本期分享专家:田杰,专注在关系型数据库和NoSQL数据库技术领域,曾先后就职于路透社和渣打银行,目前在阿里云从事数据库技术支持工作,号称“数据库问题的终结者”。

在帮客户排查问题的时候,经常会遇到的 RDS 实例性能问题(比如 RDS 实例 CPU 使用率高),而其中有一类是由于字符集的字符排序规则不一致导致的。从处理的过程中可以看出来,这类问题比较容易出现但不容易定位排查,所以今天通过两个实战案例来分析的下“RDS for MySQL 字符序(collation)引发的性能问题”。
首先介绍下背景知识: 字符集 和 字符序。
1. 字符集(characte1 set)和字符序(collation)
字符集是一组符号和编码,用来保存和解释 MySQL 的字符类型数据,比如 varchar 类型的数据。
字符序是一组在指定字符集中进行字符比较的规则,比如是否忽略大小写,是否按二进制比较字符等等。
2. 字符序基本比较规则
两组字符类型数据进行比较,需要一致的字符集(character set)和 字符序(collation),否则需要进行隐式转换。
3. 实战案例分析
- 案例分析一:实例 CPU 使用率达到 100%,业务响应时间长,影响使用体验。

问题原因定位到一条普通查询语句:
select
aid, ip, adid, openudid
from
`tab01`
where
`reg_time` between '2016-10-12 00:00:00' and '2016-10-12 23:59:59'该语句在上线前通过 MySQL 命令行进行过测试,执行时间在 20 MS(毫秒)左右。
但在生产环境由 PHP Lavravel 框架提交执行需要 20 Sec(秒)以上才可以完成; 大量该类型查询执行导致连接堆积,RDS 实例 CPU 使用率 100%。
首先在 MySQL 命令行下,检查表结构:
CREATE TABLE `tab01` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`reg_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`ip` char(15) NOT NULL,
`aid` bigint(20) NOT NULL,
`adid` varchar(255) NOT NULL,
`openudid` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `reg_time` (`reg_time`),
KEY `aid` (`aid`),
KEY `adid` (`adid`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11964136 DEFAULT CHARSET=utf8检查执行计划,未见异常:
请用户协助捕捉 PHP Laravel 框架提交查询的网络通信过程:

在网络交互过程中,发现应用在连接建立后执行了下面的语句,然后间隔部分其他查询后才执行的上述查询:
set names utf8 collate utf8_unicode_ci;那么这条命令具体修改了什么,可以通过 MySQL 命令行连接来模拟验证下 :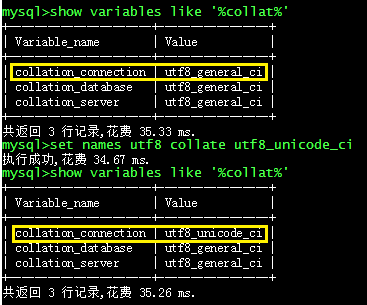
可以看到,该条命令将连接的字符序(collation_connection)从 utf8_general_ci (默认值)修改为 utf8_unicode_ci ;而表中数据使用的是默认字符序(utf8_general_ci,在表的 create 定义语句中如果没有指定,则使用字符集的默认字符序),两者并不相同。
注:
RDS for MySQL 支持的字符序可以通过下面的命令获取:
-- 查看 RDS for MySQL 支持的所有字符序
show collation;
-- 查看 RDS for MySQL 支持的某一字符集对应的字符序
show collation like 'utf8%'; 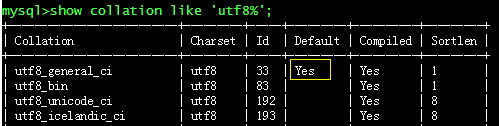
在修改了字符序后,语句的执行计划就变为全索引扫描:
请注意查询的执行成本由 8427 改变为 13771569,增加了 1633 倍。
修改框架的字符序设置后,查询执行时间恢复正常,RDS 实例 CPU 使用率过高的问题解决。
案例分析二:RDS 实例 CPU 使用率波动性打高,导致业务卡顿。

定位到下面的查询,检查语句执行计划,发现优化器对表 tab03 选择了全表扫描的方式来访问数据。
explain
SELECT
r.org_no,
r.cp_no,
r.NAME cp_name
FROM
tab02 r
LEFT JOIN tab03 a ON r.cp_no = a.cp_no
AND A.SHARD_NO = r.shard_no
WHERE
r.shard_no = '41401'
AND r.org_no LIKE '41401%'
limit 100;
+----+-------------+-------+------+---------------------------------------------+-------------------------+---------+-------+-------+------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------------------------------------+-------------------------+---------+-------+-------+------------------------------------------------+
| 1 | SIMPLE | r | ref | auto_shard_key_shard_no | auto_shard_key_shard_no | 99 | const | 30637 | Using index condition; Using where |
| 1 | SIMPLE | a | ALL | R_CP_TAB03_UK,auto_shard_key_shard_no | | | | 13221 | Range checked for each record (index map: 0xA) |
+----+-------------+-------+------+---------------------------------------------+-------------------------+---------+-------+-------+------------------------------------------------+
共返回 2 行记录,花费 2.23 ms.而表 tab03 上有合适的唯一索引 R_CP_TAB03_UK:
CREATE TABLE `tab03` (
`TERMINAL_ID` bigint(16) NOT NULL,
`CP_NO` varchar(16) NOT NULL,
`CP_NAME` varchar(256) DEFAULT NULL,
`DATA_SRC` varchar(8) DEFAULT NULL,
`IS_DIRECT` varchar(8) DEFAULT NULL,
`SHARD_NO` varchar(32) DEFAULT NULL,
PRIMARY KEY (`TERMINAL_ID`),
UNIQUE KEY `R_CP_TAB03_UK` (`CP_NO`),
KEY `auto_shard_key_shard_no` (`SHARD_NO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8而且 Extra 字段给出的是 Range checked for each record(index map:0xA),说明存在潜在可以使用的索引,但由于某种原因无法使用。
查看表 tab02 的定义:
CREATE TABLE `tab02` (
`cp_no` varchar(32)CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`name` varchar(512)CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`data_src` varchar(16)CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`shard_no` varchar(32) DEFAULT NULL,
PRIMARY KEY (`cp_no`),
KEY `auto_shard_key_shard_no` (`shard_no`),
KEY `INDX_TAB02_NAME` (`name` (255))
) ENGINE=InnoDB DEFAULT CHARSET=utf8表 tab02 的 cp_no 字段采用 utf8_bin(按二进制比较,不忽略大小写) 字符序,而表 tab03 的 cp_no 字段采用 utf8_general_ci(默认)字符序,两者字符序不匹配,因此无法使用正确的索引。
修改表 tab03 的 cp_no 字段字符序为 utf8_bin,执行计划恢复正常,RDS 实例 CPU 波动性打高的问题解决。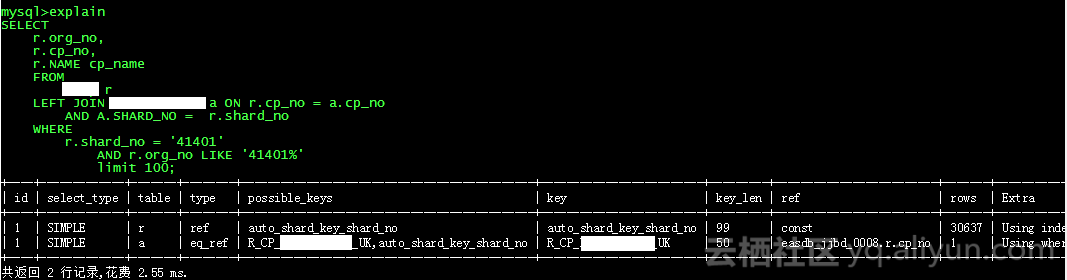
从以上的案例可以看到,正确的执行计划相较调整前的执行计划效率大约提升了 13221 倍。字符序不仅仅可以导致 CPU 使用率问题,也可能引入比如 IOPS 使用率高 等其他问题。因此建议应用开发保持统一的字符集和字符序使用规范,避免规范不统一引入性能问题。
本期分享就到这里了,欢迎大家留言讨论有关的数据库的问题,我们年后再见,在此祝大家新年快乐,鸡年大吉!

