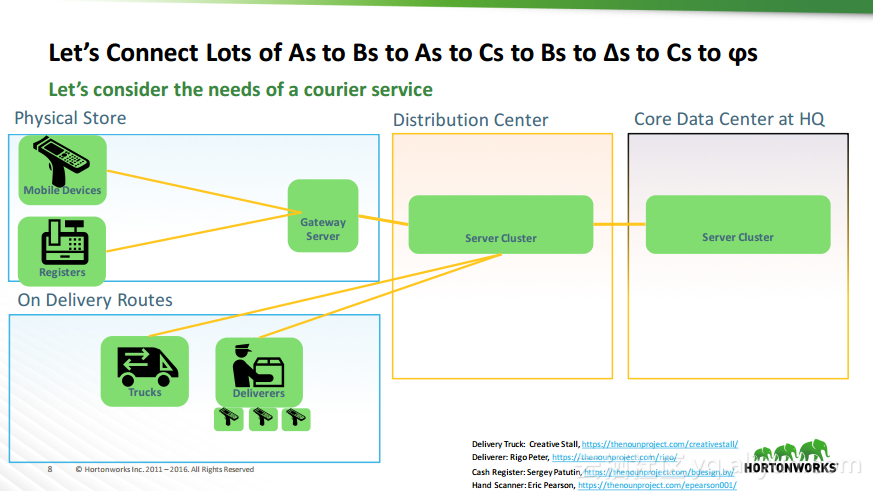
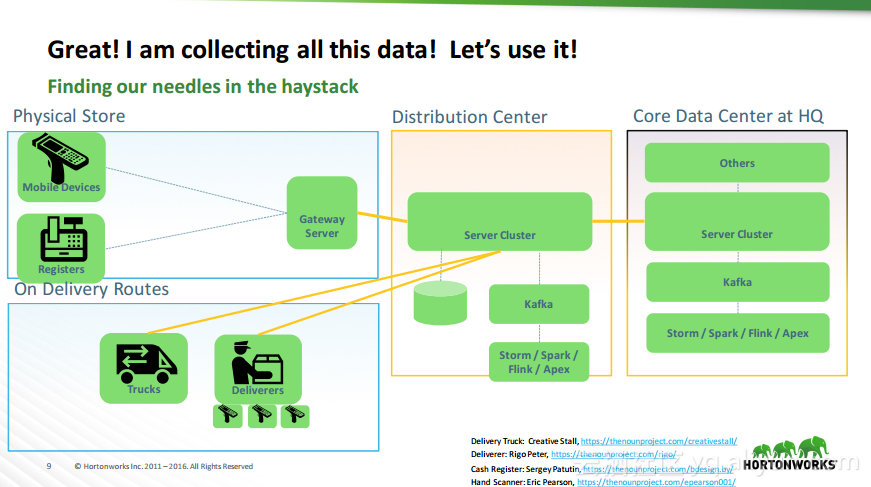
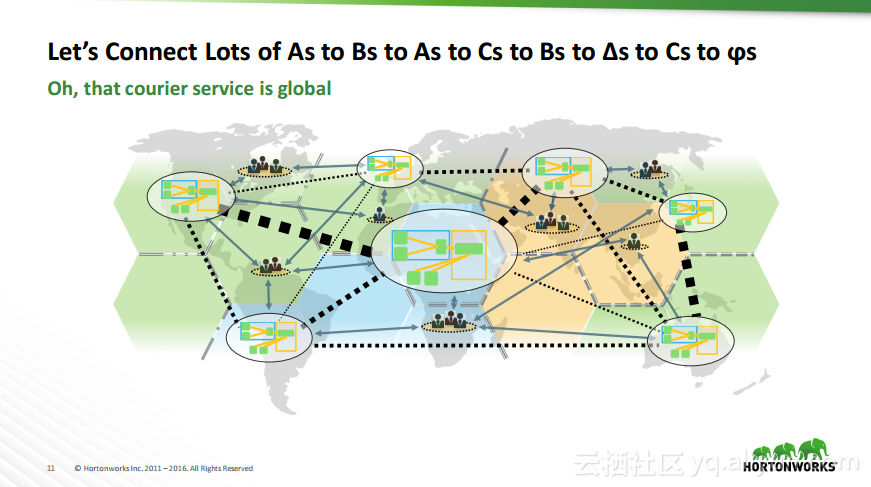
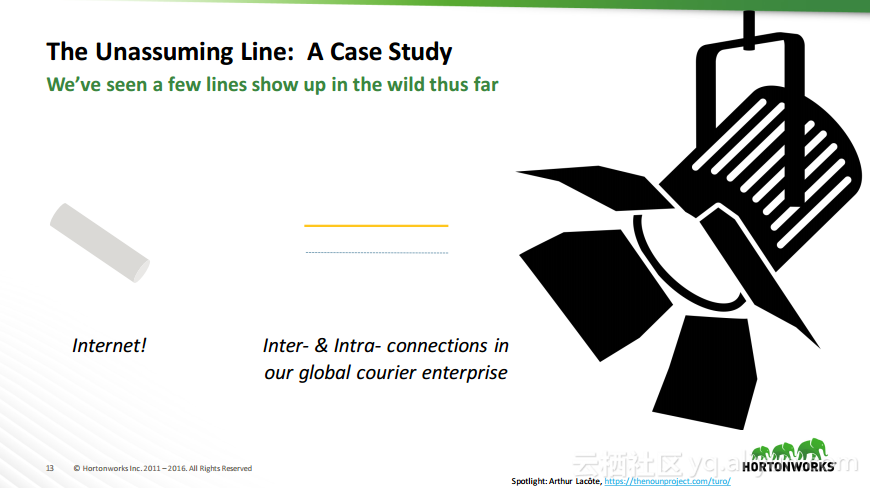
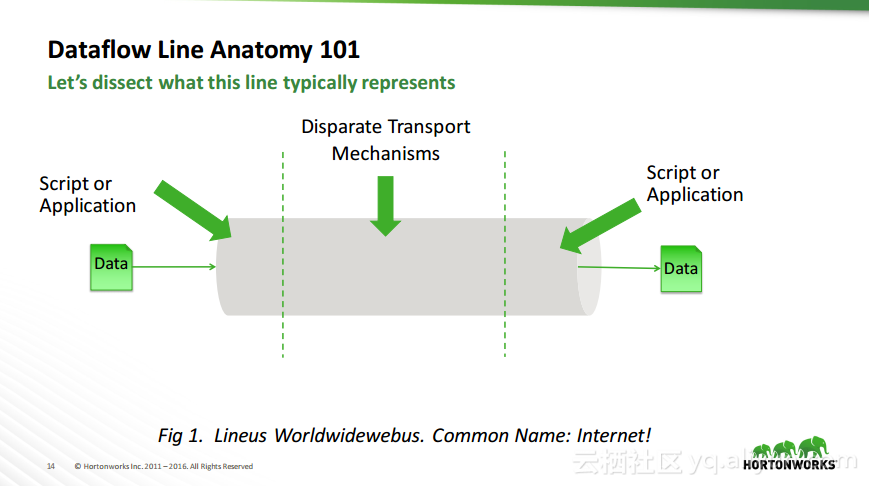
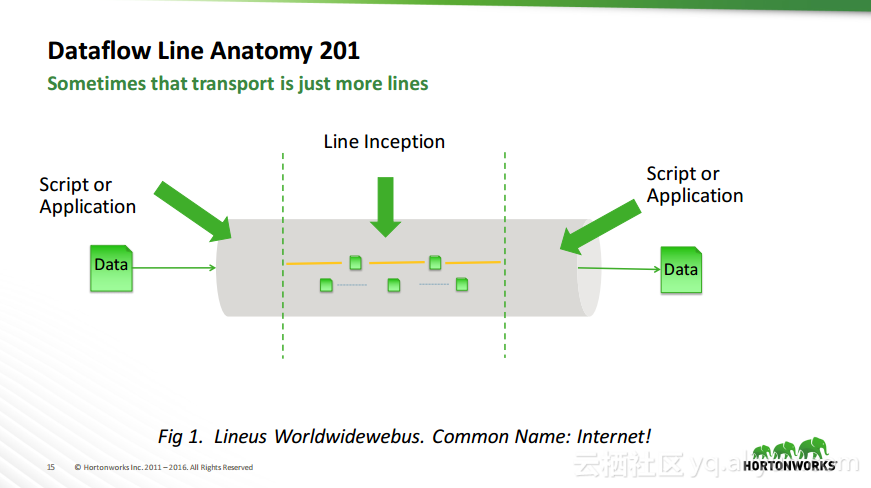
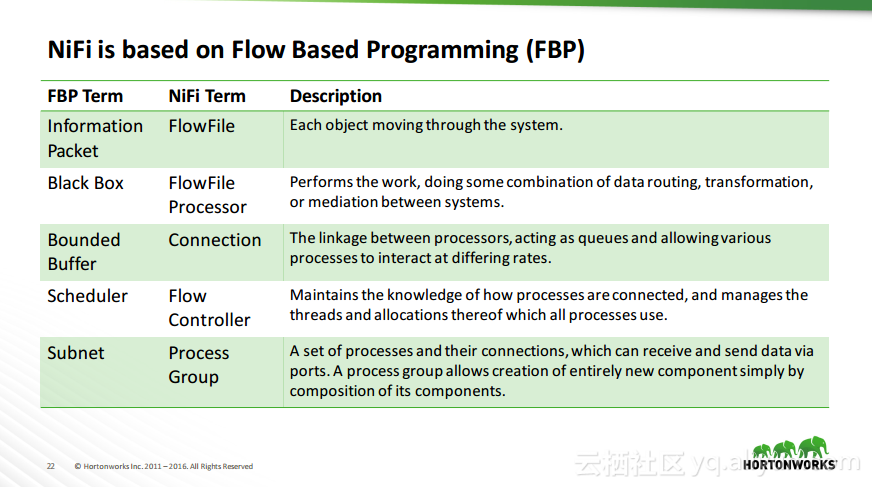
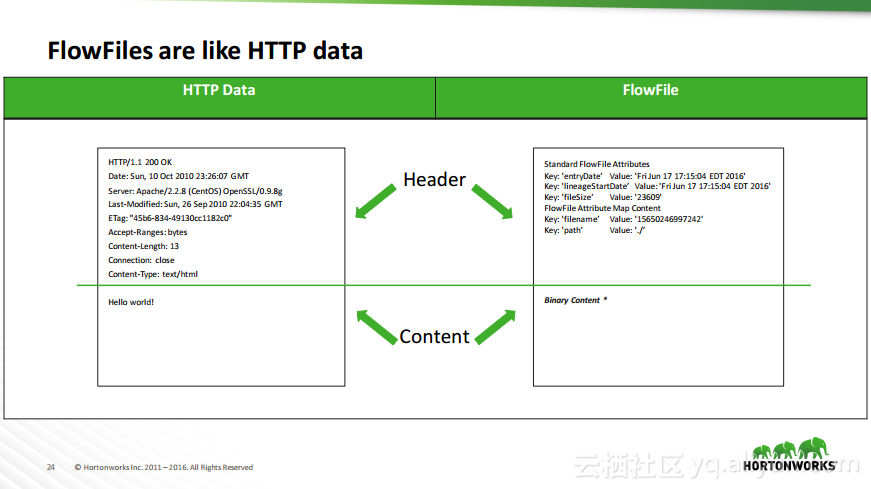
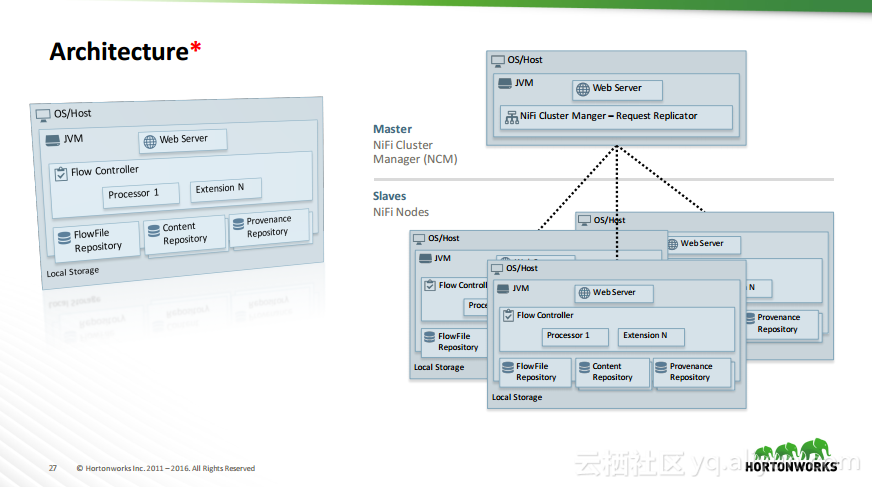
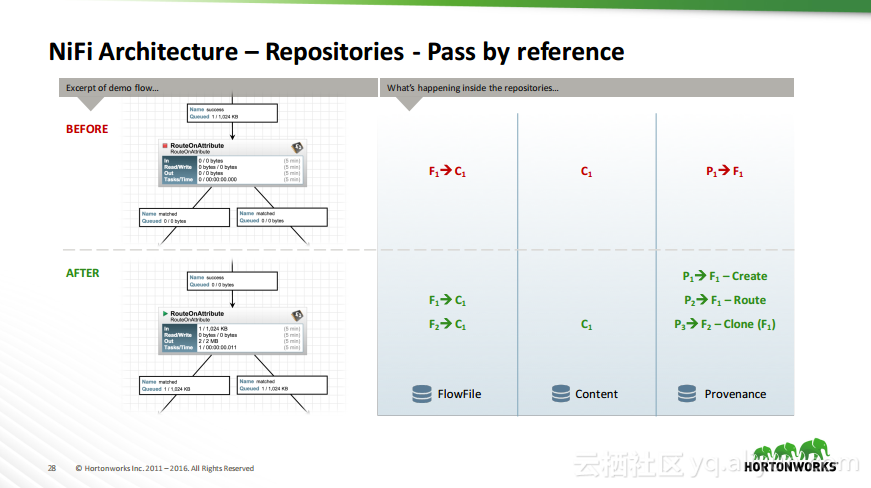
热门
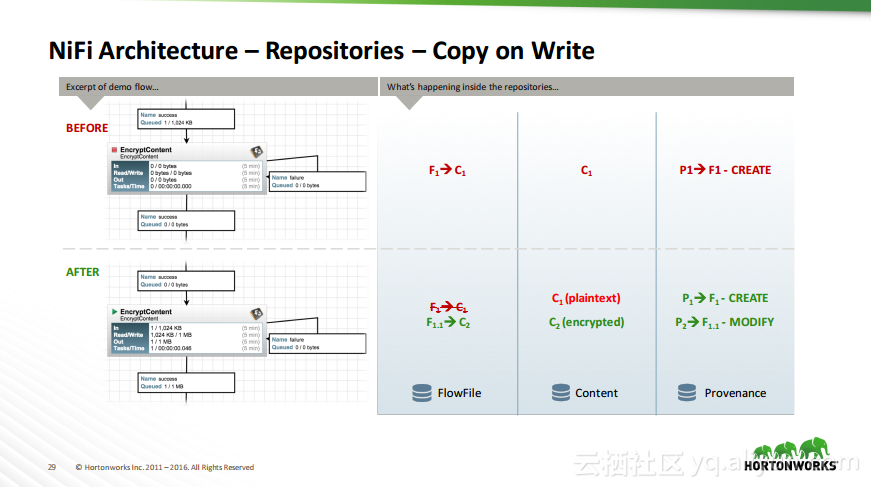
本讲义出自Aldrin Piri在Hadoop Summit Tokyo 2016上的演讲,主要介绍了什么是数据流以及当前数据流在研发中面临的挑战,并介绍了Apache NiFi的基本概念以及其架构设计。