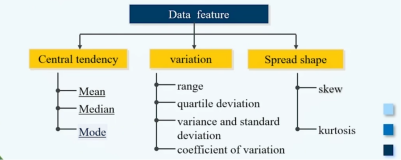
[I]The Central Dogma of Gene Expression

[II]Second Generation Sequencing Principle of illumina
1.sample prep
All preparation methods add adapters to the ends of the DNA fragments.Through reduced cycle amplification,additional motifs are introduced.Such as the sequencing binding site,indices and regions complementary to the flow cell oligos.
2.cluster generation
Clustering is a process where each fragment molecule is isothermally amplified.The flow cell is a glass slide with lanes.Each lane is a channel coated with a lawn,composed of two types of oligos.Hybridization is enable by the first of the two types of oligos on the surface.This oligos is complementary to the adapter region on one of the fragment strands.A polymerase creates a complement of the hybridized fragment.The double stranded molecule is denatured and the original template is washed away.The strands are clonally amplified through bridge amplification.In this process the strand folds over and the adapter region hybridizes to the second type of oligo on the flow cell.Polymerases generate the complementary strand forming a double stranded bridge .This bridge is denatured resulting in 2 single-stranded copies of the molecule that are tethered to the flow cell.The process is then repeated over and over,and occurs simultaneously for millions of clusters resulting in clonal amplification of all the fragments.After bridge amplification the reverse strands are cleaved and washed off,leaving only the forward strands.The three prime ends are blocked to prevent unwanted priming.
3.sequencing
Sequencing begins with the extension of the first sequencing primer to produce the first read.With each cycle,fluorescently tagged nucleotides compete for addition to the growing chain.Only one is incorporated based on the sequence of the template.After the addition of each nucleotide the clusters are excited by a light source and a characteristic fluorescent signal is emitted.Sequencing-by-Synthesis.The number of cycles determines the length of the read.The emission wave length,along with the signal intensity,determines the base call.For a given cluster,all identical strands are read simultaneously.Hundreds of millions of clusters are sequenced in a massively parallel process.After the completion of the first read.,the read product is washed away.In this step the index/read primer is introduced and hybridized to the template.The read is generated,similar to the first read.After completion of the index read,the read product is washed off,and the three prime ends of the template are deprotected .
The template how folds over and binds the second oligo on the flow cell?Index 2 is read in the same manner as index1.Polymerases extend the second flow cell oligo forming a double stranded bridge.This double stranded DNAis then linearized and the three prime ends are blocked.The original forward strand is cleaved off and washed away leaving only the reverse strand.
Read 2 begins with the introduction of the read 2 sequencing primer.As with read1,the sequencing steps are repeated until the desired read length is achieved.Thet read 2 product is then washed away.This entire process generates millions of reads representing all the fragments.
4.data analysis
Sequences from pooled sample libraries are separated preparation.For each sample,reads with similar stretches of base calls are aligned back to the reference genome for variant identification.The paired and information is used to resolve ambiguous alignments.Genomic data can be securely transferred,stored,analyzed and shared in base base sequence hub.Discover the possibilities of next-generation sequencing.
[III]Software
- comparison software
BWA-MEN - reads software
htseq-count
[IV]Normalize
- log2
- p-value
- q-value
- TPM
- FPKM
- RPKW
[V]Differential Gene
[VI]Evaluation
TP=True Positive:actual is positive;forecast is positive;
TN=True Negative:actual is positive;forecast is negative;
FP=False Positive:actual is negative;forecast is positive;
FN=False Negative:actual is negative.forecast is negative;
$$ accuracy=\frac{TP+TN}{TP+TN+FP+FN} $$
$$ error rate=\frac{FP+FN}{TP+TN+FP+FN}=1-accuracy $$
$$ sensitive=\frac{TP}{P} $$
$$ specificity=\frac{TN}{N} $$
$$ precision=\frac{TP}{TP+FP} $$
$$ recall=\frac{TP}{TP+FN}=\frac{TP}{P}=sensitive $$
$$ f-measure=\frac{({\alpha}^2+1)*p*r}{{\alpha}^2*(p+r)}(\alpha=1) $$
END!